
整合多个生成基础模型,特别是那些在不同模态上训练的模型,是一项具有挑战性的任务。主要困难在于:一是对齐数据的可用性,即在不同模态下表达相似意义的概念;二是在跨领域生成任务中有效利用单模态表示,而不损害其原有的单模态能力。作者提出了Zipper,一种多塔解码器架构,通过使用交叉注意力,将独立预训练的单模态解码器灵活组合成多模态生成模型。在作者的实验中,Zipper在有限的文本-语音对齐数据情况下表现出竞争力。同时,Zipper可以通过冻结相应的模态塔,选择性地保持单模态生成性能。在跨模态任务(如自动语音识别)中,冻结文本骨干网络几乎不会导致模型性能下降;在跨模态任务(如文本转语音)中,使用预训练的语音骨干网络的表现优于基线。
题目:Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities
作者:Vicky Zayats, Peter Chen, Melissa Ferrari, Dirk Padfield (Google Deepmind)
文章地址:https://arxiv.org/abs/2405.18669
内容整理:张俸玺
引言
仅解码器的生成模型在文本、蛋白质、音频、图像和状态序列等多种模态中已经展示了它们能够通过下一个Token预测生成有用的表示,并成功生成新序列。然而,由于世界本质上是多模态的,最近的研究尝试创建能够同时在多个模态中生成输出的多模态模型。这通常通过在预训练或后续微调阶段进行某种形式的词汇扩展(将多模态表示转换为离散标记并将其添加到模型的基本词汇表中)来实现。虽然多模态预训练具有强大的性能优势,但也存在一些问题,如添加新模态后需要从头训练新的模型,并进行超参数搜索,以确定各模态之间的最佳训练数据比例,这使得这种解决方案不适合较小的模态。另一种方法是在预训练后进行词汇扩展,将未见过该模态的模型微调到该模态,但这会破坏原有模型的强大能力,仅能执行微调后的跨模态任务。
为了解决这些问题,作者提出了Zipper,这是一种旨在模块化的架构,通过交叉注意力将多种单模态预训练的解码器组合在一起。这样可以利用丰富的无监督单模态数据进行预训练,然后使用有限的跨模态数据进行微调,从而实现多模态生成能力。预训练的单模态解码器可以灵活地重新使用和重新组合,确保在保留单模态性能的同时实现多模态生成。
作为概念验证,作者专注于融合语音和文本模态,展示了Zipper在自动语音识别和文本转语音任务中的强大能力。文中的实验表明,Zipper在仅使用一小部分对齐数据的情况下,能够学习有意义的表示,表现出其在数据受限的生成任务中的潜力。
本文的主要贡献有三:
- 本文提出了一种新的生成多模态融合架构,该架构将预训练的单模态骨干网络结合在一起。与词汇扩展技术类似,本文提出的架构可以在所有模态上执行生成任务。与词汇扩展技术不同,提出的架构更灵活和可组合,允许单模态骨干网络独立于多模态对齐微调进行预训练,同时通过冻结相应的骨干网络来保留任何单模态性能(例如,确保文本到文本生成的性能不降低)。
- 基于语音和文本模态的实证结果,作者展示了本架构在冻结模态骨干网络(例如文本)上,在基于文本的生成任务(如ASR)中表现出与词汇扩展基线相比具有竞争力的性能。此外,还展示了在语音生成的TTS任务中,与词汇扩展基线相比,本架构在未冻结模态骨干网络(例如语音)上的词错误率(WER)绝对降低了12个百分点(相对错误率降低了40%)。作者将这一改进归因于作者改进的交叉注意力在长上下文生成中的更好对齐能力以及从强预训练的单模态语音骨干网络微调作为基础。
- 消融实验表明,使用Zipper组合单模态预训练模型能够在只有少量对齐数据(少至1%或不到3000个语音片段)的情况下学习有意义的表示,这归功于每个骨干网络的强预训练。
模型
Zipper架构由两个自回归解码器塔(或骨干网络)组成,这两个塔通过门控交叉注意力层“拉链”在一起。每个骨干网络分别在单一模态上使用下一个标记预测进行训练。图1显示了Zipper架构的概述。与CALM类似,交叉注意力被插入到解码器骨干网络之间的每第i层。在这些定期交错的层中,一个模态的表示被交叉注意力引入到另一个模态中。这与Flamingo的编码器-解码器设置不同,后者仅在一个塔(编码器)的最终层在规则间隔内交叉引入到另一个塔(解码器)的层中。
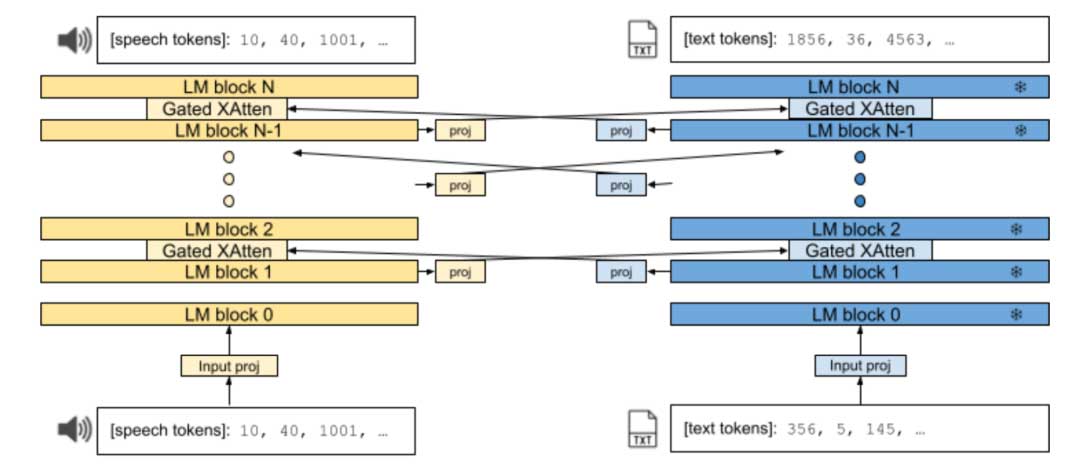
在交叉注意力过程中,在模态之间插入投影层。从功能上讲,这使得骨干网络之间的嵌入维度大小差异得以平衡。从语义上讲,它还能够将一个模态的表示转换为另一个模态的表示,特别是在一个或两个骨干网络被冻结时。此外,在每个骨干网络的输入嵌入之后直接加入一个非线性输入投影层,以便更好地调整输入的单模态表示,以适应多模态任务。
设两个自回归Transformer解码器为A和B。在第一个Transformer块之前(嵌入层之后),作者为每个骨干网络插入两个可学习的多层感知器(MLP)投影,然后进行ReLU变换:
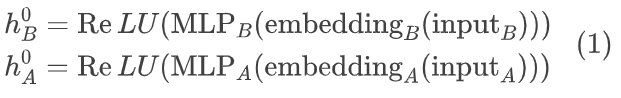
这样可以在实际的Transformer处理之前对嵌入进行调整和转换,以更好地适应后续的多模态任务。

最后,每个塔以一个softmax层结束(与同塔嵌入层共享),以便通过下一个标记预测任务将隐藏表示投影到(模态/塔特定的)标记词汇表的概率分布中。
自回归掩码
作者调整了交叉注意力机制以适应交错序列上的自回归训练。这是通过仅对原始线性序列中当前位置之前的其他模态数据进行交叉注意来实现的。
推理
在解码过程中,指定输出模态的顺序(例如,[语音],[文本],[文本,语音])。模型在序列中的第一个模态中生成输出,直到遇到特殊的句末标记,此时生成切换到序列中的下一个模态。这个过程持续进行,直到序列中的所有模态都被解码完毕。尽管可以扩展模型以自动选择生成输出的模态,但作者将这种设置的泛化留作未来的工作。
实验
虽然Zipper可以扩展到任意数量的模态,但本文报告的所有实验都集中在文本和语音模态的融合上。具体而言,作者评估了语音到文本生成的自动语音识别(ASR)和文本到语音生成(TTS)。
实验设置
实验聚焦于融合语音和文本模态。使用PaLM2的不同规模版本作为文本骨干网络,语音骨干网络则基于类似的解码器架构。数据集包括LibriLight(用于语音预训练),LibriSpeech和LibriTTS(用于ASR和TTS任务)。
基线模型
使用扩展词汇表的单塔解码器(Single Decoder)作为基线模型,该模型将语音标记添加到预训练的文本模型中进行微调。实验在相同的ASR和TTS任务上进行比较。
自动语音识别(ASR)
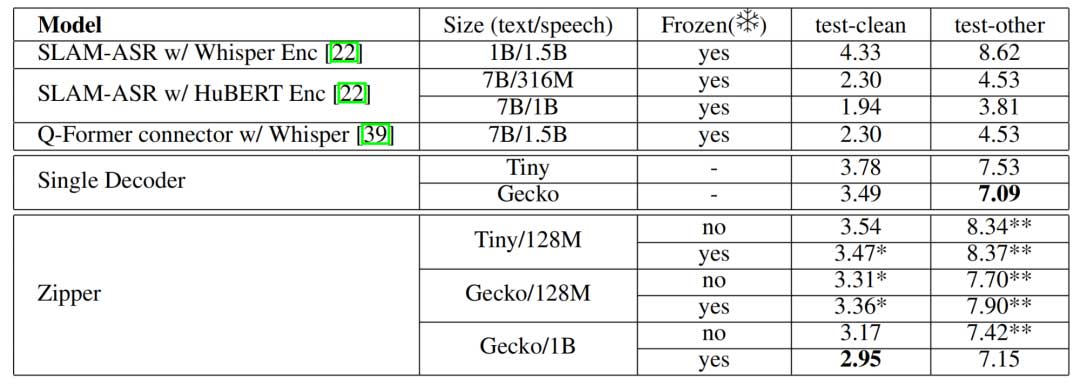
比较了Zipper模型和基线模型在LibriSpeech数据集上的ASR性能。结果显示,Zipper模型在较干净的测试数据集上略有优势,而在噪声较大的数据集上表现相当。冻结语音骨干网络对性能影响不大,说明Zipper模型能在保持文本生成能力的同时实现良好的跨模态生成。
文本转语音(TTS)
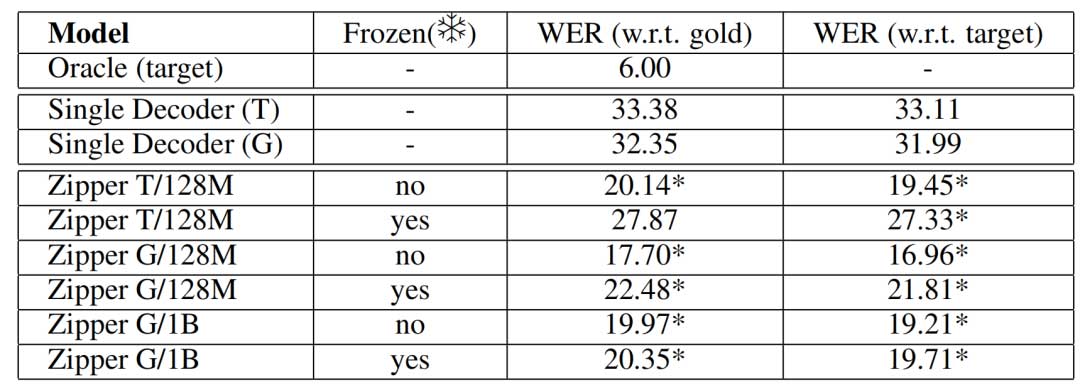
在LibriTTS数据集上进行TTS任务评估。Zipper模型在生成语音的WER上显著优于基线模型,尤其是在较长语音生成的场景中表现尤为突出。解冻语音骨干网络能够进一步提升性能,证明了在跨模态对齐时微调骨干网络的必要性。
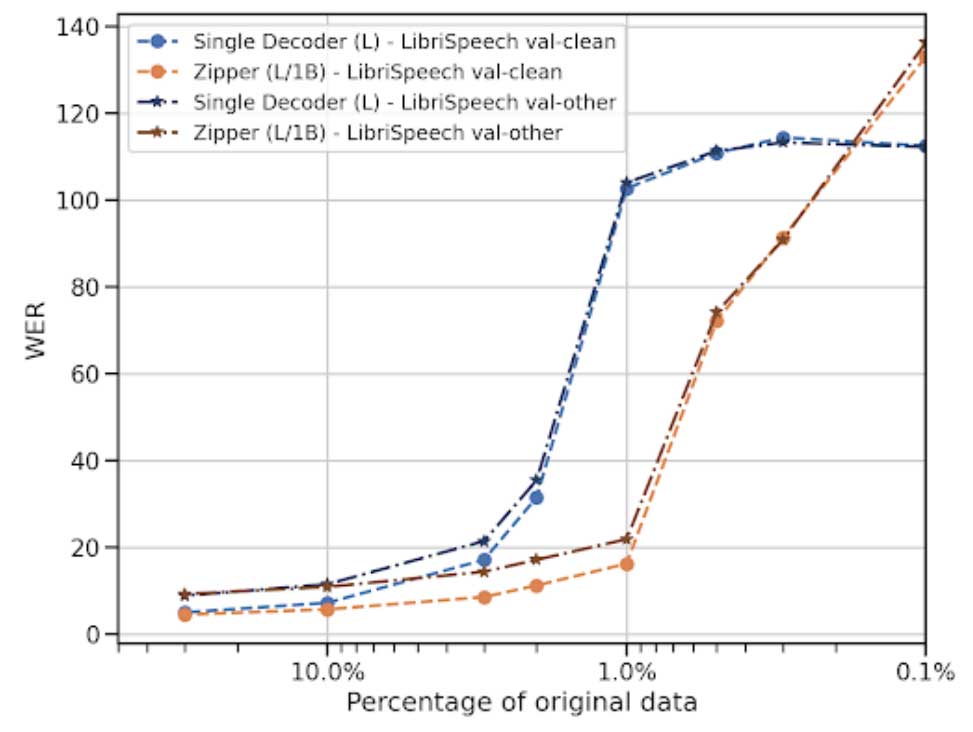
对齐数据量影响
通过减少训练数据量来评估模型在有限对齐数据情况下的性能。结果显示,Zipper在使用仅1%的对齐数据进行训练时,仍能显著优于基线模型,表现出较强的数据高效性。
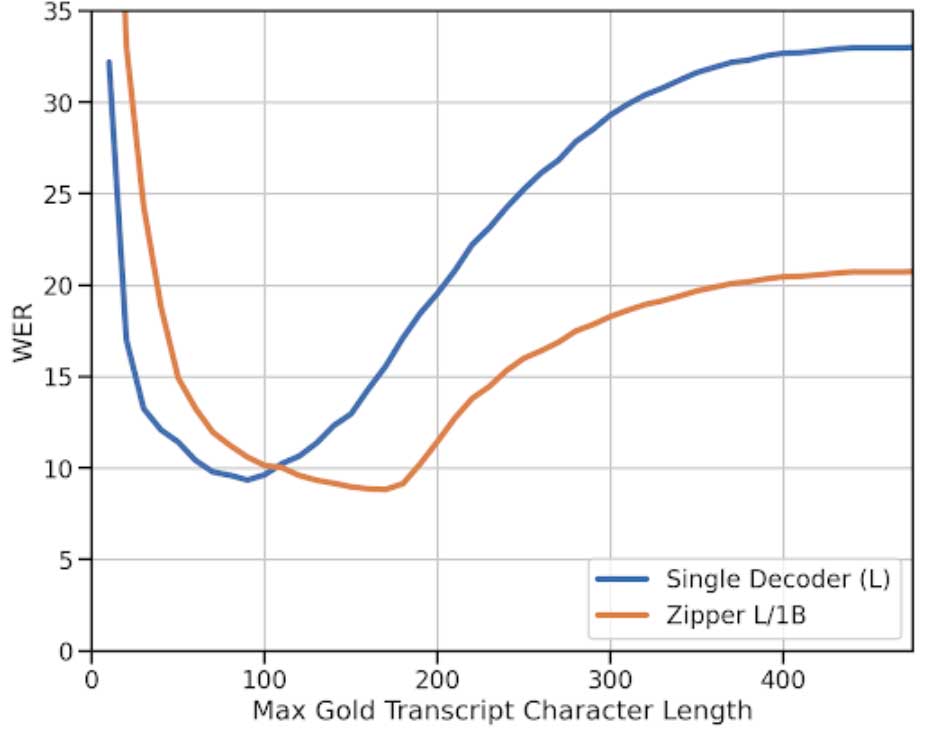
消融实验
对输入投影层和交叉注意力层的数量进行了消融实验,验证这些设计选择对模型性能的影响。发现文本输入投影层对TTS性能尤为重要,而增加交叉注意力层的数量对TTS性能有显著提升。
综上,实验结果表明,Zipper架构在跨模态生成任务中具有显著的优势,尤其是在数据受限的情况下表现尤为突出。
结论
在本文中,作者提出了Zipper,一种多塔解码器架构,用于组合独立预训练的单模态解码器,以实现多模态生成能力。此方法允许每种模态独立保留其单模态生成能力(例如,在跨模态对齐期间保持其参数冻结)。本文中将语音和文本模态结合的实验表明,在冻结模态上的跨模态性能(例如,ASR任务中的文本生成)具有竞争力,在未冻结模态上的绝对WER(词错误率)降低了12个百分点(相对WER降低了40%),与传统的扩展词汇表(例如,加入语音标记)和跨模态微调文本模型的方法相比。在允许(重新)使用强预训练的单模态模型的情况下,Zipper能够利用这些作为骨干网络,在有限的对齐数据情况下进行学习,这表明该方法在极端跨模态数据受限的场景中的有效性。未来的工作中,作者计划将模型扩展到两个以上的单模态解码器,以展示它如何用于结合更多模态(例如,同时理解和生成文本、语音、视频、图像等模态)。作者还计划将Zipper扩展到更大的模型规模和更广泛的数据多样性。
局限性
本文介绍了单模态预训练骨干网络的模块化融合的初步工作。由于本文的主要重点是新多模态架构的概念验证,因此作者只关注了文本和语音模态的融合。为了评估所提出架构在各种模态上的通用性,还需要进一步的实证证据,包括涉及更多利基模态和更多样化任务的其他模态。
此外,本文使用的实验设置是有限且小规模的。作者提出的模型规模较小,数据仅限于学术数据集上的朗读语音。虽然作者专注于方法的模块化性质,但没有完全研究模型的所有可能架构组件,例如在交叉注意力中使用共享的还是特定领域的MLP层,或广泛实验其他层或激活函数。最后,作者只实验了两种模态的融合。尽管此架构可以扩展到三种或更多模态,但作者没有探讨是否可以仅使用双模态对齐数据来融合多于两种模态,因为三模态对齐数据更加稀缺。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
