
大家好!今天给大家介绍我们团队最新的研究成果《WirelessLLM: Empowering Large Language Models Towards Wireless Intelligence》。在这篇文章中,我们定义了一种全新的无线通信大模型——WirelessLLM。这个模型的目标是让大语言模型具备无线领域的专业知识和技能,能够解决无线通信中面临的各种挑战和问题。比如,资源分配、频谱感知和协议理解等。通过这项研究,我们希望为实现智能化和自主化的无线通信系统迈出重要的一步。下面一起来了解我们的最新进展吧!
1. 背景介绍:大语言模型浪潮
随着人工智能技术的不断进步,大语言模型如GPT-4和Llama-3等已广泛应用于文本生成、语言翻译、自然语言理解等任务,显示出卓越的学习和推理能力[1]。这些模型通过大规模数据训练,能够捕捉深层次的语义关系和复杂的数据模式。最近,越来越多的研究人员和企业开始探索如何将大模型与特定领域知识相结合,解决行业痛点[2]。这些应用主要基于大模型的以下能力:
- 语义理解与文字生成能力:大语言模型最擅长的工作莫过于文字处理了。模型可以准确理解用户输入的信息,并生成相关且连贯的回答。
- 知识储备和运用能力:在预训练的过程中,大语言模型从数据集中获取了大量通用知识,并能够根据用户请求抽取相关知识,回答具体问题。
- 适应性和泛化能力:大语言模型有着上下文学习能力,对于训练数据中未包含的专业知识,可以在输入时补充样例,以提升模型的回答质量。
尽管大语言模型在许多领域展现出了广阔前景,将大语言模型运用到垂直领域(如无线通信系统)仍面临一些挑战:
- 幻觉问题:大语言模型有时会生成看似合理但实际错误的回答。这在可靠性要求高的领域可能引发严重后果。例如,如果一个无线通信系统优化模型给出了错误的资源分配策略,可能会导致网络性能下降,引发通信故障。
- 模态单一:大语言模型基于文本数据进行训练,不具有多模态分析能力,这限制了其的应用潜力。举例而言,无线通信系统涉及多种数据形式,如通信链路的信道状态信息、用户移动轨迹、业务需求分布等。仅依赖文本难以全面刻画复杂的通信问题。
- 知识老旧:预训练语料通常难以覆盖最新研究进展。对于无线通信这类快速发展的领域,这要求模型持续在新数据上进行微调,使其适应最新的标准和协议。
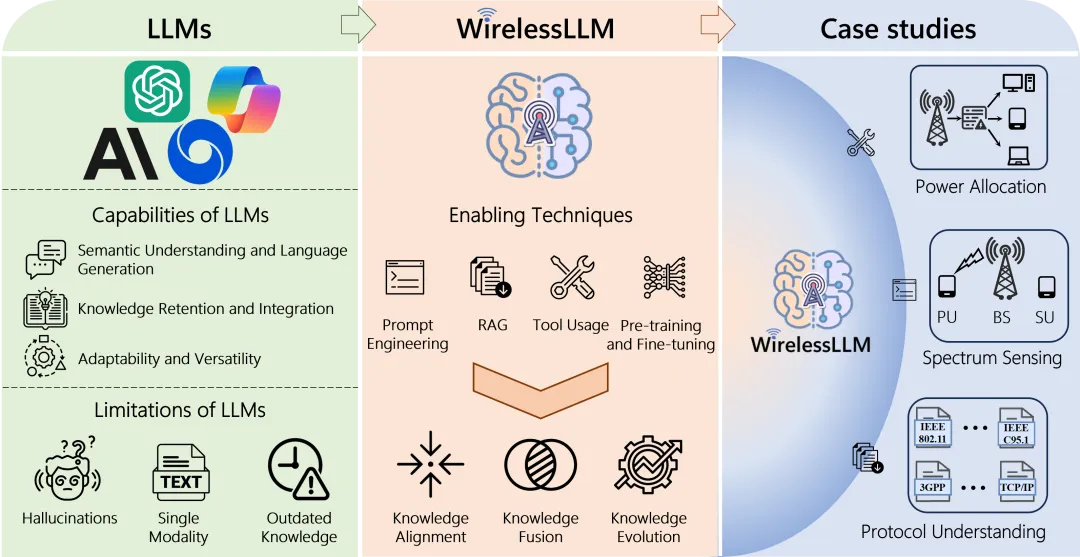
2. WirelessLLM:面向无线领域的大模型
为了应对上述挑战,我们提出WirelessLLM框架,如图1所示,通过引入无线领域知识和融合多模态数据,提升大语言模型在无线通信中的适用性。其设计理念主要基于以下几点:
- 知识对齐:确保模型与人类价值观的对齐是极为重要的,这有助于避免生成错误和虚假信息。在无线通信领域,知识对齐还意味着确保模型输出遵守物理规律,并与实际系统特性相一致。
- 知识融合:准确感知无线环境是通信智能化的基础。通过融合多种测量数据,如接收信号强度和信道矩阵,可以帮助模型建立对通信系统的全面认知。多模态知识的融合有助于提高感知的准确性和鲁棒性。
- 知识进化:大语言模型需要持续地学习和更新。通过利用人类的指导和信道的反馈来融入新知识,以便适应不断演进的通信标准和动态变化的信道状态。
为了实现WirelessLLM,我们需要用到以下技术:
- 提示工程(prompt engineering):通过设计特定的任务提示词,可以帮助语言模型生成更准确的响应。提示工程包括零样本提示,少样本提示以及思维链提示等技术。零样本提示不需要任何训练样本,直接通过精心设计的文本描述来指导模型完成任务。少样本提示则利用少量样本来诱导模型按照期望方式生成文本。思维链提示通过分解推理步骤,引导模型进行逐步推理,以提高复杂任务的完成质量。
- 检索增强生成(retrieval-augmented generation):利用检索模型从外部知识库中获取与用户输入相关的信息片段,再将其作为额外的输入提供给大语言模型。这种方法可以显著提升模型在开放域对话和问答任务上的表现,并且赋予模型获取最新信息的能力。
- 外部工具使用(tool usage):大语言模型具有使用工具的能力。首先调用外部插件、API、或是预训练好的深度学习模型来处理复杂的多模态数据,再使用自身的推理能力综合这些结果,得到高质量的输出。
- 模型训练与微调(pre-training and fine-tuning):在通用语料上预训练的语言模型具有强大的语言理解和生成能力,但对垂直领域知识的掌握仍显不足。因此,有必要在无线通信领域的文本上对模型进一步预训练,学习行业特定知识;并在下游任务的标注数据集上进行微调,使其适应具体的应用场景。持续学习是保持模型知识更新的重要手段。
3. 应用实例
下面通过功率分配、频谱感知和协议理解三个应用实例来验证WirelessLLM解决无线通信系统中不同类型问题的能力。
3.1 WirelessLLM用于OFDM系统的功率分配
功率分配是OFDM系统中的一个典型任务,其目标是通过给不同的子载波分配不同的功率值从而最大化通信系统容量,通常可以使用注水算法(water-filling)来实现。如上文介绍,通过提示工程、检索增强生成等方法,大模型在学习到无线通信领域的专业知识以后,应该具有解决该任务的能力。然而,如右边所示,如果我们直接将功率分配任务和信道状态直接作为输入给到ChatGPT,即使它具有相关领域知识,知道应该采用注水算法,但由于大模型本身数学推理能力的欠缺,它没有办法直接计算出答案,因此没有办法完成这个任务。
针对大模型在数学推理能力上的欠缺导致无法执行相关任务,我们所提出的WirelessLLM框架,融合了提示工程和外部工具调用,可以很好地解决这个问题。具体而言,如图2右边所示,我们结合了提示工程里的思维链(Chain-of-Thought, CoT)和程序辅助语言模型(Program-aided Language Model, PAL),从而让大模型可以逐步将原始的复杂任务分解为多个简单子任务,并且为每个子任务生成可以运行的程序。最终,通过调用外部的工具,如MATLAB,运行完整程序,从而获得最终的功率分配结果。结果显示,我们的WirelessLLM框架可以获得正确的基于注水算法的功率分配值。

3.2 WirelessLLM用于无线网络的频谱感知
为了验证WirelessLLM处理无线通信中物理层数据(时间序列数据)的能力,我们考虑认知无线系统中的频谱感知问题。频谱感知是指次用户(SU)为了不对主用户(PU)的通信产生干扰,需要对授权频段中是否存在PU的信号进行检测,从而机会性地访问授权频谱。频谱感知可以看成是对时间序列数据的一个二元分类问题:H0表示PU信号不存在(频谱空闲);H1表示PU信号存在(频谱占用)。下面我们使用WirelessLLM来解决这个二元分类问题,主要利用其提示工程的功能来完成该任务。图3给出的是WirelessLLM进行频谱感知的流程图。从图中可以看到,输入是下采样的时间序列数据(即授权频谱信号样本),输出的是模型对授权频谱的占用情况。WirelessLLM通过少量带标签样本(输入-输出对),利用提示工程能力将领域知识嵌入到LLM中,例如GPT-4和Claude-3 Opus,从而学习出最佳的分类边界。
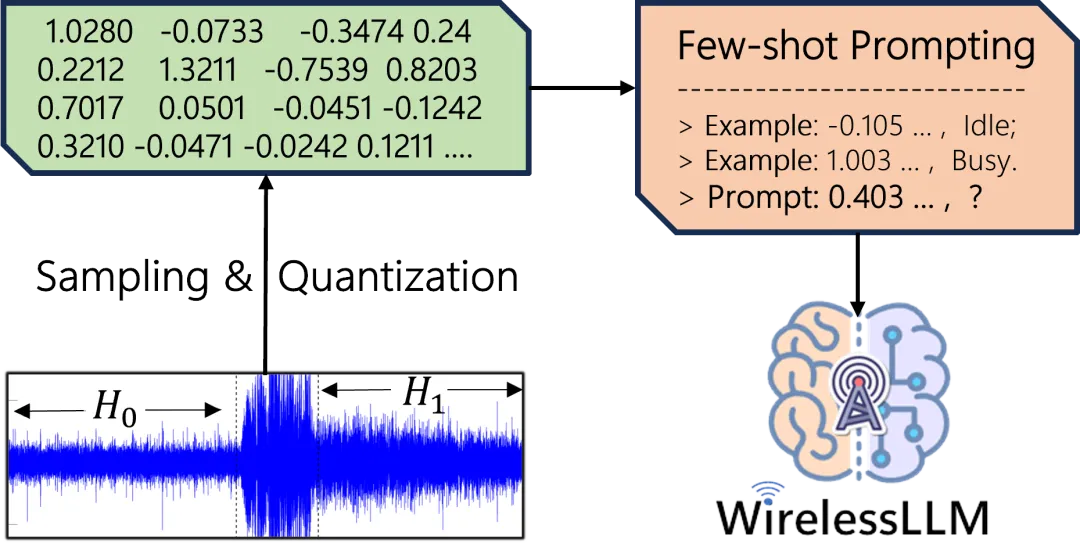
图4展示了能量检测法、基于GPT-4和Claude-3 Opus的WirelessLLM在不同信噪比(SNR)(-20、-10、-6、0 dB)下的检测概率。仿真中,我们设定背景噪声功率为-100 dBm,虚警概率为0.5。总的训练样本数目为20,其中噪声和信号样本各一半,每个样本包含50个时间采样数据。其中,能量检测法在噪声功率精确已知时,具有最佳的检测性能[3]。从图中可以看到,只需少量示例,WirelessLLM在不同SNR下就可以获得接近最佳能量检测法的性能。而且,当 SNR超过0 dB时,WirelessLLM的性能与最佳能量检测器相同。此外,基于 Claude-3 Opus模型略优于基于GPT-4的WirelessLLM。总之,通过展示WirelessLLM框架在认知无线电网络频谱感知中的效率,我们探索了其在无线通信系统中变革物理层技术设计和优化的潜力。
3.3 WirelessLLM用于网络协议理解
无线网络使用3GPP、IEEE和ITU等组织发布的各种协议、标准和规范来确保设备之间可靠高效的通信。然而,由于协议的频繁更新和大量发布,人们很难跟上最新的变化,导致网络设计和管理的延迟和低效,同时增加了手动协议分析的成本。此外,无线网络协议的复杂性使得识别潜在问题和优化网络性能变得极具挑战性。借助卓越的语言理解能力,大语言模型可以更快地获取与无线网络协议相关的信息,从而在无线网络设计、构建和运营等不同阶段发挥重要作用。
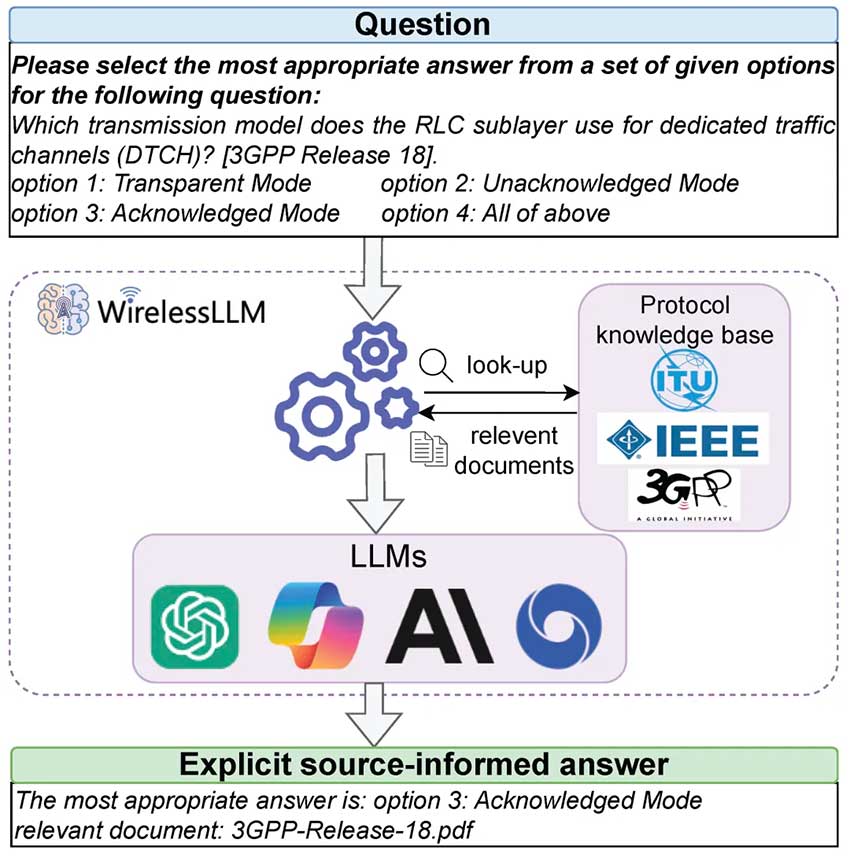
然而,针对频繁更新迭代的无线网络协议,大语言模型可能缺乏特定的无线网络知识,为此,我们在WirelessLLM中引入了检索增强生成模块,通过为WirelessLLM注入最新且相关的领域知识,来提高响应的准确性和可靠性。如图5所示,给定一个关于网络协议的问题,WirelessLLM首先搜索协议知识库(如3GPP文档)以检索外部相关信息,然后将其与用户输入的问题结合起来,构建一个更丰富的提示作为LLMs的输入。因此,WirelessLLM能够生成一个明确来源的答案,从而减轻传统LLMs中常见的幻觉问题。
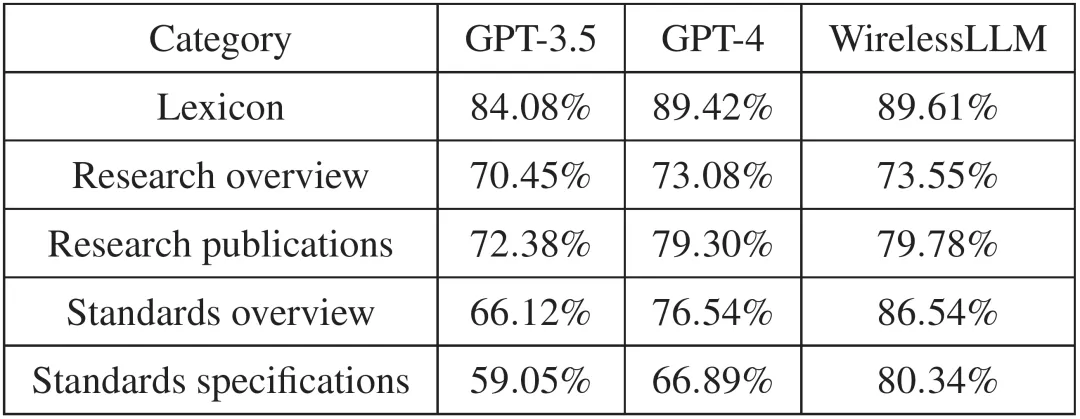
为了验证WirelessLLM的性能,我们基于电信领域知识问答数据集TeleQnA[4]展开了实验,如表1所示,在不同类别的无线领域知识问答题库下,WirelessLLM均有最高的准确率,特别是在无线网络协议相关的问题分类(如Standards specifications)上,WirelessLLM相比GPT-4和GPT-3.5提升了10-20%的准确率。
4. 挑战
最后我们探讨WirelessLLM面临的三个挑战:在数据稀缺和资源限制的情况下如何训练WirelessLLM、在不同的边缘设备和网络上如何部署WirelessLLM以及如何保护WirelessLLM的安全和隐私系统。4.1 WirelessLLM训练所面临的挑战
- 训练数据的稀缺性:由于无线网络的复杂性和多样性,以及隐私问题,用于训练WirelessLLM的无线网络数据相对较少,此外,特定无线任务(如决策)的标注数据的缺乏进一步加剧了该挑战。
- 无线网络任务的多样性:由于无线网络在拓扑结构、协议和干扰程度等方面存在显著差异,WirelessLLM的训练很难有效泛化到不同的无线网络场景中。同时,WirelessLLM通常被期望实现“one model for all”的目标,因此,损失函数的设计需要反映多样化的任务目标和复杂的无线网络特性。
- 计算资源的限制:Wiereless的训练需要大量的计算资源,这阻碍了其在资源受限环境中的可扩展性。因此,WirelessLLM的训练需要对模型复杂性和计算资源进行权衡。
4.2 WirelessLLM部署所面临的挑战
- 模型参数巨大导致的部署难题:WirelessLLM通常包含数十亿个参数,这对无线网络中的部署提出了特殊挑战。边缘设备的计算能力、存储和内存有限,无法直接处理如此资源密集型的模型。在众多边缘设备上分发和维护大模型需要大量资源和协调,在后续维护上也具有挑战性。
- 网络异构性引发的不一致性问题:无线网络由通过不同网络类型(如5G、Wi-Fi和LTE)连接的各种设备组成,每种网络的能力各不相同。网络带宽的波动会影响传输大量数据(包括模型参数或更新)的能力。此外,网络延迟可能会有显著差异,这会影响依赖WirelessLLM实时交互的应用程序的性能。
- 资源有限性制约下的效率瓶颈:考虑到边缘设备的计算能力、存储和内存限制,以及无线网络的带宽和延迟可变性,在资源有限的情况下高效部署和更新WirelessLLM面临挑战。因此,需要制定策略来优化模型的分发、更新和执行,以确保在无线网络中实现WirelessLLM的高效部署和实时性能。
4.3 WirelessLLM的安全与隐私挑战
- 模型训练阶段的安全挑战:在模型训练阶段,尤其是预训练阶段,训练集通常包含了大量的互联网公共数据,如果有恶意攻击者在公共数据上植入有害数据,从而操纵或者监控使用这些有害数据进行训练的大模型,这将给WirelessLLM训练过程中的安全性带来极大的挑战。
- 模型运行阶段的安全挑战:当WirelessLLM部署使用时,由于大模型的运作方式是接受用户的输入并生成相应的回复,这个过程就可以被攻击者利用,使用精心设计的提示来欺骗大模型,从而生成非预期的回复响应,甚至直接操纵大模型,因此模型在运行过程中的安全性也是一个核心问题。
- 海量训练数据需求引发的隐私担忧:如上所述,WirelessLLM的预训练需要海量的训练数据,这些数据里面不可避免地包含了一些隐私信息,预训练过程会让大模型不同程度地记住这些信息。一旦遭遇对抗性攻击,由于目前人们尚未完全理解大模型的运作机制,如何保障隐私信息不被泄露将是一个重要挑战。
5. 总结
本文介绍了一种全新的WirelessLLM框架,该框架专为大型语言模型在无线通信领域的应用而设计。通过该框架,我们不仅可以解决大语言模型在无线通信中遇到的固有局限,还显著提升了其处理无线通信问题的能力。文章中首先确定了WirelessLLM的三大核心原则,并探讨了四种潜在的实施技术。具体应用方面,我们通过三个实例——功率分配、频谱感知和协议理解,展示了WirelessLLM在处理复杂无线通信挑战时的卓越性能。此外,我们还讨论了在训练、部署和确保隐私安全方面WirelessLLM面临的挑战。随着WirelessLLM能力的不断完善和扩展,我们相信它将成为设计和管理下一代无线系统的关键工具,并大幅推动大语言模型在无线通信领域发挥更大的影响力。
参考文献:
[0] Jiawei Shao, Jingwen Tong, Qiong Wu, Wei Guo, Zijian Li, Zehong Lin, and Jun Zhang, “WirelessLLM: Empowering large language models towards wireless intelligence,” arxiv preprint arxiv: 2405.17053, 2024.
[1] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, pp. 9, 2019.
[2] Yifei Shen, Jiawei Shao, Xinjie Zhang, Zehong Lin, Hao Pan, Dongsheng Li, Jun Zhang, and Khaled B Letaief, “Large language models empowered autonomous edge AI for connected intelligence,” IEEE Commun. Mag., 2024, early access, doi: 10.1109/MCOM.001.2300550.
[3] Jingwen Tong, Ming Jin, Qinghua Guo, and Long Qu, “Energy detection under interference power uncertainty,” IEEE Commun. Lett., vol. 21, no. 8, pp. 1887–1890, Aug. 2017.
[4] Ali Maatouk, Fadhel Ayed, Nicola Piovesan, Antonio De Domenico, Merouane Debbah, and Zhi-Quan Luo,“TeleQnA: A benchmark dataset to assess large language models telecommunications knowledge,” arXiv preprint arXiv:2310.15051, 2023.
作者:Jiawei Shao, Jingwen Tong, Qiong Wu, Wei Guo, Zijian Li, Zehong Lin, Jun Zhang
审阅:Zijian Li
编辑:Zehong Lin
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
