
通常需要在超大规模的数据集上对Vision Transformer(ViT)进行预训练,以在相对较小的数据集上实现更好的性能。在本文中,作者证明了视频掩蔽自编码器(VideoMAE)是自监督视频预训练(SSVP)的数据高效学习器。VideoMAE提出了具有极高比率的视频管道掩模策略,这种简单的设计使视频重建成为一项更具挑战性的自监督任务,从而鼓励模型在预训练过程中提取更有效的视频表示。VideoMAE获得了三个重要发现:(1)极高比例的掩蔽率(即90%至95%)仍然为VideoMAE带来了良好的性能,时间上冗余的视频能实现了比图像更高的掩蔽率。(2) VideoMAE在不使用任何额外数据的情况下,在非常小的数据集(大约3k-4k的视频)上取得了令人印象深刻的结果。这在一定程度上因为视频重建任务的挑战性,加强了模型对高级结构信息的学习。(3) VideoMAE表明,对于SSVP来说,数据质量比数据量更重要。预训练数据集和目标数据集之间的域外泛化仍是一个重要影响因素。
题目:VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
作者:Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
来源:NeurIPS 2022
文章链接:https://arxiv.org/abs/2203.12602
整理人:李江川
引言
Transformer在自然语言处理方面取得了极大成功,而ViT将Transformer改进到了一系列计算机视觉任务上,包括图像分类、对象检测、语义分割等,同样取得了令人印象深刻的结果。而训练一个高效的ViT通常需要大规模的有监督数据集,预训练的ViT通过使用数亿张标记图像来获得良好的性能。对于视频任务中的Transformer,它们通常基于图像任务中的Transformer,并且在很大程度上依赖于来自大规模图像数据的预训练模型(例如在ImageNet上进行预训练)。
先前关于从头开始训练视频Transformer的试验都没能取得满意的结果,如何在不使用任何预先训练的模型或额外的图像数据的情况下在视频数据集上高效地训练视频Transformer仍然是一个挑战。此外,与图像数据集相比,现有的视频数据集相对较小,这进一步增加了从头开始训练视频Transformer的难度。通过使用大规模图像数据集,自监督学习拥有良好的性能表现,当被转移到下游任务时,所学习的表征通常优于通过有监督学习的表征。可以预想到,这种自监督学习范式可以提供一种很有前途的解决方案,以应对训练视频Transformer的挑战。
掩蔽自编码器在NLP和图像中取得了成功,基于此,作者提出了一种新的自监督视频预训练(SSVP)方法,称为视频掩蔽动编码器(VideoMAE)。VideoMAE继承了掩蔽随机图像块并重建缺失的图像块的设计思路。然而,视频的时间维度使其与图像中的掩蔽建模不同。首先,视频帧通常被密集地捕获,其语义随时间变化缓慢。这种时间冗余将增加模型在没有学到高级特征的情况下从时空邻域中恢复丢失像素的风险。此外,视频帧之间存在对应关系,除非考虑特定的掩蔽策略,否则这种时间相关性可能导致信息泄漏(即掩蔽的时空内容再次出现)。从这个意义上说,对于每个掩蔽图像块,很容易在相邻帧中找到相应的未掩蔽的副本。这一特性将使模型学习到的一些难以推广到新场景的“快捷方式”(比如从特定区域抽取图像块)。
为了使视频掩蔽建模更有效,VideoMAE提出了一种具有极高比率的管道掩蔽设计。首先,由于时间冗余,VideoMAE会下采样视频,并使用极高的掩蔽率来从下采样片段中丢弃图像块。这种简单的策略有效地提高了预训练性能,而且由于非对称的编码器-解码器架构,能大大降低计算成本。其次,为了考虑时间相关性,设计了一种简单而有效的管道掩蔽策略,这有助于降低重建过程中没有运动或运动可忽略的图像块导致信息泄漏的风险。正是因为有了这种简单而有效的设计,VideoMAE能够在相对较小的视频数据集上训练视频Transformer,如SomethingSomething、UCF101和HMDB51。
VideoMAE的主要贡献有三个方面:(1)提出了一种简单但有效的视频掩蔽自编码器,释放了ViT在视频识别中的潜力。(2)为了解决掩蔽视频建模中的信息泄漏问题,提出了一种具有极高比率的管道掩蔽策略,带来了性能的提高。(3)与NLP和图像领域中的结果一致,VideoMAE证明了这种简单的掩蔽和重建策略为自监督视频预训练提供了一个很好的解决范式。使用VideoMAE预训练的模型显著优于从头开始训练或使用对比学习方法预训练的模型。
提出的方法
VideoMAE采用了和ImageMAE相同的设计,使用非对称编码器-解码器架构执行掩蔽和重建任务。输入图像首先被划分为16 x 16大小的不重叠的图像块,然后将每个图像块用嵌入为token来表示。然后,token的部分子集以高掩蔽比被随机掩蔽,并且只有剩余的token被馈送到编码器。最后,用解码器处理来自编码器的可见token和可学习的掩蔽token之上,以重建图像。网络的损失函数是重建图像块和掩蔽图像块之间的MSE误差。
视频数据的特征
视频序列存在时间上的冗余性和相关性。冗余性导致了如果直接采用原始视频的帧率进行训练,训练效率会非常低,同时会使得网络更多地关注数据中的静态特征或者一些局部变化缓慢的运动特征。导致网络无法有效提取对下游任务更重要的运动特征。而相关性指视频帧之间也存在语义的对应关系,这种时序相关性可能会增加重建过程中的“信息泄漏”的风险。具体而言,网络可以利用视频中的时序相关性,通过“复制粘贴”相邻帧中时序对应位置的未被遮蔽的像素块来进行像素块重建。VideoMAE仅仅能学习到较低语义的时间对应关系特征,而不是高层抽象的语义信息!
为了解决这一问题,VideoMAE提出了一种新的掩蔽策略,使重建更具挑战性,并鼓励模型更有效的学习时空结构表征。如图1所示,缓慢变化视频数据的一个普遍先验。这导致了时间上的两个重要特征:时间冗余和时间相关性。时间冗余使得可以在极高的掩蔽比下恢复像素。时间相关性导致通过普通的帧掩蔽或随机掩蔽,模型能够在相邻帧中找到那些对应的块来更容易地重建丢失的像素。为了鼓励模型学习更具代表性表示,提出了一种管道掩蔽策略,其中掩蔽位置对所有帧都是相同的。

VideoMAE的处理框架
VideoMAE的总体流程如图2所示。VideoMAE将时序下采样的帧作为输入,使用前面提到的高比率管道掩蔽设计,以在非对称编码器结构中执行MAE预训练。
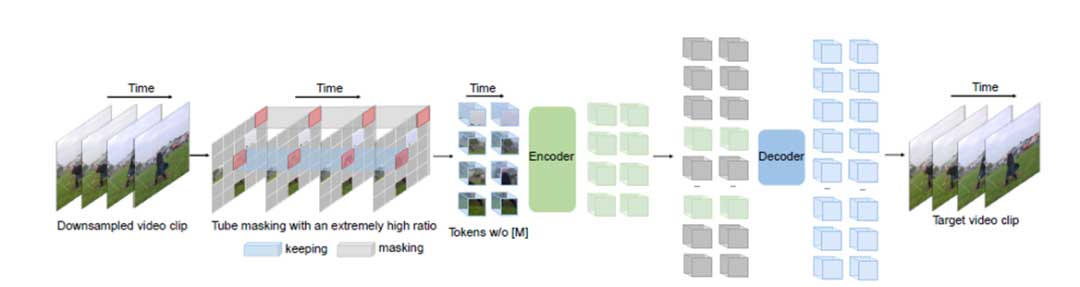
根据之前对连续帧上的时间冗余的分析,VideoMAE使用跨步时间采样策略来执行更高效的视频预训练。首先从原始视频中随机采样由t个连续帧组成的一个视频剪辑。然后,使用时间采样将剪辑压缩为T帧,每个帧包含H x W x 3个像素。在实验中,在Kinetics数据集和Something-Something数据集上,采样步幅分别设置为4和2。VideoMAE中采用了联合时空图像块嵌入,将每个大小 2 x 16 x 16 为的图像块视为一个token进行嵌入。这种设计可以降低输入的空间和时间维度,有助于缓解视频中的时空冗余。
时间冗余是影响VideoMAE设计的一个因素。与ImageMAE相比,VideoMAE可以达到极高的掩蔽率(例如90%至95%)。视频的信息密度远低于图像,而高比率会增加重建难度。这种高掩蔽比有助于减轻掩蔽建模过程中的信息泄漏,并使掩蔽视频重建成为一项有意义的自监督预训练任务。其次,时间相关性是VideoMAE设计中的另一个因素。时间管道掩蔽策略在整个时间轴上展开,即不同的帧共享相同的掩蔽图。有了这种机制,掩蔽图像块在时间上的近邻总是被屏蔽的。因此,对于一些没有运动或运动很小的图像块,VideoMAE无法在所有帧中找到对应的时空内容。通过这种方式,它将鼓励VideoMAE对高级语义进行推理,以恢复这些完全丢失的多维数据。这种简单的策略可以解决没有运动或运动可忽略的立方体的信息泄漏的问题,并在实践中对掩蔽视频预训练更有效。
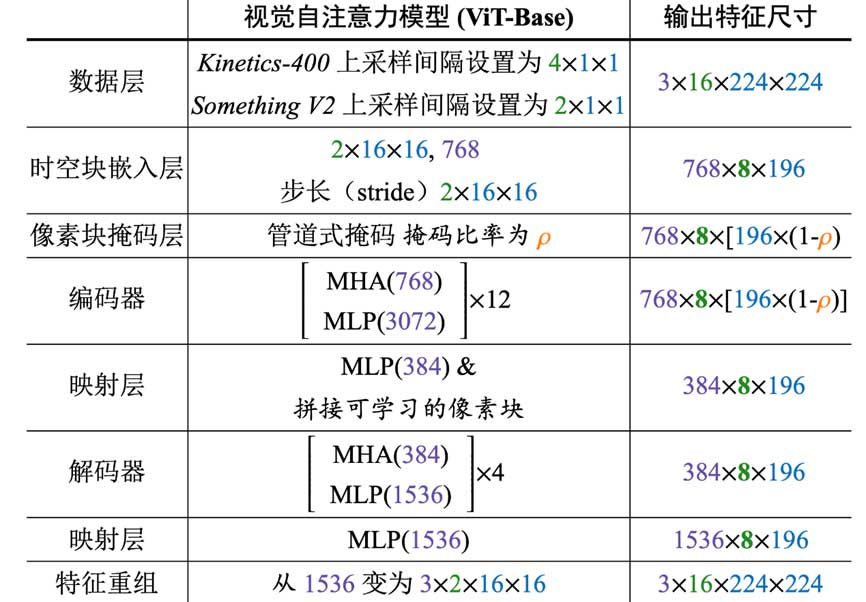
由于上面提到的高比例的掩蔽比,只剩下几个token作为编码器的输入。为了更好地捕捉剩余token中的高级时空信息,VideoMAE使用ViT主干,并采用联合时空注意力机制。因此,所有token都可以在多头自注意力层中相互作用。编码器和解码器的具体架构设计如图3所示。联合时空注意力机制的计算复杂度是一个瓶颈,通过设计的极高掩蔽比的掩蔽策略,在预训练阶段仅将未掩蔽的token放入编码器来解决这一问题。
实验结果
VideoMAE在五个常见的视频数据集上评估其性能:Kinetics-400、Something-Something V2、UCF101、HMDB51和AVA。Kinetics-400包含约24万个训练视频和2万个10秒的验证视频。Something-Something V2有大约16.9万个用于训练的视频和2万个用于验证的视频。UCF101和HMDB51是两个相对较小的视频数据集,分别包含约9.5k/3.5k的train/val视频和3.5k/1.5k的train/val视频。与那些大型视频数据集相比,这两个小型数据集更适合验证VideoMAE的有效性,因为在小型数据集上训练大型ViT模型更具挑战性。此外,还将VideoMAE学习的ViT模型转移到下游的动作检测任务中。AVA是一个用于人类动作时空定位的数据集,具有211k个训练和57k个验证视频片段。在下游任务的实验中,先在训练集上微调预先训练的VideoMAE模型,然后在验证集上测试结果。
消融实验
各个消融实验的结果如图4所示。VideoMAE的默认主干网络为Something-Something V2(SSV2)和Kinetics-400(K400)上的16帧ViT-B模型。以90%的掩蔽率训练800轮。下面将介绍各个消融实验的具体内容。
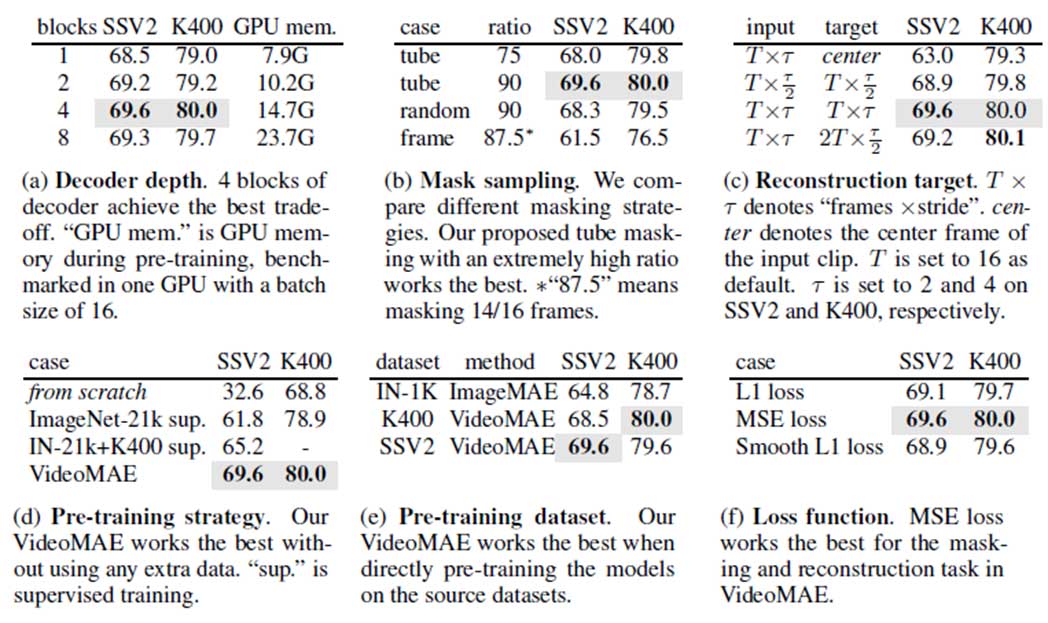
轻量级解码器是VideoMAE中的一个关键组件。表a展示了使用不同深度的解码器的实验结果。更深的解码器可以取得更好的性能,而深度较浅的解码器可以有效地降低GPU的显存占用。默认情况下解码器的层数设置为4。
将不同的掩码策略与管道掩码策略进行比较,结果如表b所示,全局随机掩蔽和掩蔽图像帧的性能劣于管道掩蔽策略。这可能是由于管道掩蔽策略可以一定程度上缓解视频数据中的时序冗余性和时序相关性。即使将掩蔽比率增加到90%,VideoMAE在SSV2上的性能也可以从68.0%提升到69.6%。VideoMAE中掩蔽策略和的掩蔽比率的设计可以使重建成为更具挑战性的代理任务,强制模型学习到更加高层次的时空特征。
这里比较了在VideoMAE中采用不同的重建目标的结果,具体见表c。首先,如果只使用视频片段中的中心帧作为重建目标,VideoMAE在下游任务中的性能会大大降低。同时,VideoMAE对采样间隔也很敏感。如果选择重建更密集的视频片段,其结果会明显低于默认的经过时序下采样的视频片段。最后还尝试从经过时序下采样的视频片段中重建视频片段中更加密集的视频帧,但这种设置会需要解码更多的视频帧,使得训练速度变慢,效果也没有更好。
表d比较了VideoMAE中的预训练策略。与之前方法的实验结论类似,在SSV2这个对运动信息更加敏感的数据集上从头开始训练ViT并不能取得令人满意的结果。如果利用在大规模图像数据集(ImageNet-21K)上预训练的ViT模型作为初始化,能够获得更好的准确度,可以从32.6%提升到61.8%。而使用在ImageNet-21K和Kinetics-400上预训练的模型可以进一步将准确率提高到65.2%。而利用VideoMAE从视频数据集本身预训练得到的ViT,在不使用任何额外的数据的条件下,最终能达到69.6%的最佳性能。Kinetics-400数据集上也有相似的结论。
表e比较了VideoMAE中不同的预训练数据集。首先按照MAE的设置,在ImageNet-1K上对ViT进行自监督预训练。然后利用I3D中的策略,将 2D嵌入层膨胀为3D时空嵌入层,并在视频数据集上微调模型。这种训练范式可以超过从头有监督训练的模型。紧接着,将MAE预训练的模型与在 Kinetics-400上通过VideoMAE预训练的ViT模型的性能进行了比较。可以发现VideoMAE可以实现比MAE更好的性能。然而这两种预训练模型均未能取得比仅在SSV2数据集上进行自监督预训练的VideoMAE更好的性能。由此可见,预训练数据集和目标数据集之间的域外泛化可能是一个重要问题。表f进一步比较了不同损失函数的结果。
模型性能对比
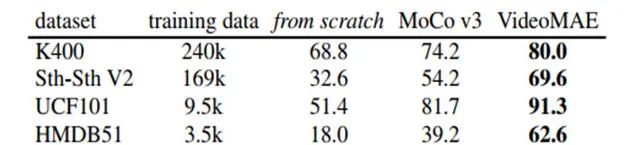
先前很多工作对视频自监督预训练进行了广泛的研究,但这些方法主要使用卷积神经网络作为主干网络,很少有方法去研究基于ViT的训练机制。因此,为了验证基于ViT的VideoMAE对视频自监督预训练的有效性,对两种基于ViT的训练方法进行了比较:(1) 从头开始有监督训练模型。(2) 使用对比学习方法(如MoCo v3)进行自监督预训练。实验结果如图5所示,可以发现VideoMAE明显优于其他两种训练方法。VideoMAE卓越的性能表明,掩蔽和重建这种自监督范式为ViT提供了一种高效的预训练机制。值得注意的是,随着训练集的变小,VideoMAE与其他两种训练方法之间的性能差距变得越来越大。即使HMDB51数据集中只包含大约3500个视频片段,基于VideoMAE的预训练模型仍然可以获得令人非常满意的准确率。这一结果表明VideoMAE是一种数据高效的学习器。这与对比学习需要大量数据进行预训练的情况不同,VideoMAE的数据高效的特性在视频数据有限的场景下显得尤为重要。
还进一步比较了使用VideoMAE进行预训练和使用MoCo v3预训练的计算效率。由于使用掩蔽加重建这种极具挑战性的代理任务,每次迭代过程网络只能观察到10%的输入数据(90%的token被遮蔽),因此VideoMAE需要更多的训练轮次数。极高比例的token被掩蔽这种设计大大节约了预训练的计算消耗和时间。VideoMAE预训练800轮次仅仅需要19.5小时,而MoCo v3预训练300轮次就需要61.7小时。具体结果可见图6。

为了进一步研究VideoMAE学习到的特征,对经过预训练的VideoMAE的泛化和迁移能力进行了评估。图7展示了在Kinetics-400数据集上进行预训练的VideoMAE迁移到Something-Something V2、UCF101和HMDB51数据集上的效果。同时也展示了使用MoCo v3进行预训练的模型的迁移能力。结果表明,利用VideoMAE进行预训练的模型的迁移和泛化能力优于基于MoCo v3进行预训练的模型。这说明VideoMAE能够学习到更多可迁移的特征表示。在Kinetics-400数据集上进行预训练的VideoMAE比直接在UCF101和HMDB51数据集上进行预训练的VideoMAE效果好。但是在Kinetics-400数据集上进行预训练的模型在Something-Something V2数据集上的迁移能力较差。

此外,VideoMAE还与之前的很多SOTA工作进行了对比,这里由于篇幅所限,就不再展示。
总结
本文提出了一种用于视频Transformer预训练的简单且数据高效的自监督学习方法(VideoMAE)。VideoMAE引入了两种关键设计,即极高的掩蔽比和管道掩蔽策略,这使视频重建任务更具挑战性。这项更具挑战性的任务将鼓励VideoMAE学习到更具代表性的特征,并缓解信息泄露的问题。实验结果表明,该算法适用于不同尺度的视频数据集。特别的,可以通过数千个视频片段来学习高效的VideoMAE,这对于可用数据有限的场景来说具有重要的实用价值。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
