
VMAF(视频多方法评估融合)已成为视频质量评估领域的一个著名标准,与 PSNR 和 SSIM 等传统指标相比,它更接近人类的感知。该质量衡量标准由 Netflix 开发,目前仍作为开源项目由 Netflix 维护。通过 NVIDIA 开源的 CUDA 加速 VMAF,延迟时间可以缩短 50 倍,为优化实时转码的 VMAF 铺平了道路,同时与基于 CPU 的解决方案相比,在功耗和成本方面也具有显著优势。NVIDIA GPU 配备了编码(NVenc)和解码(NVdec)专用硬件。对于 Snap 而言,CUDA 加速的 VMAF 可通过 NVdec 实现完全基于 GPU 的流水线,从而大大降低云实例的成本。除了节省约 50% 的计算成本外,Snap 现在还将 HEVC NVenc 与 CUDA 加速的 VMAF 结合使用,为其记忆功能提供了一种经济高效的转码、分析输出质量和根据 VMAF 调整编码选项的方法。
来源:GTC 2024
演讲题目:VMAF CUDA: Running at Transcode Speed
主讲人:Cem Moluluo,Jorge Estrada
视频链接:https://www.nvidia.com/en-us/on-demand/session/gtc24-s62417/
博客链接:https://developer.nvidia.com/blog/calculating-video-quality-using-nvidia-gpus-and-vmaf-cuda/
内容整理:阳浩宁
VMAF简介
传统的视频质量评价指标包括 PSNR 和 SSIM 等。而 VMAF 由 Netflix于 2017 年提出,是一种全参考的视频质量评价指标,分数范围由 0 到 100,越高代表质量越好。VMAF 试图准确地捕捉人类的感知,将人类视觉建模与不断发展的机器学习技术相结合,使其能够适应新的内容,在与人类视觉感知保持一致方面表现出色。VMAF 现在已经被 Netflix,Snap,V-Nova等公司采用。
VMAF-CPU
图1展示了 VMAF 在 CPU 上的实现方式。VMAF 使用参考图像和失真图像的几个关键指标来衡量视频质量,包括:(1)视觉信息保真度(VIF):量化原始内容的保存情况,反映感知到的信息损失 (2)加性失真测量(ADM):评估结构变化和纹理退化。它对噪音等加性失真特别敏感。(3)运动特征:对评估动态场景中的运动渲染质量至关重要。
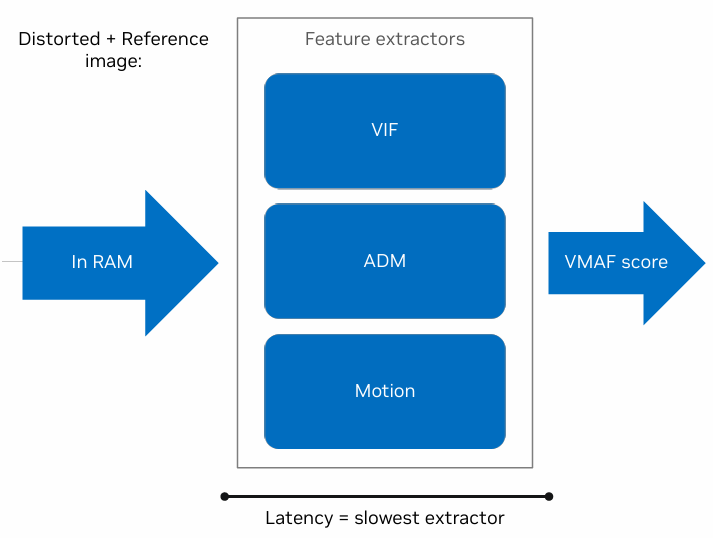
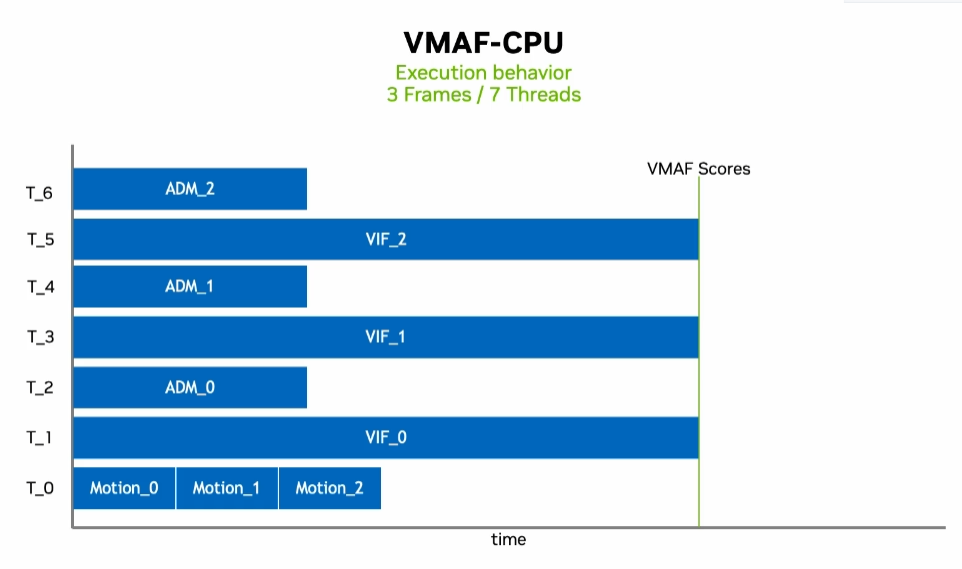
这些指标被用作支持向量机(SVM)回归器的输入特征,该回归器对这些指标进行整合,计算出最终的 VMAF 分数。这种方法可确保全面、准确地反映人眼感知到的视频质量。VIF 和 ADM 等特征提取器不需要任何先验信息,它们只需要一个参考帧和一个失真帧作为输入。与其他两种不同的是,运动特征的提取还需要之前运动特征提取器迭代的信息(即具有帧间依赖性)。在 CPU 上计算 VMAF 时,可以将每幅图像的上述特征计算分配给多个线程。因此,VMAF 计算可以从更多的 CPU 内核中获益。在 CPU 上计算 VMAF 分数取决于必须提取的最慢特征。此外,运动特征得分的计算与时间有关,因此不能使用多线程。因此,每帧的 VMAF 分数延迟与可使用的线程数无关。性能分析表明,VIF 通常需要更多时间来计算,因此成为主要的限制。不过,线程数量越多,以 FPS 为单位的 VMAF 的吞吐量就越大。
VMAF-CUDA
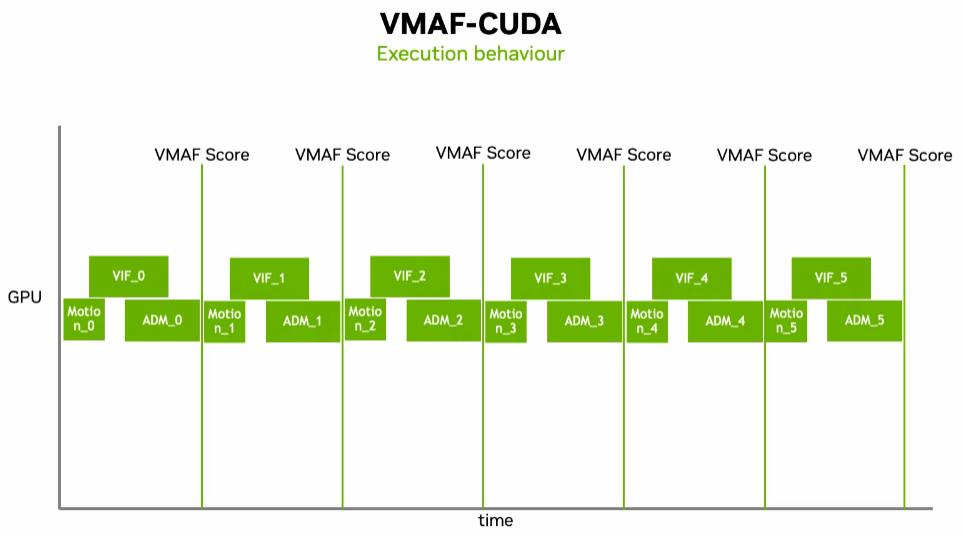
VMAF 的 CUDA 实现中为特征提取器设置了 CUDA 核心,并针对 GPU 进行了优化,计算流程也从为特定的特征提取器分配部分 GPU 计算资源以进行并发计算改成了为每个特征分配整个 GPU 计算资源并按顺序进行计算,如图3所示。此外,VMAF-CUDA还引入了帧并行计算,CUDA 核心数会随着帧的分辨率增高而增多。
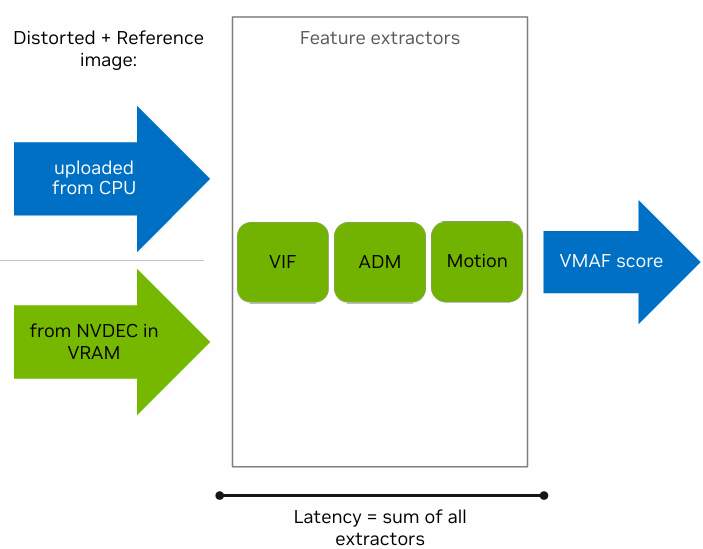
使用 CUDA 计算时,输入图像可以位于 CPU 或 GPU 上。CPU 上的图像在计算时会被迅速上传至 GPU,而 GPU 上的图像可从 NVENC/NVDEC 或 CUDA 内核等来源获得。整个 GPU 实现包括特征提取器的计算和进出 GPU 的内存传输,它相对于 CPU 异步工作,只需要一个线程来运行。VMAF-CUDA 可以作为 VMAF-CPU 即插即用的替代。在实际的计算过程中,单个流程并不会占用全部的 GPU 资源,因此可以同时执行这些操作,更有效地利用资源。
VMAF-CUDA 还可以加速 PSNR 计算。VMAF 和 PSNR 通常同时计算。我们的研究表明,如果 PSNR 与 VMAF-CUDA 一起在 CPU 上运行,那么 PSNR 将成为瓶颈,因为它需要通过 PCIe 总线从 GPU 内存中获取解码图像。PCIe 传输速度有限,会严重影响性能。为此,也可以使用 https://github.com/Netflix/vmaf/pull/1175 中的方法在 GPU 上计算 PSNR。
VMAF-CUDA的优势
VMAF-CUDA 可在编码过程中使用。NVIDIA GPU 可以在独立于 NVENC 和 NVDEC 的 GPU 内核上运行计算任务。NVENC 使用原始视频帧,而 NVDEC 则将输出帧解码到视频内存中。这意味着参考帧和失真帧都保留在视频内存中,并可输入 VMAF-CUDA。因此,由于 NVENC 不需要 GPU 计算资源,可以在编码过程中计算 VMAF。VMAF-CUDA 还可在转码过程中用于质量监控。将 H.264 比特流转码为 H.265 时,NVDEC 会对输入比特流进行解码,并将其帧写入 GPU VRAM(参考帧)。该参考帧使用 NVENC 编码为 H.265,可直接解码,从而产生失真的帧。这一过程将计算资源闲置,同时在 GPU 上进行转码,并将数据保存在 GPU 内存中。VMAF-CUDA 可以利用这些闲置资源计算分数,而无需中断转码,也无需额外的内存传输。因此,与 CPU 实现相比,VMAF-CUDA 是一种经济高效的选择。VMAF-CUDA 与 FFmpeg v6.1 完全集成,并支持 GPU 框架,以实现硬件加速解码。使用源代码链接 VMAF 和 FFmpeg 后,只需最新的 NVIDIA GPU 驱动程序即可执行,而且不需要事先了解任何 CUDA 知识。FFmpeg中的VMAF-CUDA相对于CPU异步执行GPU,使其自由执行其他任务。
VMAF评估
我们使用 VMAF-CUDA 测量了两个指标:(1)单帧 VMAF 延迟:计算三个特征提取器以获得单帧 VMAF 分数所需的时间 (2)总吞吐量:计算视频序列的VMAF分数的速度 用于测试的硬件是 56C/112T 双 Intel Xeon 8480 计算节点和单个 NVIDIA L4 GPU。
VMAF延迟改进
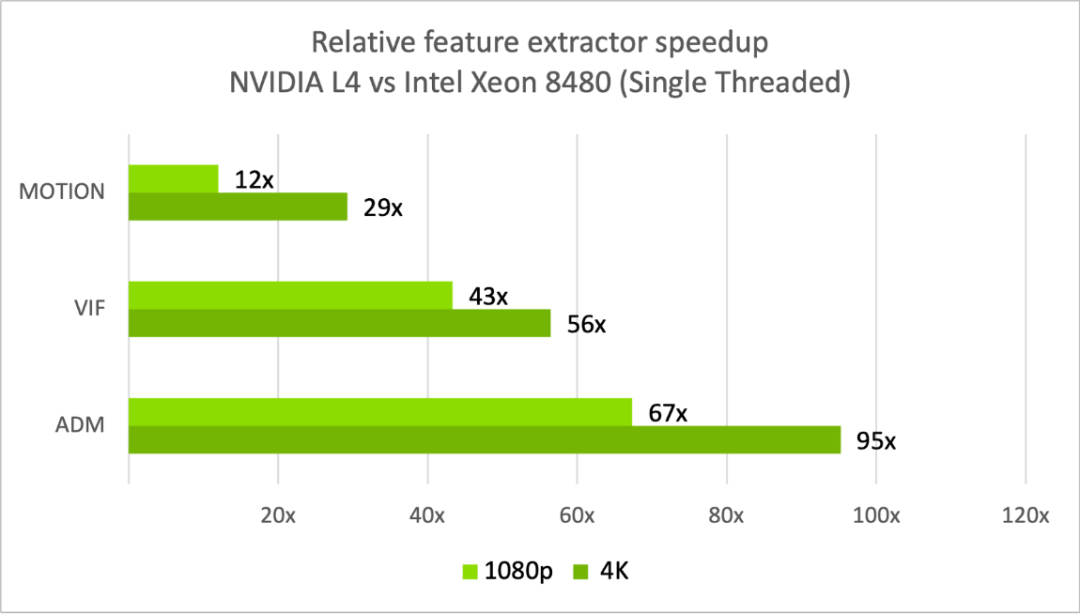
在较低的分辨率(如1080p)下,VMAF-CUDA没有完全利用 NVIDIA L4 的算力。所以在 4K 分辨率下能够看到更大的提升。
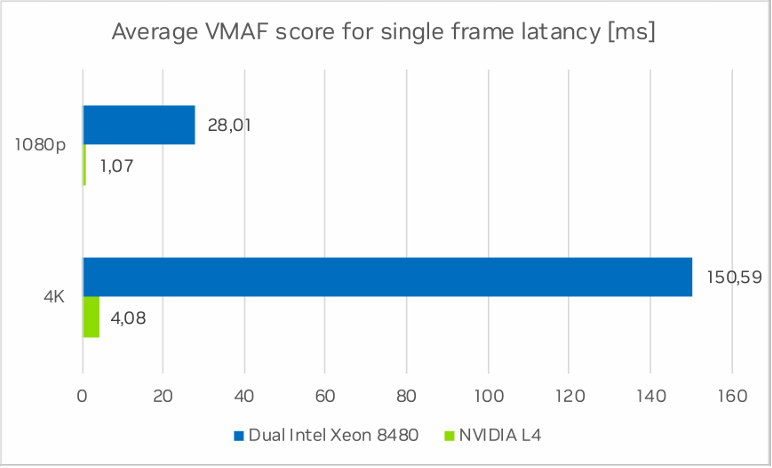
NVIDIA L4 GPU 的延迟时间是每个特征提取器在 GPU 上按顺序运行时的平均运行时间之和。双 Intel Xeon 计算节点的平均延迟时间由最慢的特征提取器决定,因为它们在多个内核上并行运行。计算单帧的 VMAF 分数时,VMAF-CUDA 在 4K 和 1080p 下分别比双 Intel Xeon 8480 快 36.9 倍和 26.1 倍。
FFmpeg性能改进
我们通过计算 FFmpeg 中的 VMAF 来测量吞吐量(单位:FPS)。FFmpeg 可将编码后的视频直接读入 GPU 或 CPU RAM,而不是像 VMAF 工具那样从磁盘读取原始比特流。
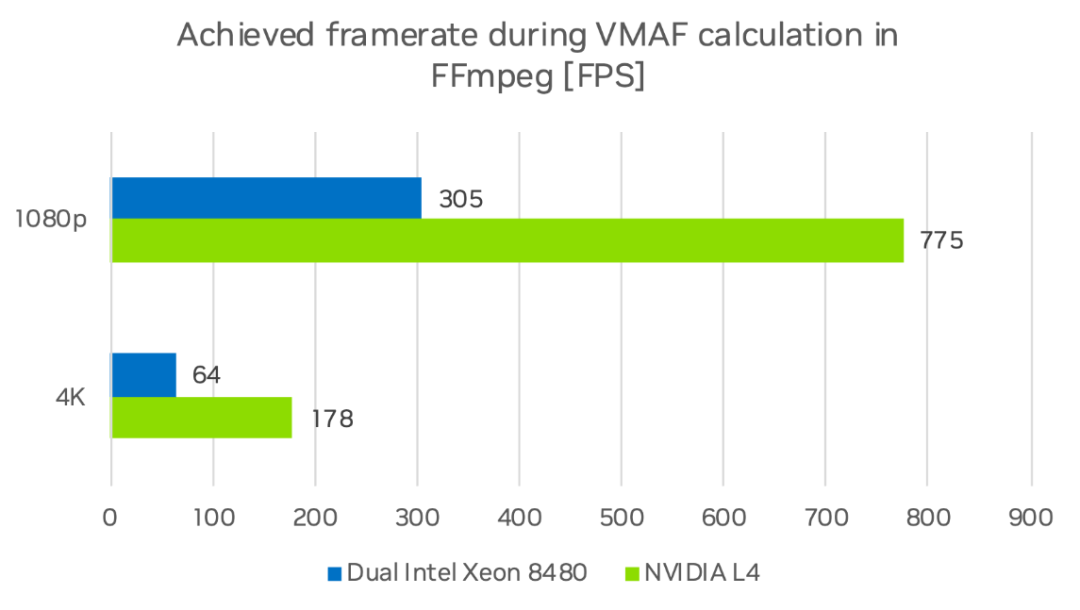
NVIDIA L4 在 4K 和 1080p 分辨率下分别达到 178 FPS 和 775 FPS,而双 Intel Xeon 8480 计算节点在 4K 和 1080p 分辨率下分别达到 64 FPS 和 176 FPS。在处理单个视频流时,4K 序列的速度提高了 2.8 倍,1080p 提高了 2.5 倍。
成本分析
在成本分析中,我们以数据中心常见的标准 2U 服务器为基础进行计算。图 8 展示了基于 2U 双 Intel Xeon 系统总计算性能的测试结果,该测试使用多个 FFmpeg 进程使 CPU 达到完全饱和。图中还显示了 2U 八 L4 服务器的 FPS 数值。
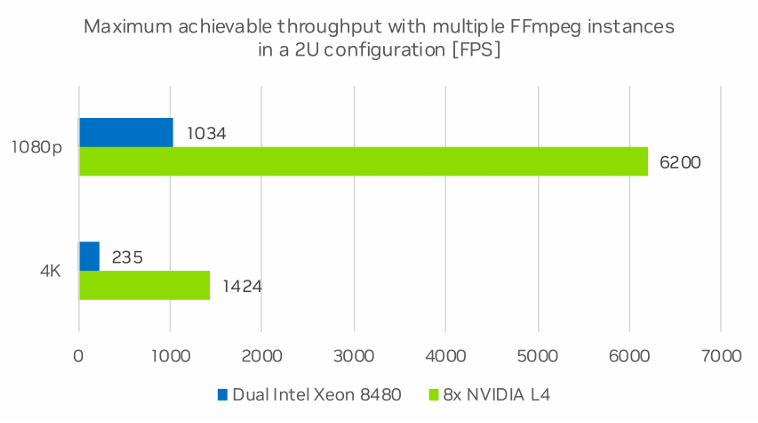
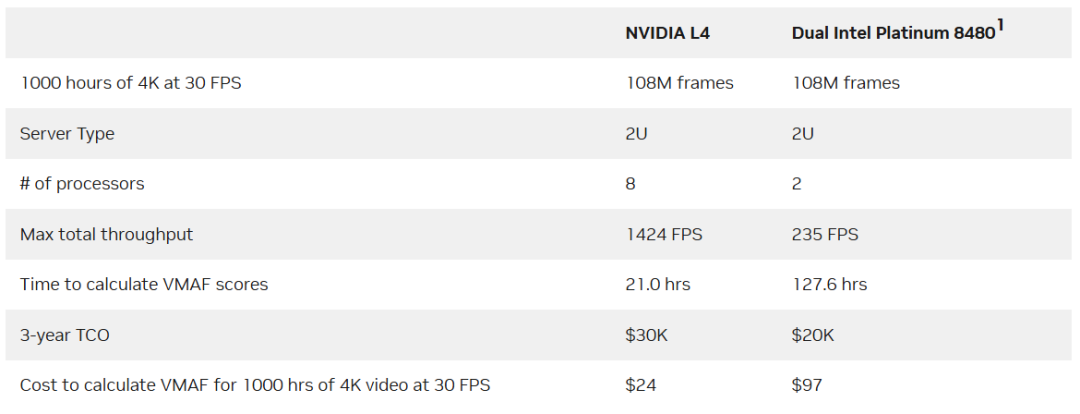
表1列出了 2U 服务器计算相同数量的视频帧的 VMAF 的成本。将 8 个 NVIDIA L4 与双 Intel Xeon 8480 相比,NVIDIA 系统可节省高达 75% 的成本。
成功案例
Snap
目前,Snap 正在将 VMAF-CUDA 用于 Snapchat Memories,以确定特定编码是否符合质量阈值,并在需要时重新转码。VMAF-CUDA 的引入优化了处理流程。以前,VMAF 计算的高计算成本阻碍了 Snap 使用最佳转码设置。但是,有了 VMAF-CUDA,他们可以在每次转码后评估 Snapchat Memories,并以极小的开销使用优化设置重新编码。
V-Nova
V-Nova 正在探索 CUDA 加速 VMAF 计算在多个使用案例中的优势。其中包括其在 LCEVC(MPEG-5 第 2 部分)编码过程中的离线度量计算和实时决策中的实用性。集成 VMAF-CUDA 可以显著加快离线度量计算速度。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
