
转录是现代联络中心活动的重要组成部分,自动语音识别(ASR)系统在很大程度上为其提供了便利。然而,这些工具在准确性和可靠性方面可能存在不足。因此,评估转录质量变得势在必行,而传统的评估过程都是成本高昂的人工操作。大型语言模型(LLM)的出现,为评估和提高自动转录质量提供了一种前景广阔的高效解决方案。
在本篇文章中,我们将探讨 LLM 如何不仅用于评估,而且还用于改进 ASR 系统的输出,从而提供一条通往优质客户服务和运营效率的途径。
自动语音识别是如何工作的?
自动语音识别(ASR)是一种机器学习(ML)技术,可处理音频流并生成文本表示。
这种将音频转换为文本的能力也是其他基于人工智能的功能(如情感分析或生成呼叫洞察和摘要)的基础。因此,大多数提供这些功能的企业就绪型联络中心解决方案也将转录作为其产品的一部分。Contact Lens 就是一个例子,它为 Amazon Connect 实例带来了这些功能和更多其他功能。
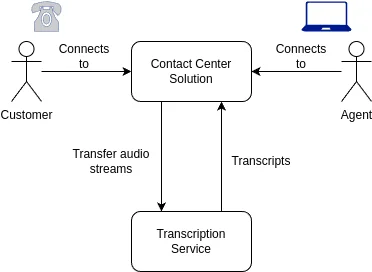
如果您没有使用 Amazon Connect,或者有兴趣为您的 WebRTC 应用程序构建自定义转录机制,您可以使用 Amazon Transcribe 或 Symbl.ai Streaming API 等第三方工具来实现。
整个流程如下:
- 将音频流传输给转录服务。
- 该服务提供转录本。
- 您的应用程序处理文字记录,并将其存储或输入翻译或情感分析等其他流程。
实时和异步 ASR
转录通常有两种不同的方式:实时和异步。尽管这取决于您使用的服务。
- 实时方法包括与转录服务建立连接(通常使用 websockets),以便在生成音频块和接收文本短语时发送音频块和接收文本短语。这种方法适用于实现其他 “通话中 “功能,如字幕、字幕和通话中的代理协助。
- 异步方法包括向转录服务发送通话录音,然后由转录服务提供转录文件。这种方法适用于合规性以及进行通话后分析和深入了解。
影响 ASR 准确性的因素
影响自动语音识别准确性的因素有很多。以下是一些关键因素:
- 语言和口音多样性
- 音频质量
- 语境和特定领域术语
- 说话人分类(谁在什么时候说话)
在初次选择 ASR 系统时,建议您准备一组与业务固有的真实场景类似的测试数据,以便评估真实场景下的转录质量。
例如,您可以使用客户使用不同语言、用户在嘈杂的地方拨打电话或通话中包含医疗或法律术语的以往通话录音。
这些电话的人工转录将成为您用来测试自动转录服务质量的基本事实或参考。
评估转录质量的方法
准备好测试数据后,您可以利用各种 ASR 准确性指标。
其中一个常用的指标是单词错误率 (WER),它计算的是给定音频样本中错误单词转录的百分比。WER 的计算方法是将插入、替换和删除错误的数量相加,然后除以地面实况转录的总字数。
另一种方法是 NER 模型,该模型根据错误的严重程度给予不同的惩罚,从而提供更细致的评估。
这些方法都涉及人工验证过程,有利有弊。从上下文来看,有人类参与其中是有好处的。缺点是,分配惩罚和分数可能会有主观性。这通常也是一项劳动密集型活动。
基于大型语言模型(LLM)的评估是一种替代方案,它将人类对自然语言的理解与人工智能的灵活性相结合。
语言模型的发展
语言模型是机器学习的一种类型,它能理解自然语言,并以类似人类理解和表达的方式生成输出。它们通过统计分析获得语言模式和相关性,然后利用这些知识生成有内涵的文本。
随着时间的推移,语言模型不仅在训练数据的广度上有所扩大,而且在参数的规模上也有所扩大。可以把参数想象成一个内部转盘,通过调整它可以改变模型理解输入和生成输出的方式。
随着语言模型的发展,它们过渡到了大型语言模型(LLMs),这些模型对语言的细微差别和复杂性有更深入的理解,有时在特定情况下还能超越人类。LLM 的一些例子包括 Symbl.ai 的 Nebula、OpenAI 的 GPT-4 和 Anthropic 的 Claude 3。
LLMs 集语言理解、语境感知、错误检测能力、可扩展性、适应性和实时反馈于一身,是评估 ASR 系统转录质量的有效工具。
编写 LLM 提示来评估转录质量
要在任何任务中利用 LLM 的效用,最重要的一步就是编写一个结构合理的提示。在这种情况下,我们需要设计正确的提示来指导它评估转录质量。
第一项建议是采用少样本的方法。这需要向 LLM 提供预期结果的示例。与 LLM 完全依赖训练数据来产生结果的 “零样本 “方法相比,最近的一项研究表明,”少样本 “方法能产生更好的结果。
另一种最佳做法是结合思维链推理。这不仅需要展示示例,还需要展示为转录块准确分配度量的中间步骤。研究表明,采用这种方法可以增强预测效果,并有助于加深对模型推理过程的理解。
在下面的提示中,我为运行 GPT-3.5 的 ChatGPT 提供了几个示例,计算使用 OpenAI Whisper 转录的 Natalia Lafourcade 歌词 “Busca un Problema “一段的 WER。
Reference: busca busca en tus zapatos ya
Transcript: busca busque en tu zapato o sea
Replacements:
* busque replaced busca
* tu replaced tus
* o replaced ya
Insertions:
* sea was added
Deletions: No deletions
WER: 3 Replacements + 1 Insertions + 0 Deletions = 4/6 = 67%
Reference: un cigarro tú lo puedes encontrar
Transcript: un cigarro todo puedes encontrar
Replacements:
* todo replaced tú
Insertions: No insertions
Deletions:
* lo was deleted
WER: 1 Replacements + 0 Insertions + 1 Deletions = 2/6 = 33%
Reference: busca busca a la persona que hará
Transcript: busca busca a la persona que haga
Replacements:
* haga replaced hará
Insertions: No insertions
Deletions: No deletions
WER: 1 Replacements + 0 Insertions + 0 Deletions = 1/7 = 14%
Reference: que tus sueños solo se hagan realidad
Transcript: que tu sueño solo te haga de arriba
让我们看一下 ChatGPT 的输出:
For the fourth set of lyrics, let's first identify the errors between the reference
and the transcript:
Reference: que tus sueños solo se hagan realidad
Transcript: que tu sueño solo te haga de arriba
Replacements:
1. "tu" replaced "tus"
2. "sueño" replaced "sueños"
3. "te" replaced "se"
4. "haga" replaced "hagan"
5. "de arriba" replaced "realidad"
Insertions: No insertions
Deletions: No deletions
Count of errors:
- Replacements: 5
- Insertions: 0
- Deletions: 0
Total errors: 5
Calculation of Word Error Rate (WER):
- Number of words in the reference: 7
- Total errors: 5
WER=Total Errors/Number of Words in Reference=5/7≈71.43%
So, the WER for the fourth set is approximately 71.43%.不出所料,通过提供几个例子和全面的思路来得出答案,GPT-3.5 模型能够对转录进行精确的评估。
代理工作流程
设计模式也可以集成到大型语言模型(LLM)中。这些模式被称为代理工作流,包括反思、工具使用、规划和多个代理之间的协作。这些模式已在各种应用中得到有效运用,并取得了令人瞩目的成果。
最近的一项分析显示,GPT-4 在零次编码任务中的表现优于 GPT-3.5,准确率达到 67.0%,而 GPT-3.5 为 48.1%。不过,采用迭代代理工作流程能显著提高性能,GPT-3.5 在代理循环中实现了令人印象深刻的 95.1% 的准确率。
在将音频转换为文本的过程中,这意味着能够将转录服务的结果导入一个或多个 LLM 模型。这些模型会对转录内容进行改进,如删除填充词、修正语法错误或添加特定领域的上下文,从而使转录更加准确。
这可能适用于实时转录方法,前提是 LLM 能够以足够快的速度生成结果,以便在向用户显示最终文本之前被多个模型使用。
准备好提高 ASR 的转录质量了吗?
将大型语言模型与 ASR 系统集成,为联络中心和其他使用这些工具的企业提供了提高转录流程准确性和实用性的重要机会。通过利用其对自然语言的理解,并采用包括思维链推理在内的 “一拍即合 “方法,企业可以对客户互动进行更可靠、更有洞察力的分析,进而提高服务交付和合规性。
作者:Hector Zelaya
译自:https://webrtc.ventures/2024/05/using-llms-to-evaluate-and-improve-automated-transcription-quality/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/48609.html
