
本文来自公众号:视频云技术【ID:ApsaraVideo】
实时通信中,信号不好怎么办?
随着互联网技术的飞速发展,直播,在线教育,音视频会议,社交泛娱乐,互动游戏等新兴的交互方式正在改变着人们的生活。值得一提的是,它们的兴起都离不开实时通信技术 (Real Time Communication, RTC) 的发展。图 1 展现了 RTC 通信中音频链路的简要流程,主要包含:采集、前处理 (3A)、编码、传输、解码、丢包补偿、混音、播放等环节。
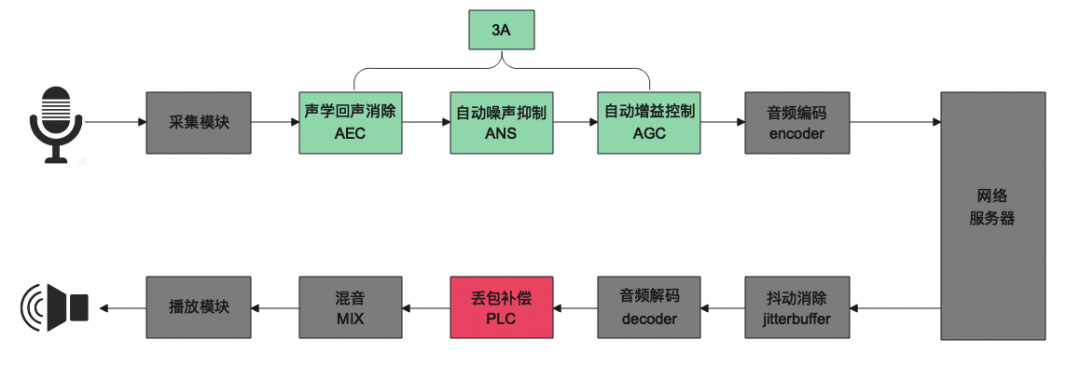
语音信号通过编码压缩技术,在网络上进行分帧传送。然而由于网络环境的影响会导致部分音频包无法传送到接收端,造成语音信号的短时中断或者卡顿,进而影响长时通话过程中的音质和可懂度。为解决以上问题,丢包补偿 (Packet Loss Concealment,PLC) 算法应运而生。PLC 算法可以通过利用所有已得到的信息对丢失的音频包进行恰当的补偿,使之不易被察觉,从而保证了接收侧音频的清晰度和流畅度,给用户带来更好的通话体验。
音频补偿算法业内研究现状
丢包是数据在网络中进行传输时会经常遇到的一种现象,也是引起 VOIP(Voice Over Internet Phone, VOIP) 通话中语音质量下降的主要原因之一。传统的 PLC 解决方案主要基于信号分析原理 [1-2],大致可以分为基于发送端补偿的方案和基于接收端补偿的方案。前者的基本原理是利用编码冗余信息来恢复丢包的内容。
然而,该方法需要占用额外带宽,且存在编解码器不兼容的问题。后者的基本原理是利用丢包前的解码参数信息来重构出丢失的语音信号。传统的 PLC 方法最大的优点是计算简单,可在线补偿;缺点是补偿的能力有限,只能有效对抗 40ms 左右的丢包。应对长时连续突发丢包时,传统算法会出现机械音,波形快速衰减等无法有效补偿的情况。因此,上述传统的 PLC 方法的处理能力满足不了现网业务的需求。
近年来,硬件和算法都有了显著的进步,越来越多深度学习的方法被应用到语音信号处理领域。当然,PLC 算法也不例外。现有的深度 PLC 方法都是在接收端利用深度学习的模型生成丢失的音频包,大致可以分为两个通用的工作框架:
第一个是实时因果处理框架,只使用历史的未丢失帧进行后处理。在进行实时处理时,按迭代方法的不同大致可以分为基于循环神经网络的自回归方法 [3-4] 和基于生成对抗网络的并行方法 [5-6] 两种,但往往涉及较大的参数量和计算量。
第二个是离线非因果处理框架,除了使用历史未丢失帧之外,还有可能使用了包括未来帧的更广泛的上下文信息 [7-8]。离线处理方法通常关注的是如何填充语音信号中的空白,而且通常不考虑计算复杂度,难以在实际应用场景中部署。
智能丢包补偿算法:AliPLC
1. 算法原理在综合考虑业务使用场景,补偿效果、性能开销、实时性等诸多因素后,阿里云视频云音频技术团队研发了实时因果的智能丢包补偿算法:AliPLC(Ali Packet Loss Concealment),采用低复杂度的端到端的生成对抗网络来解决语音在传输过程中的丢包问题。该算法具有以下优点:
- 算法没有任何延时;
- 可以实时流式处理;
- 可以生成高质量的语音;
- 不用单独进行平滑操作就能保证丢包前后音频的平滑和连贯性。
2. 算法性能
AliPLC 算法的参数量为 590k, 在主频为 2GHz 的 Intel Core i5 四核机器上补偿一帧 20ms 的音频数据所需时间为 1.5ms, 在推演的过程中不产生任何延时。
3. 应用场景
| 场景 | 描述 |
| 实时音视频会议 | 实时在线会议中,经常会有声音卡顿,机械音等问题,通话体验较差,可以使用智能丢包补偿算法进行实时丢包补偿,提升会议体验。 |
| 实时直播 | 为了更好的将主播的声音传送给观众,通过使用智能丢包补偿算法,可以使主播的声音更加流畅清晰减少卡顿,从而提升直播效果。 |
| 社交泛娱乐&互动游戏 | 在互动游戏等娱乐场景中用户连麦时,智能丢包补偿算法可以减少卡顿为用户提供更低延时和更流畅的的通话体验。 |
| 弱网环境下的语音通信 | 在地下停车场等弱网环境下的语音通话,经常会出现语音的短时中断或者卡顿,采用智能丢包补偿算法对丢失语音进行补偿,可以极大提升用户的听觉体验。 |
不同方法的波形图对比:
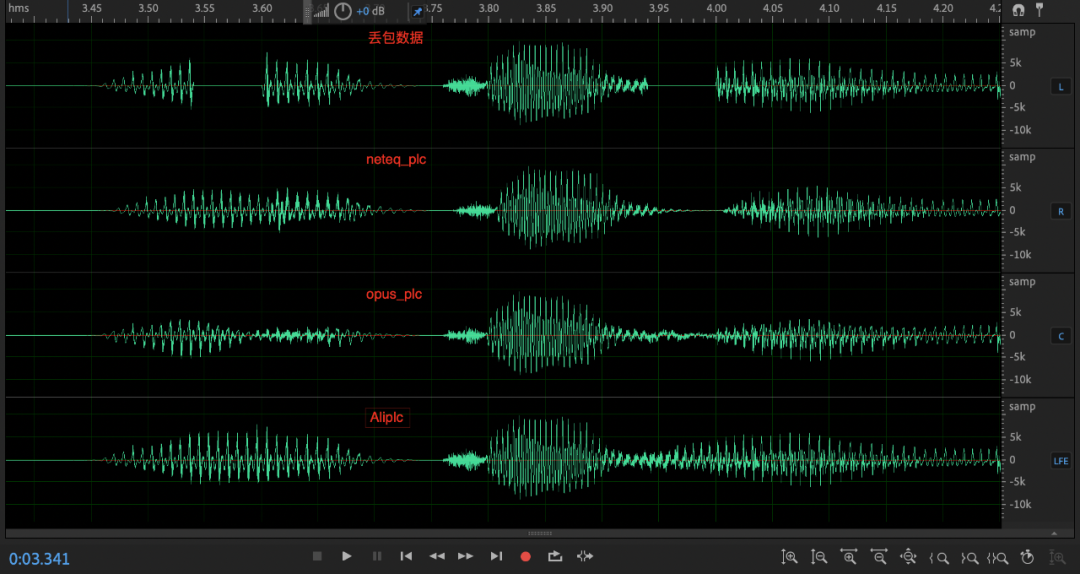
从图中可以明显的看出,在固定丢包 60ms 时,经过 AliPLC 算法处理后的音频的连贯性更好,也不存在衰减等无法补偿的情况。
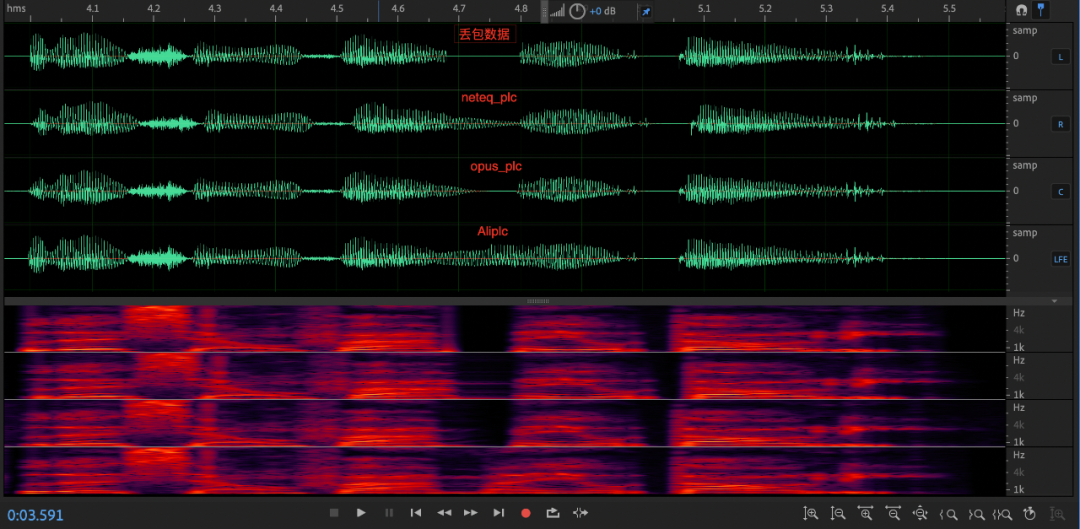
从图中可以明显的看出,在固定丢包 120ms 时,AliPLC 算法的补偿效果较其他算法好一些;neteq_plc 算法通过简单的基因周期的重复和衰减完成丢包补偿,在长时丢包发生时,听起来有很重的机械音,而且会影响未丢包部分的波形;opus_plc 算法的补偿能力有限,只能有效补偿 40ms 左右,多于 40ms 的丢包会被衰减为静音。
AliPLC 客观指标评测
我们采用 POLQA 和 STOI 两种客观指标对不同 PLC 算法的补偿效果进行了测评,在不同丢包率下它们的分数如下图所示。其中横坐标表示丢包率,纵坐标表示分数。POLQA 分数的取值范围为 0-4.5,STOI 分数的取值范围为 0-1,两种客观指标的分数越高,说明补偿后语音信号的质量越好,可懂度越高。
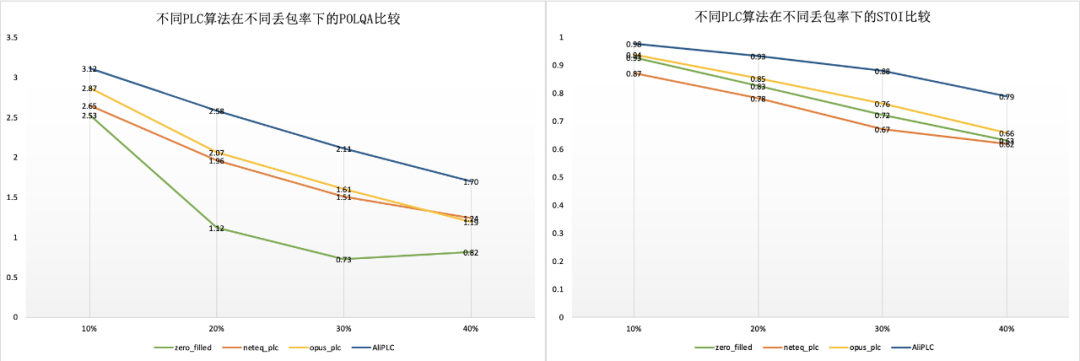
从图中可以明显的看出 AliPLC 算法在 POLQA 和 STOI 两种客观指标上都优于其他 PLC 算法。AliPLC 算法与 neteq_plc 算法相比:POLQA 平均提升 0.54 分 ,STOI 平均提升 21.7%;AliPLC 算法与 opus_plc 算法相比:POLQA 平均提升 0.45 分 ,STOI 平均提升 3.4%; AliPLC 算法在丢包 30% 时的指标比 neteq_plc 算法在丢包 20% 时的指标还要好一些,即 AliPLC 算法可以使接受侧多抗 10%-20% 的丢包。
AliPLC 补偿算法的后续创新
AliPLC 作为阿里云视频云音频技术团队音频解决方案的一部分,充分利用深度学习中 GAN 网络能够有效地生成高质量的音频这一能力,在方法上进行创新,用较低的计算复杂度,提供连续丢包补偿的能力,提升用户在弱网环境下的通话体验。在未来,阿里云视频云音频技术团队将继续探索基于深度学习 + 信号处理的的音频技术,为更广泛的用户创造极致的音频体验。
参考文献
[1] S. M. Kay and S. L. Marple, “Spectrum analysis A modern perspective,” Proceedings of the IEEE, vol. 69, no. 11, pp. 1380–1419, 1981.[2] C. A. Rodbro, M. N. Murthi, S. V. Andersen, and S. H. Jensen, “Hidden Markov model-based packet loss concealment for voice over IP,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 5, pp. 1609–1623, 2006.
[3] M. M. Mohamed and B. W. Schuller, “ConcealNet: An End- to-end Neural Network for Packet Loss Concealment in Deep Speech Emotion Recognition,” arXiv:2005.07777 [cs, eess], May 2020, arXiv: 2005.07777.
[4] F. Stimberg et al., “WaveNetEQ — Packet Loss Concealment with WaveRNN,” 2020 54th Asilomar Conference on Signals, Systems, and Computers, 2020, pp. 672-676.
[5] S. Pascual, J. Serra`, and J. Pons, “Adversarial Auto-Encoding for Packet Loss Concealment,” arXiv:2107.03100 [cs, eess], Jul. 2021, arXiv: 2107.03100.
[6] J. Wang, Y. Guan, C. Zheng, R. Peng, and X. Li, “A temporal-spectral generative adversarial network based end-to-end packet loss concealment for wideband speech transmission,” The Journal of the Acoustical Society of America, vol. 150, no. 4, pp. 2577–2588, Oct. 2021.
[7] O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional Networks for Biomedical Image Segmentation,” arXiv:1505.04597 [cs], May 2015, arXiv: 1505.04597 version: 1.
[8] A. Marafioti, N. Perraudin, N. Holighaus, and P. Majdak, “A context encoder for audio inpainting,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 12, pp. 2362–2372, 2019.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
