
台湾大学、麻省理工大学、卡内基梅隆大学、香港中文大学、微软、Meta、miHoYo的研究团队在 SLT 2024 会议上推出了Codec-SUPERB挑战,旨在公平比较所有现有的编解码模型,并促进更先进编解码技术的发展。
作者:Codec-SUPERB team
比赛注册:https://forms.gle/sBRB4VsoDKkNYQQ98
论文链接:https://arxiv.org/abs/2402.13071
比赛网站: https://codecsuperb.github.io/
公开资料集提交 Evaluation 结果: https://github.com/voidful/Codec-SUPERB/tree/SLT_Challenge
近年来,编解码模型取得了重大进展,开发了许多高性能的神经音频编解码器。理想的神经音频编解码模型应该在低比特率(以千位每秒(kbps)计)下保留内容、副语言信息、说话者及音频信息。然而,哪一种编解码器能最佳地保存音频信息的问题仍未有答案,因为在不同的论文中,模型是在它们选择的实验设置下评估的。本该挑战基于Codec-SUPERB基准,汇集了代表性的语音应用和客观度量标准,全面衡量神经音频编解码模型在不同比特率下保存内容、副语言信息、说话者及音频信息的能力。
1. 介绍
神经音频编解码器最初被引入是为了将音频数据压缩成紧凑的代码,以减少传输延迟。最近,研究人员发现编解码器作为将连续音频转换为离散代码的合适分词器的潜力,这些代码可以用来开发音频语言模型(LM)。神经音频编解码器在最小化数据传输延迟和作为分词器的双重角色突显了其关键重要性。近年来,编解码模型取得了重大进展。在过去三年内,开发了许多高性能的神经音频编解码器。理想的神经音频编解码模型应该保存内容、副语言信息、说话者和音频信息。然而,哪一种编解码器能最佳地保存音频信息的问题仍未有答案,因为在不同的论文中,模型是在它们选择的实验设置下评估的。目前缺乏一个挑战,以公平比较所有现有的编解码模型并刺激更先进编解码技术的发展。为了填补这一空白,我们提出了Codec-SUPERB挑战。
2. 比赛概述
这个挑战的目标是鼓励创新方法和全面理解编解码模型的能力。本挑战将进行全面分析,从应用和信号的角度提供对编解码模型的洞察 [1] [2]。我们为参与者准备了一个易于遵循的脚本,包括开放数据集下载、环境安装和评估。
地址:https://github.com/voidful/Codec-SUPERB/blob/SLT_Challenge/README.md
2.1 资料集
为了促进编解码技术的发展和挑战提交作品的公平比较,我们计划为每个任务提供两个数据集:开放集和隐藏集。隐藏集将始终对参与者保密。开放集用作开发集。参与者可以使用开放集来评估和开发他们的模型。最终结果将基于隐藏集进行评估。
2.1.1 开放资料集
以下列出了我们在本次挑战中使用的数据集。为了解决许可问题,我们替换并删除了原始论文中的一些数据集。我们还仅进行子采样以加快评估速度。
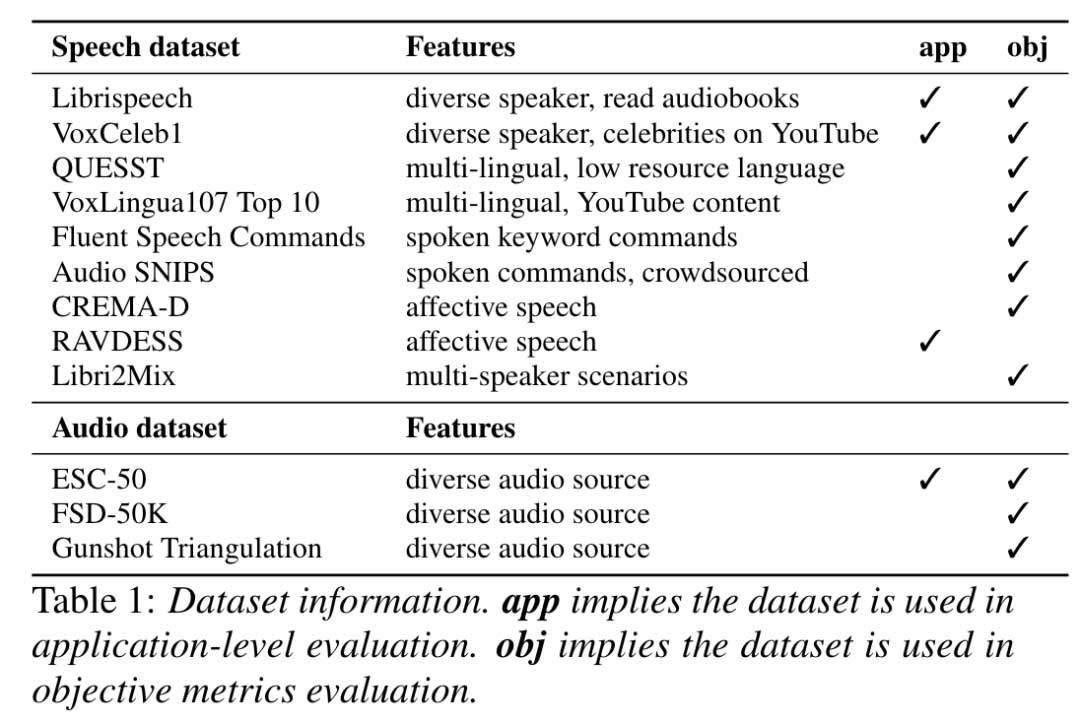
2.1.2 隐藏资料集
另一个数据集由我们新创建,并作为隐藏集维护。隐藏集将包括开放集中所有类型数据集的对应数据集。为了构建这些隐藏数据集,我们与LxT (https://www.lxt.ai) 合作,聘请60名人类发言者(确保性别平衡)朗读句子并录制音频。
2.2 信号等级的客观指标
多种信号级别指标的使用,包括语音质量的感知评估(PESQ)、短时客观可懂度(STOI)、信号失真比(SDR),梅尔频谱损失(MelLoss),使我们能够对音频质量进行全面评估,涵盖频谱保真度、时间动态、感知清晰度和可懂度。
2.3 语音应用
应用角度评估将全面分析每个编解码器在保留关键音频信息方面的能力,包括内容(自动语音识别(ASR)的词错误率(WER))、说话者音色(自动说话者验证(ASV)的等错误率(EER))、情感(语音情感识别的准确度)以及一般音频特性(音频事件分类的平均精度均值(mAP))。
2.3.1 自动语音识别
对于 ASR 评估,我们使用 Whisper 模型来评估各种编解码器在保存语音中的上下文信息方面的表现。我们使用词错误率(WER)和编辑距离作为主要指标。此评估在 LibriSpeech 数据集上进行,特别关注 test-clean 和 test-other 子集。这些指标有助于确定编解码器在重新合成过程中保持口语内容的清晰度和准确性的有效性。
2.3.2 自动语者验证
说话者信息代表了语音中的一个独特且唯一的方面。我们使用ASV(自动说话者验证)来评估由神经编解码器生成的重新合成语音中说话者信息的损失程度。我们使用尖端的说话者验证模型 ECAPA-TDNN 作为预训练的 ASV 模型。我们采用等错误率(EER)作为评估指标,以评估 ASV 在 Voxceleb test-O 集上的表现。EER提供了假接受和拒绝之间的平衡。
2.3.3 情绪识别
除了说话者信息外,语音还传达了包括情感在内的情感信息。我们使用ER(情感识别)来量化由于编解码器模型的语音重新合成造成的副语言信息损失。我们使用emotion2vec 来评估一个著名的情感数据集RAVDESS。
2.3.4 自动事件分类
AEC任务的目的是评估不同编解码器保持音频事件信息的能力。这是通过使用预训练的 AEC 模型对重新合成音频的音频事件进行分类来实现的。我们使用预训练的对比语言-音频预训练(CLAP)模型在 ESC-50 数据集上进行测试。
3. 提交结果
我们的主要关注点是与社区分享观察和洞察,而不仅仅是排名。
公开资料集
参与者应通过在GitHub上创建一个 Issue (https://github.com/voidful/Codec-SUPERB/tree/SLT_Challenge) 来提交所有客观指标和应用的评估结果,以及所采用的比特率。
隐藏资料集
- 如果可以发布模型Checkpoint,参与者可以提交一个脚本,该脚本指示可用的比特率选择,将Waveform 路径作为输入参数,并重新合成Waveform。
- 如果模型 Checkpoint不能发布,参与者可以提供一个API。组织者将使用该API选择提交的编解码器模型支持的可用比特率,输入Waveform,并重新合成Waveform。
4. 论文提交
在 SLT 2024 会议上,将专门设有一个致力于 Codec-SUPERB 挑战的特别会议。参与 Codec-SUPERB 挑战的参与者可以选择通过常规提交系统提交论文,该系统将经过SLT同行评审过程。此外,挑战参与者还可以选择将描述其系统的论文提交到专门的挑战会议记录中。挑战的组织者将审核这些提交。虽然接受的系统描述论文不会被IEEE索引,但作者将有机会在研讨会的特定会议上展示他们的工作。
[1] Wu, Haibin, et al. “Towards audio language modeling-an overview.” arXiv preprint arXiv:2402.13236 (2024).
[2] Wu, Haibin, et al. “Codec-SUPERB: An In-Depth Analysis of Sound Codec Models.” arXiv preprint arXiv:2402.13071 (2024).
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
