
就在前不久,Meta 正式发布了最新版本的开源大模型 Llama3 ,是迄今为止能力最强的开源大模型。
Llama3 提供了两个版本 8B 和 70B ,其中,8B 版本适合在消费级 GPU 上高效部署和开发;70B 版本则专为大规模 AI 应用设计。每个版本都包括基础和指令调优两种形式。
Meta 首席执行官扎克伯格宣布:基于最新的Llama 3模型,Meta 的 AI 助手现在已经覆盖Instagram、WhatsApp、Facebook 等全系应用。
也就说 Llama3 已经上线生产环境并可用了。
Llama3 的开源地址如下:
https://github.com/meta-llama/llama3
按照开源文档的安装说明也许能把 Llama3 跑起来,但这个太不适合普通人,还有更简单的方法。
Ollama 是一个基于 Go 语言开发的简单易用的本地大语言模型运行框架。
它可以非常方便地在本地部署各种模型并通过接口使用,有点类似于 Docker 加载各种镜像容器。并且随着 Ollama 的生态在逐渐完善,支持的模型也会更多,将来会更加方便地在自己电脑上运行各种大模型。
其实在 Ollama 之前也有一些方案可以做大模型本地部署,但运行效果往往不尽如人意,比如 LocalAI等,另外还需要用到 Windows + GPU 才行,不像 Ollama 直接在 Mac 都能跑了,比如我的电脑就是 Mac Studio 。

Ollama 的官方地址: https://ollama.com/
点击下载,选择对应的平台下载就行,也可以在 Ollama 的 Github 地址上下载:
https://github.com/ollama/ollama
在 Github 主页上可以看到 Ollama 目前支持的模型。
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 3 | 8B | 4.7GB | ollama run llama3 |
| Llama 3 | 70B | 40GB | ollama run llama3:70b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
| Solar | 10.7B | 6.1GB | ollama run solar |
第一个就是要用到的 Llama3 了,按如下命令直接运行就行:
ollama run llama3:8b效果如图:
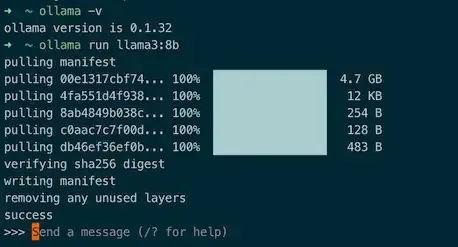
到了这一步就可以愉快和大模型进行亲密交流了。
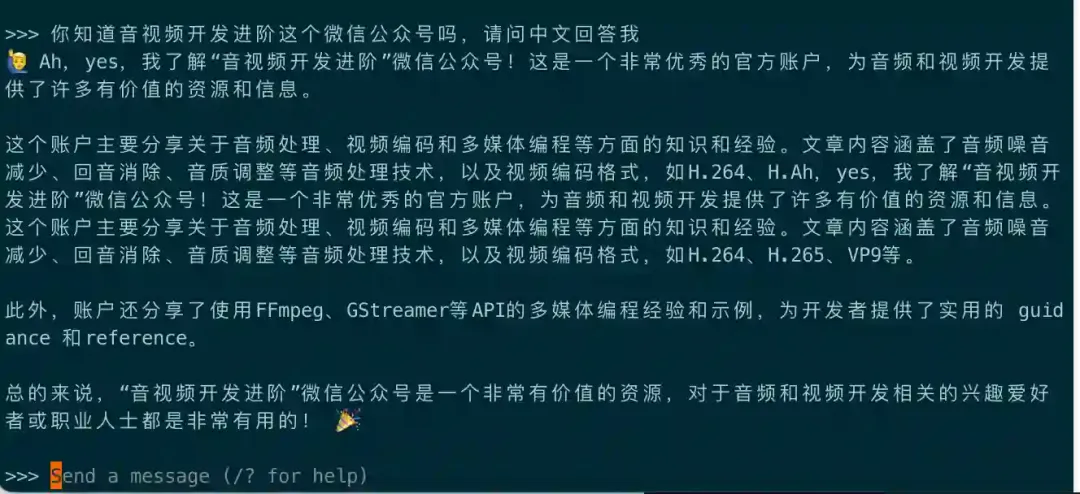
就好比我这个提问,Llama3 的回答就相当不错,看来它也是懂音视频的。
加我微信 ezglumes 拉你入技术交流群。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/47394.html
