
本文提到大模型通常的工作方式,即通过提示词进行问答,并指出了两个主要问题:历史对话信息的管理和令牌数量的限制。文章讨论了知识库问答和个人助手两个应用场景,并分析了各自面临的困境,如知识库无法有效处理多模态信息和大型文档,个人助手则受限于工具参数的复杂性和令牌长度。文章还提到了微调(FINE-TUNING)作为改善模型性能的方法,以及在不同领域的应用潜力。最后,分享了对微调成为标准操作流程的预期,以及对现有平台和基础设施的改进意见。
作者:锋凌
来源:大淘宝技术
01 背景
当下LLM大模型如火如荼的进行着,各大互联网厂商基本都有在训练&推出自研的大模型,chatgpt,千问、moonshot的kimi。基于这些大模型也涌现了出了很多的应用。但是当前还未出现现象级的应用,妙鸭相机算一个,但是也很快昙花一现。笔者由于业务场景的诉求,也探索了一下基于大模型的Agent 的方案,尝试在实际业务场景的使用一下。但是发现现实还是有一定的差距。
在基于Agent 的方案,目前有很多的开源框架,如:
- langchain:一个基于大模型应用开发框架,能够让应用的开发者基于大模型的推理结合存储、工具、索引、提示词等模块完成个人助理、任务、问答类的应用开发。主打的是单个Agent 的服务能力整合。基本上现在很多的AI 应用当前的思路都有参考这个。
- autogen:微软开源的agent 框架。如果我们把langchain 看做是和人交互的agent, 那autogen就是agent 和agent 交互协作共同完成一个目标的多agent 的任务框架。人类只需要提供一个目标给到autogen, 他就能够在agent 通过多轮对话、执行完成目标。
- metagpt:官方介绍是 “MetaGPT是一款强大的开源软件,它利用多智能体框架(产品设计、技术设计和程序员)来处理你的需求。只需输入需求,MetaGPT就能规划、设计并生成产品文档、测试代码和主运行代码,让你立即开始运行你的软件。多智能体比单一智能体更高效、更灵活。这是AI技术的一大突破,让软件开发变得更便捷、更高效。”
好了,说的再天花乱坠,还是得看实际行不行,我们就拿langchain 的最拿手的两个应用场景来说,一个是知识库问答,一个是个人助手来看看。
在讲这两个场景,之前我们要先熟悉大模型的工作姿势:
通用的大模型的工作姿势,是提示词 => 大模型 => 大模型基于提示词给出问答。
提示词Prompt 的一般格式:
PREFIX = """Answer the following questions as best you can. You have access to the following tools:"""
FORMAT_INSTRUCTIONS = """Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question"""
SUFFIX = """Begin!
Question: {input}
Thought:{agent_scratchpad}"""简单来说,就是告诉大模型按照特定格式回答我的问题,可以使用的工具,参数格式等等吧。。。重点是要求大模型按照特定的范式工作,输出结果。上文是chat 场景下MRKL 模型的Promopt ,有兴趣的可以看看背后的论文MRKL。
MRKL地址:https://arxiv.org/pdf/2205.00445.pdf
在实际的运行过程中,我们的参数会被填充到对应的数据,例如tool 会被替换成工具的信息,input 的信息,包括历史的会话信息等,如下图所示:
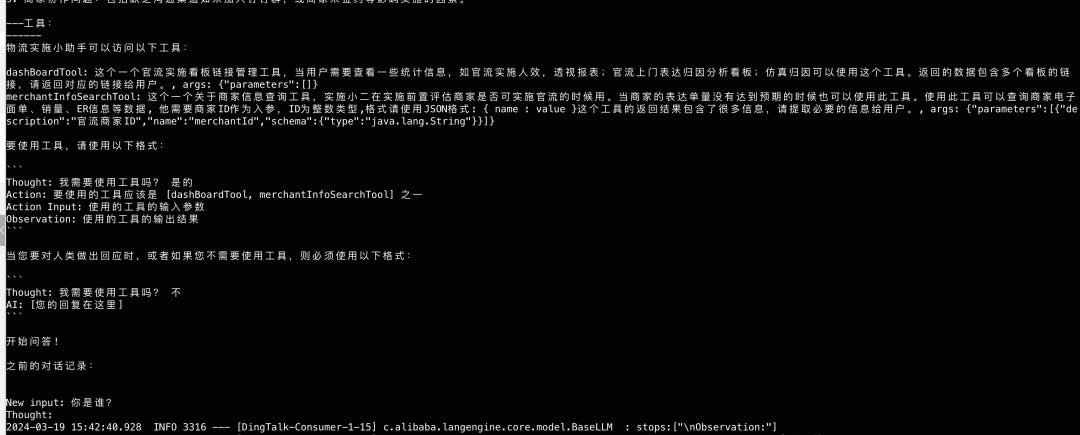

这地方有两个问题:
- 第一个问题,历史对话信息,LLM 没有,所以agent 等框架一般都有memory 的能力,每次调用大模型都需要把历史的对话信息拿出来,放到prompt 中;
- 第二个问题一次调用的tokens 有限,这个问题其实很致命。如果遇到知识库相关的tokens 非常的多场景,怎么解决尼?总不能每次把知识库的信息都全量带过去吧,解决方案一般有两种,第一种就是每次只把相关的信息带过去,也就是下面通用的知识库方案。还有一个种是提前微调,fine-tuning 的模式来做,利用先验知识解决专家问题。
02 知识库的效果
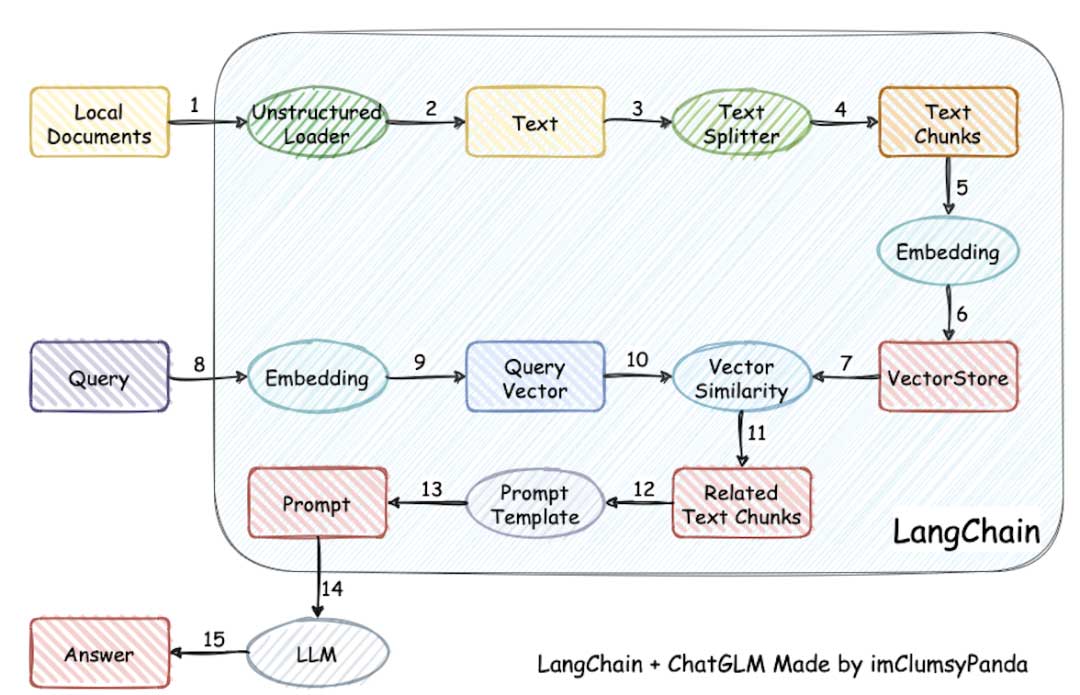
上面这个图,估计很多同学都看过,大家把PDF、语雀文档、WORD 之类的文档,进行分割、embedding、存到向量数据库中,在问答环节,拉取相关的块,再构建prompt 给到大模型,再让他输出对应的问答。
本质解决两个问题,tokens 数量限制的问题;提炼精准问题的能力。
- Text Splitter :文本分割器是一种将大段文本拆分成较小块或片段的算法或方法。其目标是创建可单独处理的可管理的片段,这在处理大型文档或数据集时通常是必要的。
- Embedding: 简单来说就是向量化,不同维度的数据,最终都需要通过归一化、自关联。当然,这个做的最好的就是chatgpt 的 text-embedding-ada-002 了,其实chatgpt 的能做的比别的大模型好,很大程度下受他的Embedding结果的影响, 在Transform 模型下,多头注意力非常依赖Embedding 的好坏。
- vectorstore: 向量数据库,就是存储刚刚嵌入后的向量了,一般的向量数据库都可以了,如holo, redis 等,支持计算欧式距离、向量内积等。
原理很简单,集团内部现在知识库的机器人接入没有几千,估计也有几百了,在一些基础问题上,它还能回答的差不多,但是在复杂问题上,还没有看到一个非常厉害的知识库机器人出现。
03 知识库的困境
第一个问题是大家进行向量化的知识库文档里面其实很多时候是包含很多图片,在表达语义能力方面,图片往往包含的语义更多,图片处理的时候可能就变成一个链接了,更有甚者,包含视频,又该如何处理,所以文档处理不能简单的做NLP处理,还得支持多模态,目前好像还没有看到这样的能力出现。下图中,其实就是一个示例。

第二个影响结果的就是文档的大小,如果知识库过于庞大,在分割完成后,召回的数据也会过多,必然存在舍弃导致的信息不全。不过这种情况可以通过尝试多路调用,再整合的思路解决。
另外使用的姿势也有相关性,如果问题没有区分度,返回的结果也存在泛化的问题。知识库能力有个特点,就是你提供给我的知识一定是要准确有用的,因为作为使用方,如果你一会给我的有用,一会给我的是错误的,作为用户我就不会用了,我不是专家,我没有办法判断结果的正确性。这个和专家助手是不一样的心智。
04 个人助手的效果
个人助手的基本逻辑就是,输入后,组装参数,告诉大模型目标以及工具描述,让大模型告诉我们是否应该使用工具,以及使用哪个工具,这个过程中,大模型还会帮我们构建工具参数(前提是工具要描述清楚参数的类型),langchain 根据工具和参数调用,拿到结果后,再次调用大模型。这个一个基本的ReAct 的思路。具体可以参考论文: ReAct ReAct地址:https://arxiv.org/pdf/2210.03629.pdf
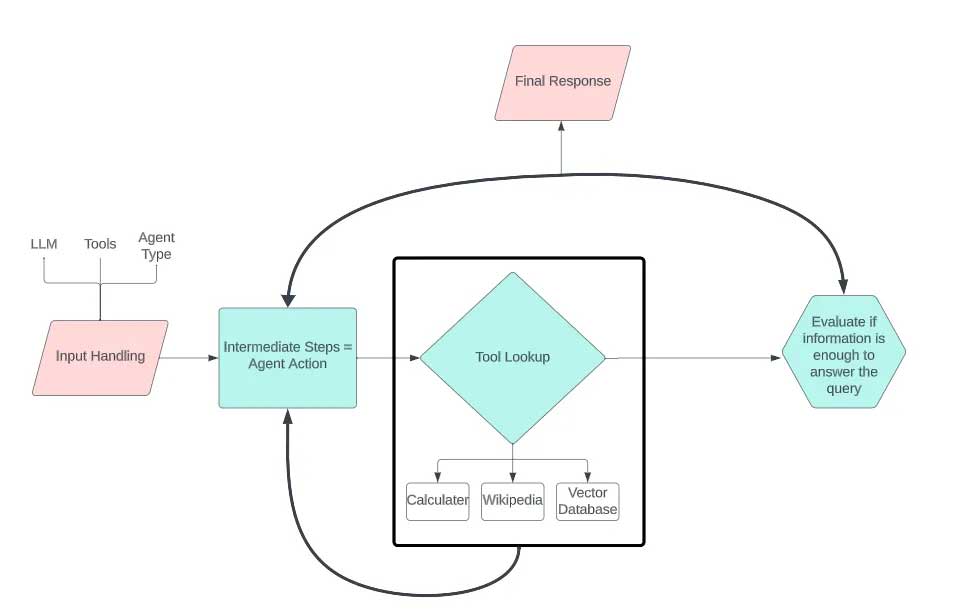
其实按照这个思路,如果写好Prompt, 再把工具的描述写清楚,你会发现这个还是的确能够产生一些价值的,至少在辅助工具助手上,他还是可以做到不错的效果的。例如查个白名单、订单信息、等等吧。
05 个人助手困境
- 他的一个明显的困境就是工具的参数不能太复杂,由于是大模型推荐的结果得出的参数,即使是最新的gpt 在参数映射这一块,都容易出现问题,哪怕是个String 类型的数组,都容易出现格式不一致的问题。所以工具的入参要足够简单,不然那个转化和校验就痛苦死了。
- 由于每次调用都是带着全量的History, 所以如果背景知识过多,一样会存在tokens 过长的问题。就像你想让一个让帮你做客服的事情,首先他得了解足够多的先验知识,由于没有做微调,所以每次都是带着全量的信息过去,模型处理的也慢。
所以最终的最终,想要好的效果,还是需要准备好足够清晰的业务领域知识(多模态的),做Fine-Tuning。
06 Fine-Tuning 的困境
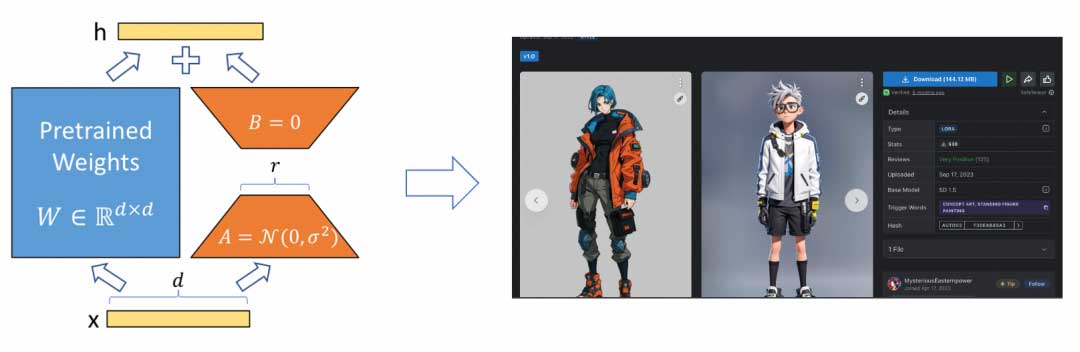
在说NLP 领域的的fine-tuning 之前,我们可以先说说文生图领域的fine-tuning。目前文生图领域有个非常火的网站叫C站. 他上面全是基于LORA的思路(可参考论文LORA)做微调模型。基本拿SD 的基础模型,再加上微调模型和Promot 很容易就能生成对应风格的图片。
可参考论文LORA地址:https://arxiv.org/pdf/2106.09685.pdf
- 等到开源的基础大模型的推理能力达到chatgpt4 的水平,为了解决各个专业领域问题(你也可以叫风格、领域知识、上下文背景),微调会成为一个标准操作流程。但是能不能形成一个类似C站的氛围还不好说,毕竟图片的风格是通用的,大家可以相互借鉴,而专业背景各个产品各有不同。
- 基于大模型的能力,在精确计算领域还是很难落到很好的效果,典型的如复杂工具的调用。但是在专家助手的领域能够获得很好的效果,典型的如代码生成的Copilot。虽然生成的代码不能保证一行都不需要修改,但是它能实现80%的有效代码,基于自己的专家知识修改有问题的20%, 那也是巨大的省力呀。
- 最后再说一下钉钉,目前的钉钉已经支持流式stream ,可以很方便的实现大模型打字效果了,大家可以试用一下。
团队介绍
淘宝物流基础技术团队,一直深耕在物流及供应链的数字化协同与运营领域:为零售业务提供灵活多样的经营模式管理方案及可以快速适配市场变化的经营策略数宇化管理工具;为商家提供高效低成本的物流及供应链解决方案,加快资金效率,提升协同效率;为消费者提供即时便捷的购物体验。基础技术团队打造了一个技术先进,产品矩阵完整的PaaS平台,以及AI驱动的基础研发框架,帮助业务系统实现架构升级,助力提升业务开发研发效率和技术实战能力。最终支撑和驱动庞大、复杂、多变的商业体系发展。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。