
本文介绍我们最新发表在 ACM MM2022 会议的工作,使用多尺度由粗到精 transformer 的视频插帧方法。在该论文中,构建了一个两阶段的多尺度视频插帧结构,分别主要进行运动估计及特征迁移。在第一阶段使用纯时空卷积的方式提取隐式运动信息,以避免预设运动模型来估计光流。在第二阶段采用 transformer 网络,利用自注意力机制估计整数帧与中间帧的多对一映射来提升特征迁移的鲁棒性。
论文标题:Multi-Scale Coarse-to-Fine Transformer for Frame Interpolation
发表会议:ACM MM2022
作者:Chen Li,Li Song,Xueyi Zou,Jiaming Guo,Youliang Yan,Wenjun Zhang
论文链接:https://dl.acm.org/doi/abs/10.1145/3503161.3548011
视频插帧目的是从低帧率视频中合成不存在的中间帧以提升帧率,使得视频更加流畅,顺滑。随着显示设备的更新换代,以及人们对视频观赏体验要求的提高,不管是在视频、慢动作采集,新视角合成,视频点播、直播的场景中,高帧率视频的需求越来越大。然而,受限于采集设备与存储,现存的旧视频源往往具有较低的帧率。在播放时,低帧率视频在运动的场景或者区域中往往会造成感知上的不连续,从而影响人眼的主观视觉体验。现有的视频插帧方法大多为基于流的方法,即估计出整数帧到中间帧的密集光流,再通过估计的流将特征迁移到中间时间点,最后通过残差估计合成中间帧。
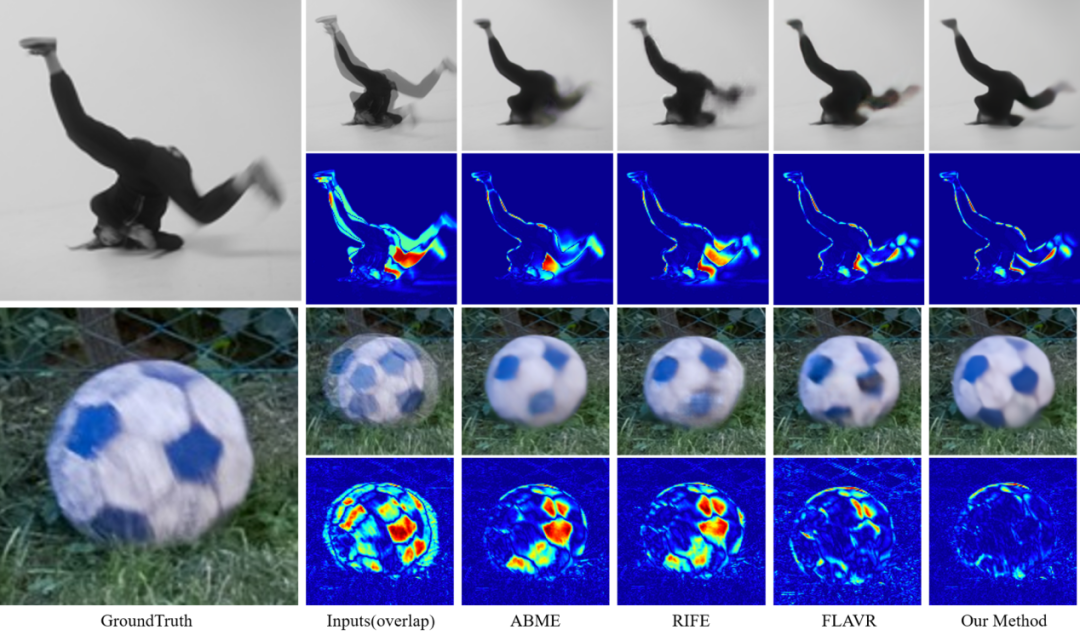
然而,这类方法通常具有两个问题:首先,在运动估计过程中,基于流的方法通常需要预设一个运动模型(线性,二次,三次)。当遇到较为复杂的运动场景,或者当前帧某些区域具有较为复杂的非线性运动。这些低次的运动模型较难实现有效的运动估计,估计的流也不够准确,进而影响迁移特征的正确性以及最终合成帧的准确性, 如图1。第二个问题在于特征迁移过程中,光流可以看做一种像素间的一对一映射,其性能极大取决于运动估计的准确性,对于误差的容错性较低。如果运动估计不够准确,特征迁移的性能也将会被极大影响。如图2,ABME在得到锚帧之后,基于此进行流估计再特征迁移,当锚帧的误差很大,或者伪影明显时,造成匹配流的不准确,进而使得最终生成的中间帧含有较大的伪影误差。


方法简述
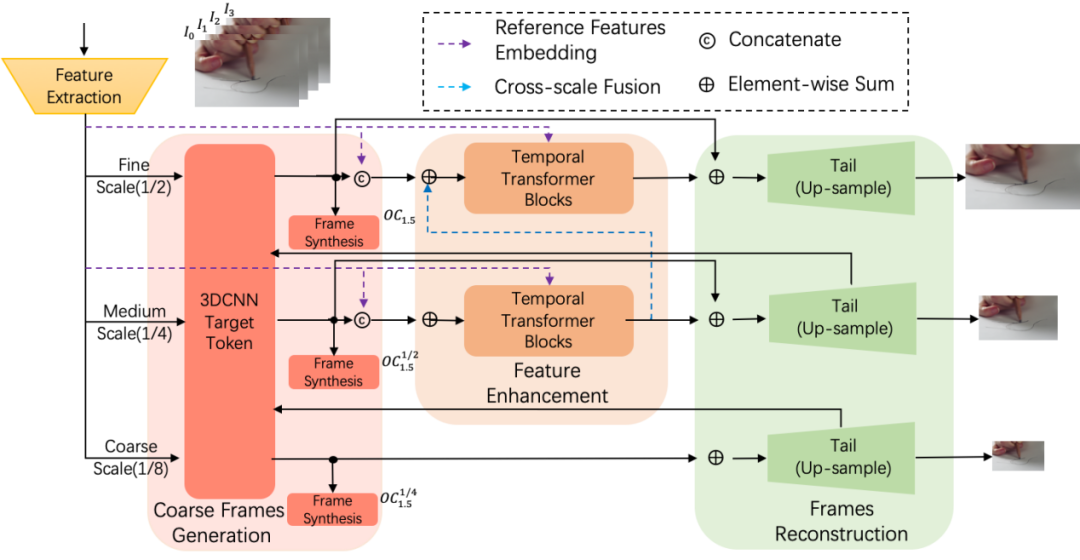
本方法的流程图如图2所示,主要由三个模块组成:粗中间帧特征生成,中间帧特征增强以及帧重建模块组成。首先对连续输入4帧进行特征提取,这里采用3层2D卷积,每一层进行特征提取的同时进行下采样,同时每一帧共享卷积参数。接下来在每个尺度,使用网络进行隐式地运动估计以及粗中间特征帧合成。得到的粗中间帧特征进而对于特征细化模块进行指导,采用cross attention机制搜寻整数帧的精细特征进而细化。得到的细化特征最终经由帧合成模块得到最终的中间帧。
粗中间帧生成模块
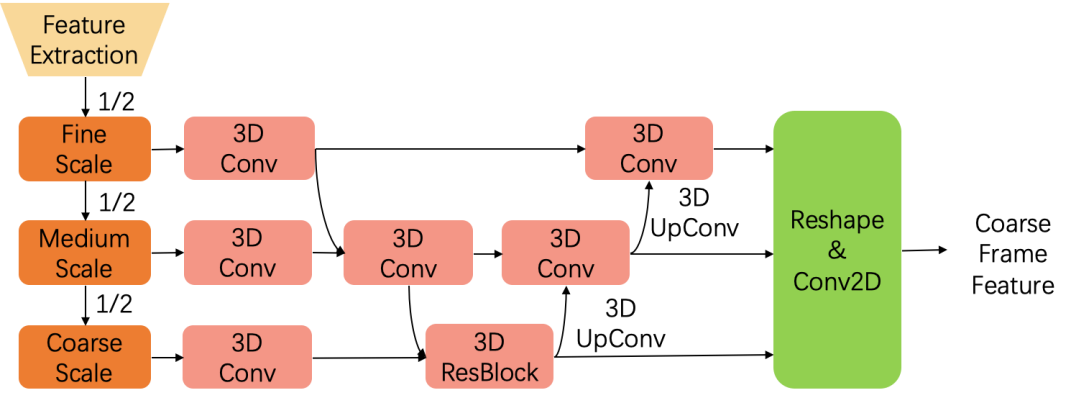
如上文所述为了避免使用预设的运动模型,这里采用隐式的方法,不对中间流进行显式地估计。具体来说,在该模块中使用多尺度的时空卷积让网络自适应学习运动建模,进而直接合成粗的中间帧特征。为了保证运动估计的感受野,该模块在较低分辨率的特征基础上进行估计。该模型采用纯卷积的结构,提升了运动估计的自由度,可以在第一阶段保证生成的中间帧具有更为精准的结构。
中间帧特征增强模块
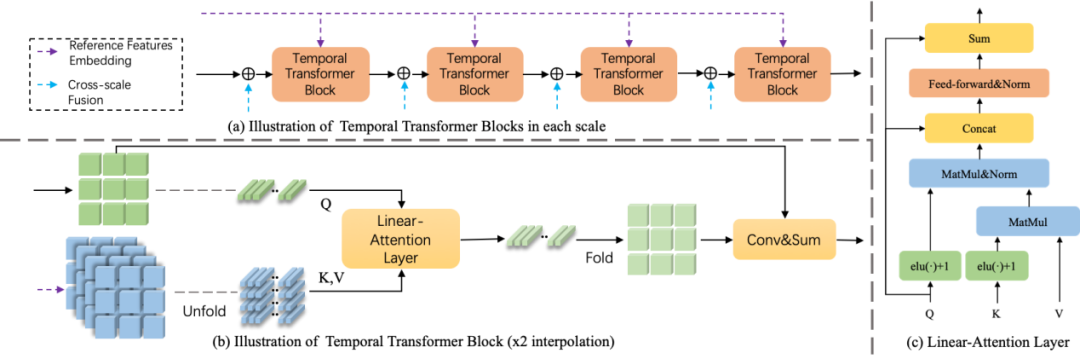
有了前一模块生成的粗中间帧特征,可以将其视为锚帧,搜索相邻帧上的相似特征来进行特征迁移。特征迁移可以使用基于流的方式,然而流的方式需要估计一对一的光流,在中间帧有伪影,或者是遇到遮挡时,无可避免会产生误差,造成误差累计。因此这里使用基于transformer的方式,即估计patch之间的关联。再利用cross attention,产生多对一的映射,利用加权和的方式来提升特征迁移的鲁棒性。同时为了提升特征迁移的精细程度,对于连续多个transformer block,patch尺寸由大到小进行设定。这里使用linear attention来提升效率。linear attention相较于最原始的attention,主要是利用线性非负的核替换了使用softmax操作的指数核。即图中的elu(·)+1。
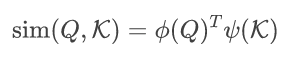
通过图4右侧的计算图,首先计算,因为特征的D维度要小于N维度,这样计算量就会从O(N^2)降到线性O(N)。
帧合成模块
帧合成模块使用基于RDN的模型,以实现特征的上采样及最终帧合成。残差密集连接层将从浅到深层的输出特征进行融合,有效减小了前向传播中的误差损失。
约束函数
在该网络中,对粗中间帧及细化模块分别进行约束。对GT帧进行下采样得到每个尺度的真实值,通过L1 loss进行约束。
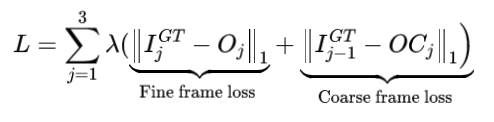
模型效果
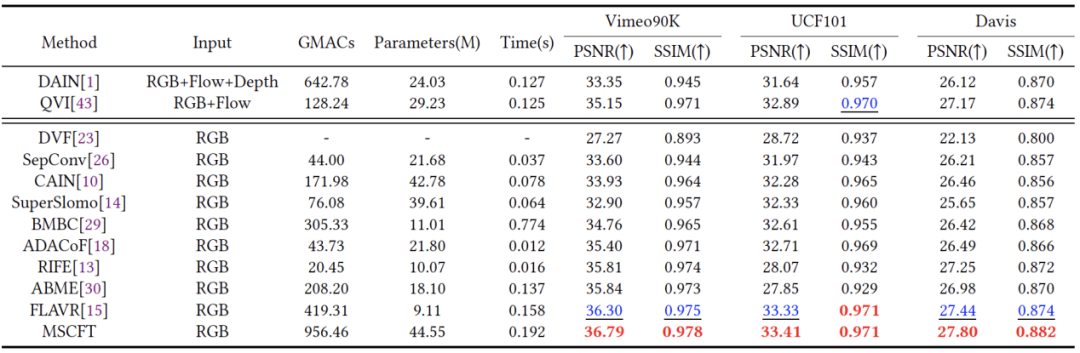
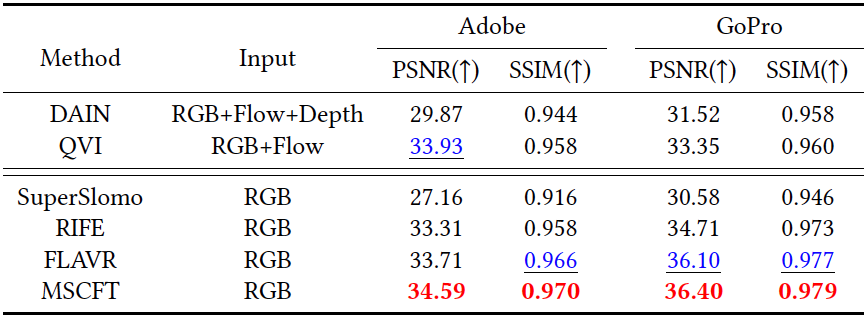
该模型的效果分为客观主观两个维度进行评测。首先在客观指标上,我们分别对单帧插值和三帧插值进行评测,在所提到的数据集中,本方法均超越了前面的方法。同时在主观上,我们的方法预测了最准确的结构及运动轨迹,如图6,第一行为生成的中间帧,第二行为与GT 的误差可视化图。最后,我们提供了一段慢动作视频来证明我们方法再多帧插值上的优势。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
