
本文介绍本课题组最近一篇隐式视频表征(NeRV, Neural Representations for Videos)领域的工作,《Boosting Neural Representations for Videos with a Conditional Decoder》,收录于CVPR 2024 (Highlight)。本推文将介绍本工作的研究背景与动机,引出本工作提出的方法算法,展示该方法的实验结果,最后进行总结。
本文的arxiv版本见:https://arxiv.org/abs/2402.18152
代码见:https://github.com/Xinjie-Q/Boosting-NeRV
01 研究背景与动机
隐式神经表征(Implicit Neural Representation,INR)因其准确表示不同多媒体信号的卓越能力而受到广泛关注,包括音频、图像 和 3D 场景。INR通常使用紧凑参数化神经网络来学习隐式连续映射,将坐标转换为目标输出(例如,RGB值、密度)。这种新型的神经表示开辟了许多潜在的应用,包括数据修复, 信号压缩和高级生成模型。
鉴于 INR 的简单性、紧凑性和效率,一些研究建议将 INR 应用于视频压缩。与传统的和最近的神经视频编解码器不同,NeRV [1] 用神经网络来表征视频。作为帧索引 的函数,并将视频压缩构建化为基于模型的过拟合和压缩。这种创新方法显着简化了编码和解码过程。基于这个范式,一系列后续工作[2, 3]致力于设计更有意义的嵌入来提高视频重建的质量。
然而,有几个重要的限制阻碍了现有隐式视频表征的潜力。本文将对以下几点进行改进,并提出一个通用性的增强框架: (1) 在解码第t帧时,先前方法仅依赖于第 时间嵌入来确定身份信息[1, 3],这使得很难将中间特征与目标框架对齐。 尽管有一些方法[2]引入了 AdaIN 模块[4]来调制中间特征,但这将归一化和条件仿射变换结合在一起,其归一化操作可能会降低神经网络的过拟合能力,从而导致性能增益有限。(2) 先前方法中使用的激活函数如GELU不能完全激发网络的表征性能[1, 2, 3]。(3) 先前方法依赖于 L2 损失 或 L1 和 SSIM 损失的组合来过拟合视频,但它们经常无法保留视频 高频信息(例如,每帧内的边缘和精细细节),从而降低重建质量。 (4) 大多数视频 INR 遵循 NeRV 在视频压缩任务中采用三步模型压缩管道(即剪枝、量化和熵编码)[1, 3]。 然而,这些组件是单独优化的,这阻碍了INR实现最佳编码效率。 尽管有一些方法[5, 6]探索了量化和熵编码的联合优化,但它们面临着训练和推理阶段使用的熵模型不一致所带来的严峻挑战,导致次优的压缩性能。
02 方法介绍
如图1所示,我们提出的增强视频表征架构包括两个主要组件:嵌入生成器和条件解码器。 嵌入生成器的选择取决于特定的视频 INR 模型。 为了易于理解,我们以 HNeRV [3]为例。 值得一提的是,通过选择适当的嵌入生成器,我们的增强框架可以轻松推广到其他表示模型(例如,NeRV [1]、E-NeRV [2])。

图1 我们提出的带有条件解码器的 HNeRV-Boost 框架。内容相关的嵌入 yt 在第 1 阶段扩展其通道尺寸,并在第 2 至 6 阶段进行上采样。最后三个阶段堆叠两个具有较小内核大小的 SNeRV 块以获得更少的参数,其中前者上采样特征,后者细化了上采样的特征。
时间仿射变换(Temporal-aware Affine Transformation, TAT)层: 先前的方法使用 AdaIN模块[4]来更改中间特征的分布。 然而,AdaIN 模块耦合了归一化和条件仿射变换。 归一化操作通常用于防止神经网络中的过度拟合,这与利用过度拟合来表示数据的视频 INR 相冲突。为了克服这个限制,我们提出了一个没有归一化的时间仿射变换(TAT)层及其相关的残差块,以释放特征对齐的潜力。 图2(左)说明了我们的 TAT 残差块的细节。 基于外部的时间嵌入 ,TAT 层学习生成一组通道仿射参数 (γt,βt) 来调制中间特征 ft 。通过将 TAT 残差块插入到现有视频 INR 中,这些对齐的中间特征可以显著增强模型的过拟合能力。
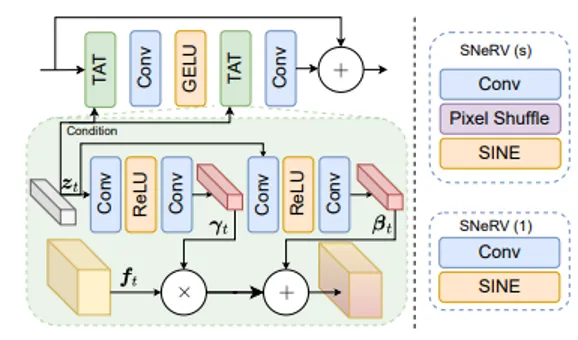
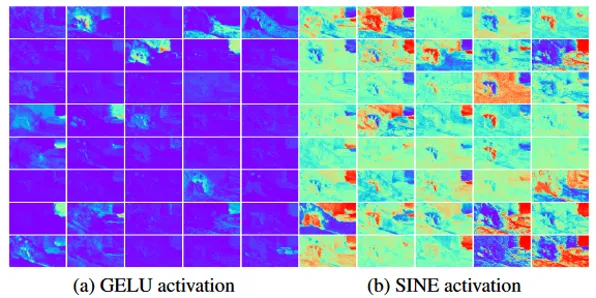
正弦NeRV-like 块: 先前工作通常使用 GELU 作为默认激活函数。 然而,如图3所示,GELU层往往只激活有限数量的特征图,而SINE层激活的特征图则更加多样化,并且不同通道的特征图可以关注到不同区域。 这促使我们引入正弦 NeRV-like (sinusoidal NeRV-like, SNeRV) 块。 如图2(右)所示,我们的SNeRV块有两种类型,其中带有pixelshuffle层的一种用于上采样特征。

一致熵最小化(Consistent Entropy Minimization, CEM): 在过拟合视频后,我们提出了一种一致熵最小化技术来改进 [5, 6] 中的压缩方法。 如表1所示,Gomes等人[5]和 Maiya 等人 [6] 主要关注模型权重的量化, 忽视了内容嵌入压缩在提高基于混合的视频 INR 的 RD 性能方面的重要性。 此外,这些方法在训练和推理阶段使用不同的熵模型。 具体来说,在训练期间采用小型神经网络作为代理熵模型来估计比特率,而在推理阶段,将其替换为 CABAC 或使用固定统计频率表的算术编码器。 该策略旨在最大限度地减少众多小型代理网络的传输开销。 然而,代理模型估计的码率与实际码率之间的差异可能会误导网络优化,导致编码效率次优。 为了克服这些缺点,我们的研究引入了对熵最小化管道的两个关键修改:(i)应用对称/非对称量化方案来建模权重/嵌入(ii)引入一个无需学习参数的高斯熵模型来建模特征的概率分布,确保训练和推理过程中的一致性。

03 实验结果
我们在多个数据集、多个分支任务上测试了本文提出的框架带来的性能提升,通过将本文方法施加于NeRV [1], E-NeRV [2] 和HNeRV [3],验证了本文方法的通用性和有效性。
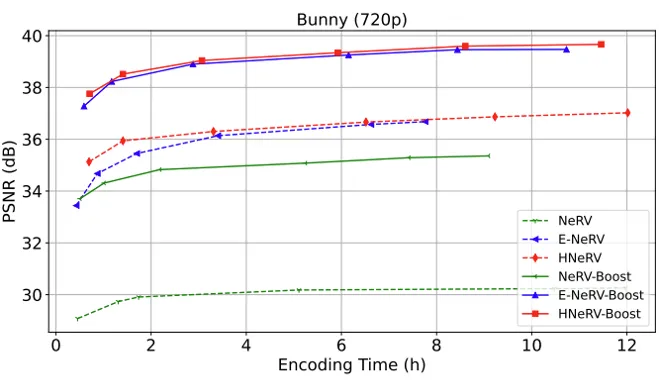
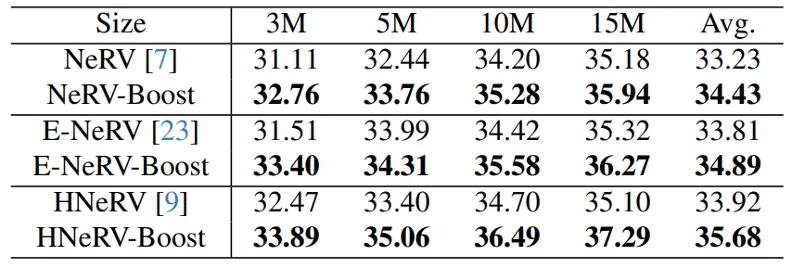
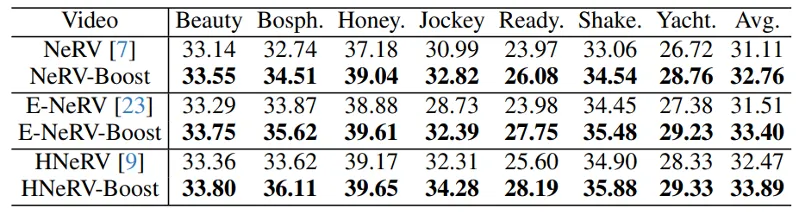
视频回归: 表2显示了各种方法在不同尺度的UVG数据集上的回归性能。很明显,我们的增强方法比相应的基线实现了更高的重建质量。如表 3 所示,UVG 数据集中所有测试视频的改进都是一致的。例如,与 ReadySetGo 视频上的 NeRV、E-NeRV 和 HNeRV 基线相比,我们的增强版本分别表现出约 2.11dB、3.77dB 和 2.59dB 的显着改进。在图 4 中,我们对不同拟合时间的Bunny视频的增强版本和基线之间的回归性能进行了比较。值得注意的是,我们在最短训练时间下的增强版本明显超过了在最大训练时间下的基线,这表明我们的方法在加速收敛速度和提高模型表征能力方面的优越性。
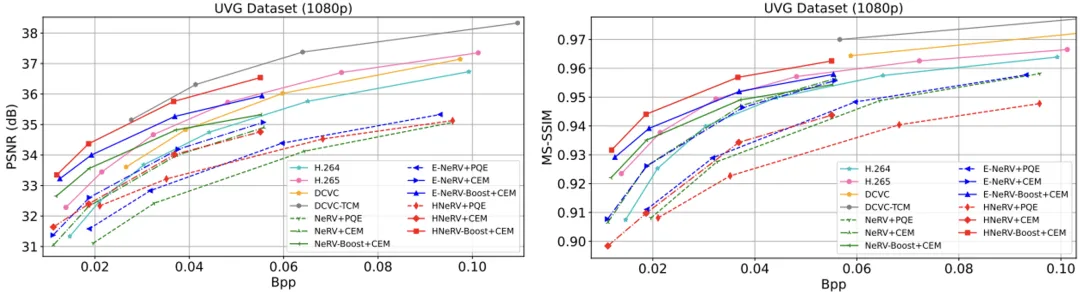
视频压缩: 图 5 展示了这些方法在 UVG 数据集上的 RD 曲线。 我们的增强模型比相应的基线提供了显着的改进,表明我们框架的泛化性。 值得注意的是,原始 HNeRV 在压缩方面表现出较差的鲁棒性,这限制了内容相关嵌入的潜力。 相反,通过我们的修改,增强后的 HNeRV 在所有比特率上在 PSNR 方面始终超过 DCVC、H.265、H.264 和其他 INR 方法,这强调了我们的框架放大 INR 模型优势的能力本身。 此外,使用 CEM 的基线优于使用三步压缩的基线,这凸显了我们的压缩技术在增强 RD 性能方面的有效性。
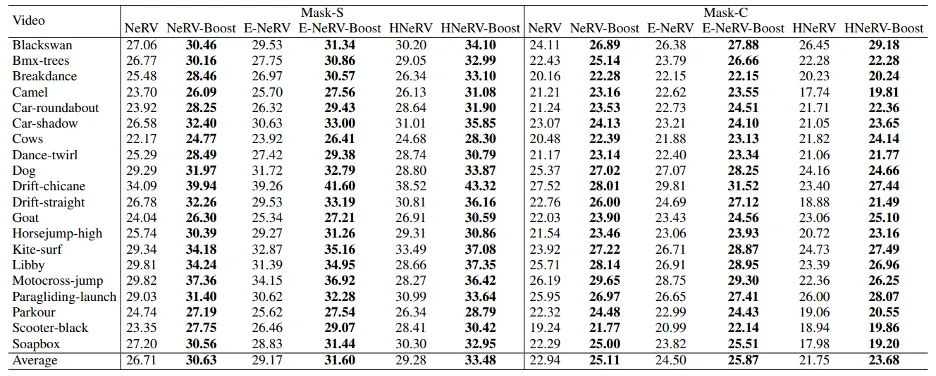
视频填充: 如表4所示,我们的增强版本显着提高了原始基线的修复性能。在分散掩模情况下,我们观察到 NeRV、E-NeRV 和 HNeRV 的平均改进分别为 3.92dB、2.43dB 和 4.2dB。即使在更具挑战性的中央掩模场景中,我们的增强版本仍然实现了 2.17dB、1.37dB 和 1.93dB 的改进。
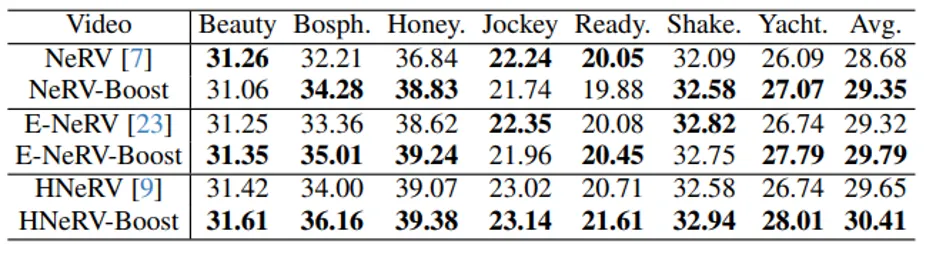
视频插值: 我们评估了 UVG 数据集上增强模型的视频插值性能。在本实验中,我们使用每个视频的奇数帧作为训练集,偶数帧作为测试集。定量结果详见表 5,这些结果表明我们的增强模型在整体插值质量方面优于基线。
04 总结
在本文中,我们开发了一个通用框架来增强隐式视频表示,在回归、压缩、修复和插值等关键任务上实现了实质性改进。 这些进步主要归功于多项新颖进展的集成,包括时间感知仿射变换、正弦 NeRV-like 块设计、改进的重建损失和一致的熵最小化。 通过对多个隐式视频模型的综合评估,我们的增强模型表现出了卓越的性能,在隐式视频表征领域树立了新的基准。
05 参考文献
[1] Hao Chen, Bo He, Hanyu Wang, Yixuan Ren, Ser Nam Lim, and Abhinav Shrivastava, NeRV: Neural representations for videos. Advances in Neural Information Processing Systems, pp. 21557–21568, 2021.
[2] Zizhang Li, Mengmeng Wang, Huaijin Pi, Kechun Xu, Jianbiao Mei, and Yong Liu, E-NeRV: Expedite neural video representation with disentangled spatial-temporal context. In European Conference on Computer Vision, pp. 267–284. Springer, 2022.
[3] Hao Chen, Matthew Gwilliam, Ser-Nam Lim, and Abhinav Shrivastava, Hnerv: A hybrid neural representation for videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10270-10279, 2023.
[4] Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE international conference on computer vision, pp. 1501–1510, 2017.
[5] Carlos Gomes, Roberto Azevedo, and Christopher Schroers. Video compression with entropy-constrained neural representations. In Proceedings of the IEEE/CVF Conferenceon Computer Vision and Pattern Recognition, pp. 18497-18506, 2023.
[6] Shishira R Maiya, Sharath Girish, Max Ehrlich, Hanyu Wang, Kwot Sin Lee, Patrick Poirson, Pengxiang Wu, Chen Wang, and Abhinav Shrivastava. Nirvana: Neural implicit representations of videos with adaptive networks and autoregressive patch-wise modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14378–14387, 2023.
作者:ZHANG, Xinjie
审阅:LIU, Zhening
编辑:LIN, Zehong
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
