
UniEdit是一种无需训练,能同时解决视频运动编辑和外观编辑的统一框架。我们发现,视频模型中的时间和空间自注意力层分别编码帧间和帧内依赖关系。基于这一洞见,为了实现在保留源视频内容的同时进行运动编辑,我们引入了两个额外的去噪分支:辅助运动参考分支和重建分支,分别负责生成文本引导的运动特征和保留源视频特征。然后通过时间和空间自注意力层将获得的特征注入到主编辑分支中。大量实验表明,UniEdit涵盖了视频运动编辑和各种外观编辑场景的能力,并在性能上超越了SOTA。
来源:arxiv
作者:Jianhong Bai等(浙江大学、微软亚洲研究院、北京大学)
论文题目:UniEdit: A Unified Tuning-Free Framework for Video Motion and Appearance Editing
论文链接:https://arxiv.org/abs/2402.13185
项目主页:https://jianhongbai.github.io/UniEdit/
内容整理:陈相宜
引言
近来,尽管文本引导的视频编辑工作已取得了不错的进展,但时间维度的视频动作编辑依然是颇具挑战的。本工作提出了UniEdit,一个同时支持外观和动作编辑的零训练框架。UniEdit借助预训练文生视频模型,并采取先反转后编辑(inversion-then-generation)的框架。
先前的研究为实现动作编辑,需要基于源视频微调预训练的生成器,然后通过文本引导编辑运动。这经常导致运动多样性受限及源视频中不必要的内容变化。
本工作中,为实现动作编辑,我们引入了一个辅助运动参考分支来生成文本引导的运动特征,通过时间自注意力层将这些特征注入到编辑视频中;同时,为使源视频中未经编辑的内容保持不变,我们引入了一个辅助重构分支,将其空间自注意力特征注入到编辑视频中;另外,为维持源视频的空间结构,我们将视频编辑过程中的空间注意力图替换为辅助重构分支中的空间注意力图。
方法
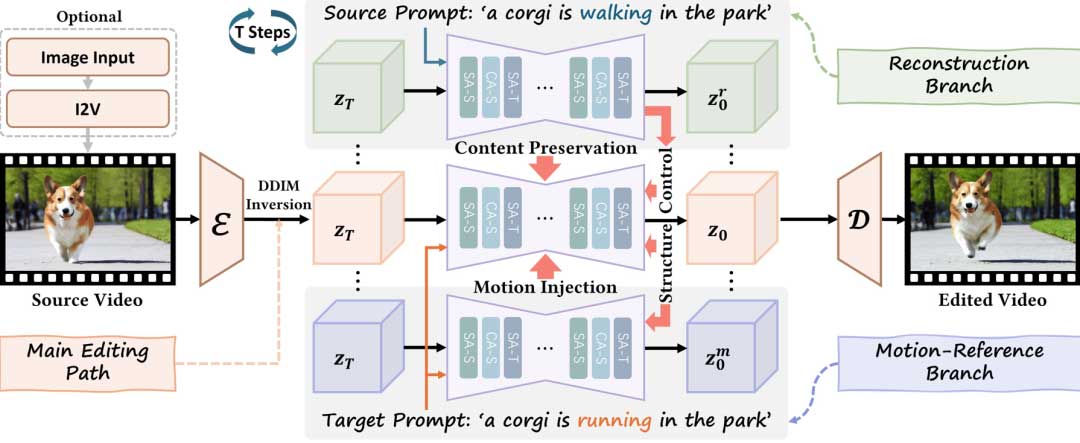
UniEdit采取先反转后编辑(inversion-then-generation)的整体框架:我们将DDIM反演后的潜变量作为初始噪声Zt,然后使用预训练的UNet,以目标提示Pt为条件,从Zt开始执行去噪过程。我们将这一去噪分支称为主要编辑分支。同时,我们还引入了额外的重构分支和动作分支分别负责提供源视频的特征及动作特征。
零训练的视频动作编辑
基于空间自注意力模块的内容保留
视频编辑任务的一个关键挑战是保留源视频中的原始内容(例如纹理和背景)。为此,我们引入了一个辅助重建分支。重建路径从反演的潜变量Zt开始,然后使用预训练的UNet,以源提示Ps为条件进行去噪过程。
先前的研究表明,在重建期间去噪模型中的注意力特征包含源视频的内容。因此,为了保留源视频中的内容,我们将重建路径的注意力特征注入到主编辑路径的空间自注意力层中。

通过对Value特征的替换,主分支中生成的视频能保留源视频中未经编辑的特征。
基于时间自注意力模块的动作注入
借助上述的内容保留策略,我们能获得一个具有源视频相同内容的编辑视频。然而,我们注意到这样的输出视频无法正确地遵循文本提示Pt中描述的目标运动。为了在不牺牲内容一致性的情况下进行运动编辑,我们引入了一个辅助运动参考分支。运动分支也从反演的潜变量zt开始,但由目标提示Pt引导,Pt中包含对目标运动的描述。
在视频生成模型中,是时间层模拟了帧间的依赖关系,也即运动信息。受此启发,我们设计了运动分支上的时间自注意力图注入策略。

零训练的视频外观编辑
上节中,我们介绍了UniEdit实现视频动作编辑的流程。本节中,我们介绍如何基于同一套流程实现视频外观编辑。
外观编辑和运动编辑之间有两个主要区别。首先,外观编辑不需要改变运动。因此,我们从运动编辑流程中移除运动参考分支和运动注入策略。其次,外观编辑的主要挑战是保持和源视频结构一致。为此,我们引入了主编辑分支和重建分支之间的空间布局控制策略。
基于空间自注意力模块的空间布局控制
我们提出从重构分支中提取源视频的布局信息。具体来说,空间自注意力层中的注意力图包含视频的结构信息。因此,我们将主编辑路径中空间自注意力层模块的Query和Key特征分别替换为重建分支中的对应特征。
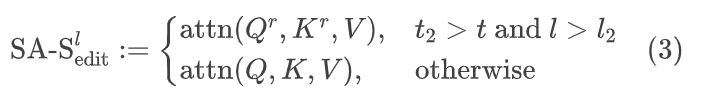
需要注意的是,本节的空间布局控制机制与上文中的内容保留机制是不同的。以风格化任务为例,空间布局控制确保每帧的空间结构与源视频一致,同时使模型能够生成目标纹理和风格。另一方面,内容保留策略则继承了源视频的纹理和风格。因此,我们在外观编辑中使用布局控制而不是内容保留机制。
掩码引导的协调
为提高视频背景部分保持一致,我们进一步利用前景/背景分割掩码M来引导去噪过程。有两种可能的方式获取掩码M:一是通过设定一个阈值,根据交叉注意力模块的注意力图自动生成掩码;二是利用现成的分割模型对源视频和生成视频进行分割。
我们在主编辑路径中利用掩码引导的自注意力来协调编辑路径和运动参考分支,
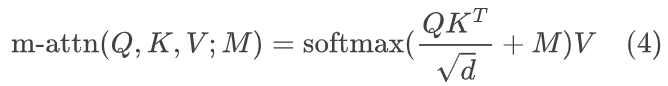
掩码引导的自注意力机制表示为
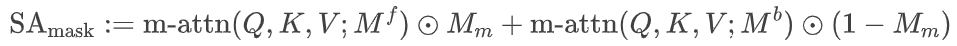
其中Mf,Mb分别表示主编辑分支中的前后景掩码,Mm表示动作分支中的前景掩码。
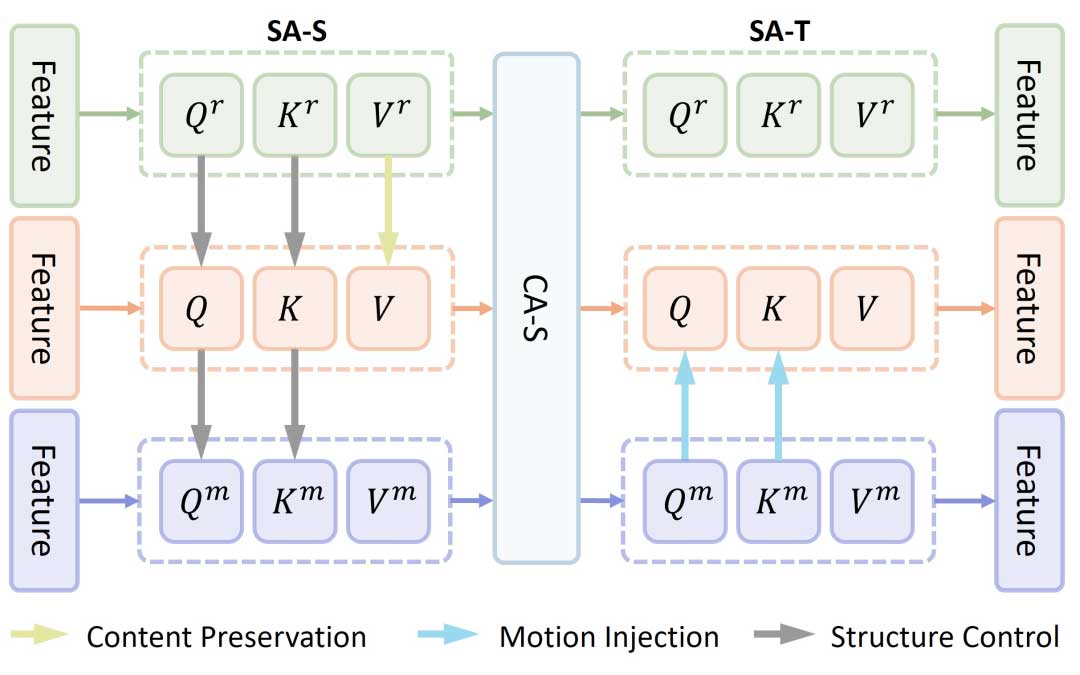
主编辑分支、辅助重建分支和辅助运动参考分支之间的关系。内容保留、运动注入和空间布局控制通过空间自注意力(SA-S)和时间自注意力(SA-T)模块中的Q、K、V特征的融合来实现。
实验
实验设定
UniEdit并不局限于特定的视频模型。我们在文生视频模型LaVie上实践了UniEdit。我们按照LaVie中的预处理步骤将视频处理到分辨率为320×512,然后输入到UniEdit中进行视频编辑。在NVIDIA A100 GPU上,每个视频编辑过程需要1-2分钟。
与SOTA的比较
我们将UniEdit的编辑结果与SOTA运动和外观编辑方法进行比较。对于运动编辑,我们将非刚性图像编辑的SOTA MasaCtrl扩展为文本到视频模型并与其对比。我们还与Tune-A-Video(TAV)进行比较。对于外观编辑,我们将FateZero、TokenFlow和Rerender-A-Video(Rerender)作为基线方法进行对比。
定性结果

上图展示了UniEdit的编辑示例。我们观察到,UniEdit能够 1)实现不同场景的编辑,包括改变运动、替换对象、风格转移、背景修改等;2)与目标提示对齐;3)展现出良好的时间一致性。
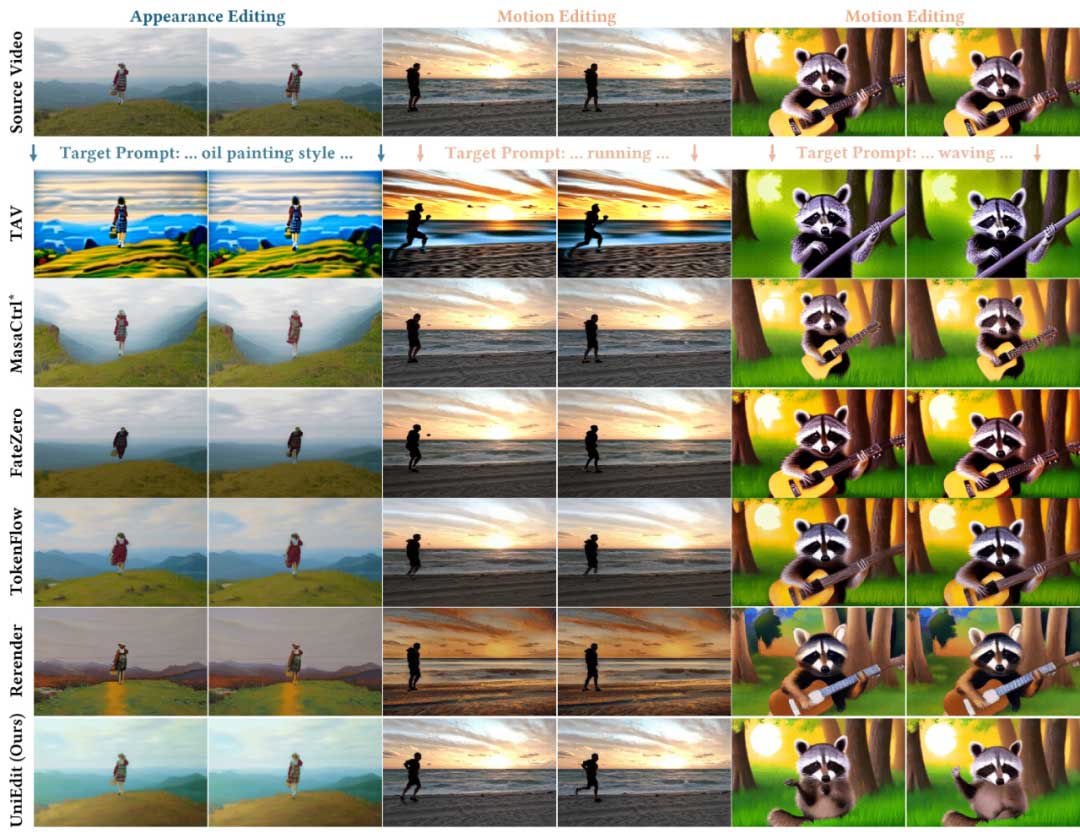
上图展示了与SOTA方法的比较结果。对于外观编辑(如将源视频转换为油画风格)UniEdit在内容保留方面表现优于基线。例如,草地仍然保持其原始外观,没有额外的石头或小路出现。对于运动编辑,相较UniEdit,大多数基线方法无法输出与目标提示对齐的视频,或者无法保持源内容。
定量结果
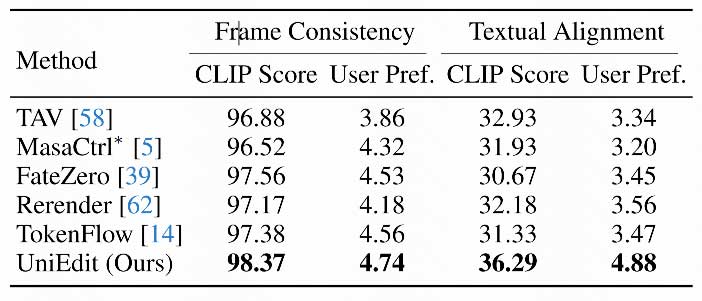
我们从两个方面定量验证了UniEdit的有效性:时间一致性,及与提示文本的对齐程度。我们使用CLIP计算帧一致性和文本对齐的分数。我们还进行了用户研究。表格显示UniEdit显著优于基线方法。
消融性实验

空间自注意力模块与时间自注意力模块
上图中,我们可视化了空间自注意力模块中的特征(第二行)和时间自注意力模块中的特征(第三行),并将它们与相邻帧之间的运动光流(第四行)进行比较。可以看出,时间注意力图与光流具有明显更大的重叠。这证明了我们在时间自注意力层中进行运动注入这一策略的合理性。

辅助重建分支和辅助运动参考分支
为了更好地理解两个辅助分支的作用,我们可视化了分别单独利用每个分支进行编辑的结果。当仅从重建分支进行内容保留时,虽然身份和背景得到了很好的保留,但合成的帧与目标提示有偏差。另一方面,仅从运动分支实施运动注入则会导致背景发生显著变化。相反,UniEdit在内容保留和遵循文本两方面均取得了令人满意的性能。
空间布局控制策略
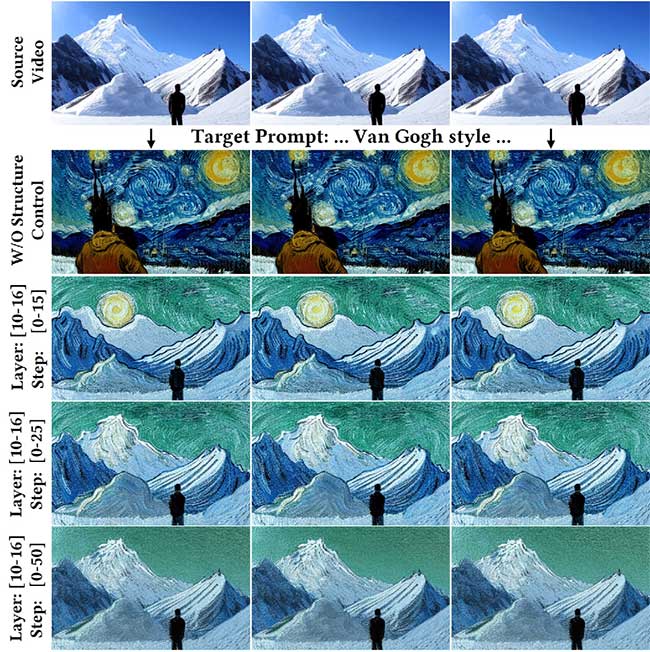
上图第二行展示对空间布局控制策略的消融结果。结果表明,如果没有这一策略,源视频的空间结构信息将会丢失。
去噪步骤和注意力层数
UniEdit通过在不同注意力层和不同去噪步骤中向主编辑分支注入特征来支持灵活可控的视频编辑。上图后三行展示对去噪步骤和注意力层数的消融结果。结果表明,与在更多步骤(t2=50)进行注入相比,在较少步骤(t2=15)进行注入会产生更具风格化的输出。
结论
本文提出了一个新颖的无需训练的框架UniEdit,用于视频运动和外观编辑。通过利用辅助运动参考分支和辅助重建分支,并将特征注入到主编辑路径中,它能够执行运动编辑和各种外观编辑。然而,UniEdit仍然存在一些限制。首先,虽然可以通过两次调用UniEdit来实现对运动和外观的编辑,但如何同时进行这两种类型的编辑尚待探索。其次,由于有多个超参数,值得研究一套最优超参数的自动选定方案。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
