
最近,直接对连续帧中潜在特征的条件分布进行建模以消除时间冗余的概率预测编码已经产生了有希望的结果。使用单尺度 VAE 的现有方法必须设计复杂的网络来进行潜在空间中的条件概率估计,而忽略了视频帧的多尺度特征。相反,作者提出了一种新型的分层概率预测编码框架,其中分层 VAE 将多尺度潜在特征描述为一系列灵活的先验和后验,以预测未来帧的概率。所提出的方法在常见测试视频上优于代表性学习视频压缩模型,并以更少的内存占用和更快的编码/解码展示了计算友好性。
题目:Deep Hierarchical Video Compression
作者:Ming Lu, Zhihao Duan, Fengqing Zhu, Zhan Ma
来源:AAAI 2024
文章地址:http://arxiv.org/abs/2312.07126
内容整理:令潇越
引言
目前,基于学习的视频压缩方法仍然受制于传统的混合编码框架。大多数现有方法都采用了两阶段编码流程,首先编码运动流,然后编码当前帧与运动扭曲后的帧之间的残差。这种框架设计繁琐,并且不准确的运动引起的扭曲误差不可避免地会跨时间帧传播,随着时间的推移逐渐降低重建帧的质量。
针对这一问题,Mentzer 等人提出了一种名为 Video Compression Transformer(VCT)的概率预测视频编码框架。尽管 VCT 优于许多以前的视频编码方法,但其对原始帧 1/16 分辨率的单尺度潜在特征进行条件预测从根本上限制了其表征能力,忽略了视频帧的多尺度特征。
因此,作者提出了一种分层概率预测编码,称为 DHVC,其中通过精心设计的分层 VAE 来对未来帧的多尺度潜在特征的条件概率进行有效建模,当前帧中某个尺度的潜在分布是通过同一帧中先前尺度的先验特征以及先前帧的相应尺度来预测的。通过多阶段条件概率预测,提出的方法在通用视频序列上表现优于混合运动和残差编码以及先前的基于潜在概率预测编码的最先进方法。对于适应各种时序模式的广泛研究还揭示了分层预测机制的泛化能力,此外,提出的方法还支持渐进式解码,是第一个支持这一功能的学习型渐进式视频编码方法,它在一定程度上可以处理由于网络连接不佳而引起的数据包丢失。
本文的主要贡献如下:
- 提出了一种用于视频编码的分层概率预测模型,采用了一系列多尺度潜在变量表示视频帧从粗到细的特性。
- 提出了空间-时间预测和环内解码融合的方法来增强率失真性能,将这些模块集成到分层架构中,比之前最好的基于概率预测编码的方法实现了更好的性能、更低的内存消耗和更快的编码/解码速度。
- 实验表明提出的方法对各种时序模式有更好的泛化能力,是第一个支持渐进式解码功能的模型。
模型
整体架构
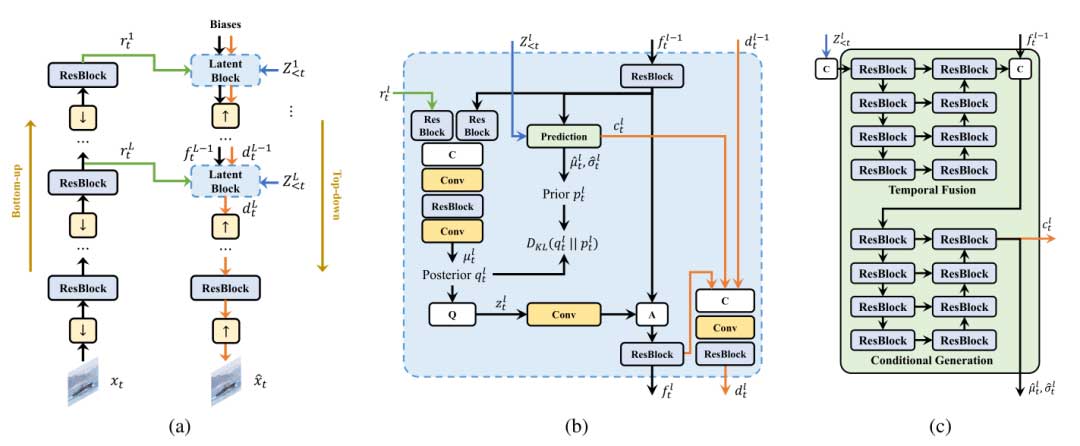

预测编码模块
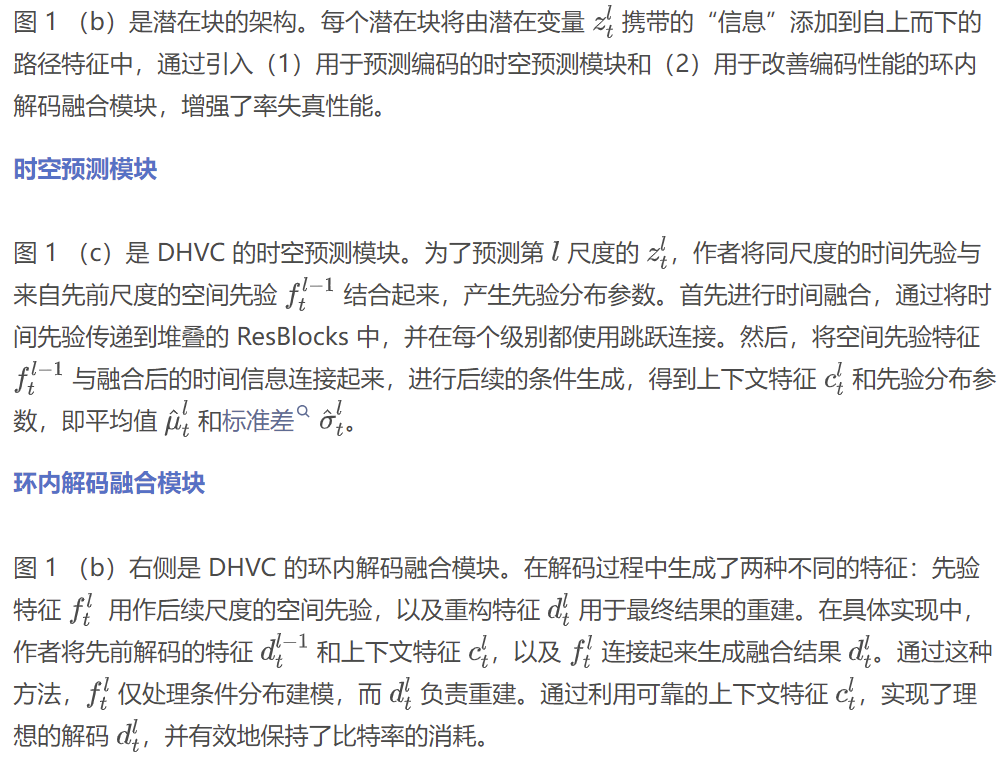
概率模型和损失函数
为了支持使用可行的熵编码算法进行实际的有损压缩,作者采用了量化感知训练,使用均匀后验分布。具体来说,在训练时采用了混合量化策略来模拟量化误差,加性均匀噪声用于速率估计,而直通舍入操作用于重建;在测试时使用均匀量化。对于先验,使用高斯分布与均匀分布的卷积,以便灵活地匹配后验。
后验

训练目标
损失函数 L 如下式,第一项是所有潜在变量的比特率,第二项是重建失真,通常选择为视频的均方误差(MSE)或 MS-SSIM 损失。乘数 λ 用于权衡比特率和失真。
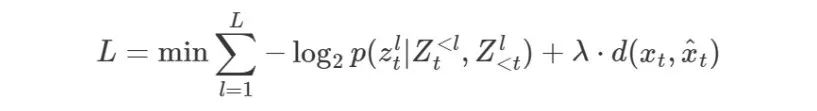
实验
实验设计
数据集
- 训练:Vimeo-90K
- 评估:UVG、MCL-JCV 和 HEVC Class B、C、D、E
基准模型
x265,HM-16.26,DVC-Pro,MLVC,RLVC,DCVC,VCT
实验结果
率失真性能
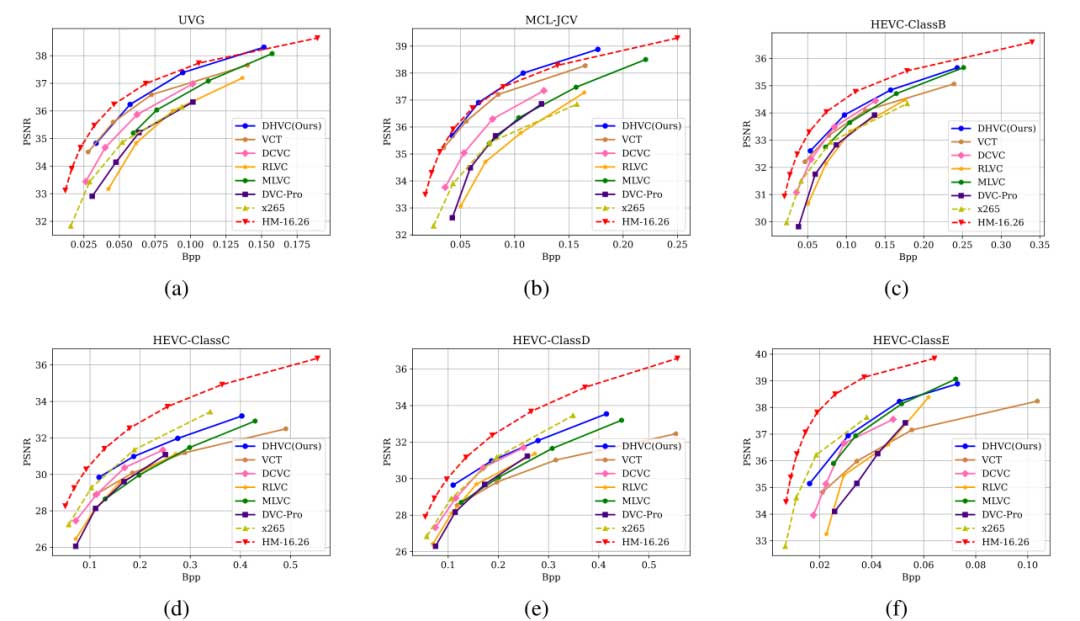
DHVC 方法在各种数据集上均优于其他学习方法,表现出了良好的泛化能力。
复杂度比较
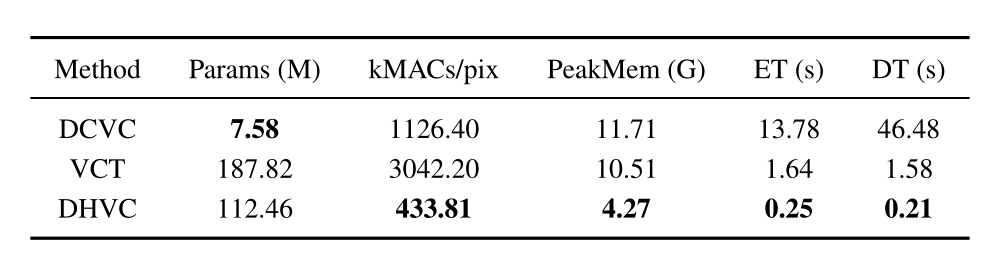
DHVC 在编码和解码时间、每像素的 kMACs 和峰值内存消耗等方面都表现出明显的优势。
消融实验
模块贡献
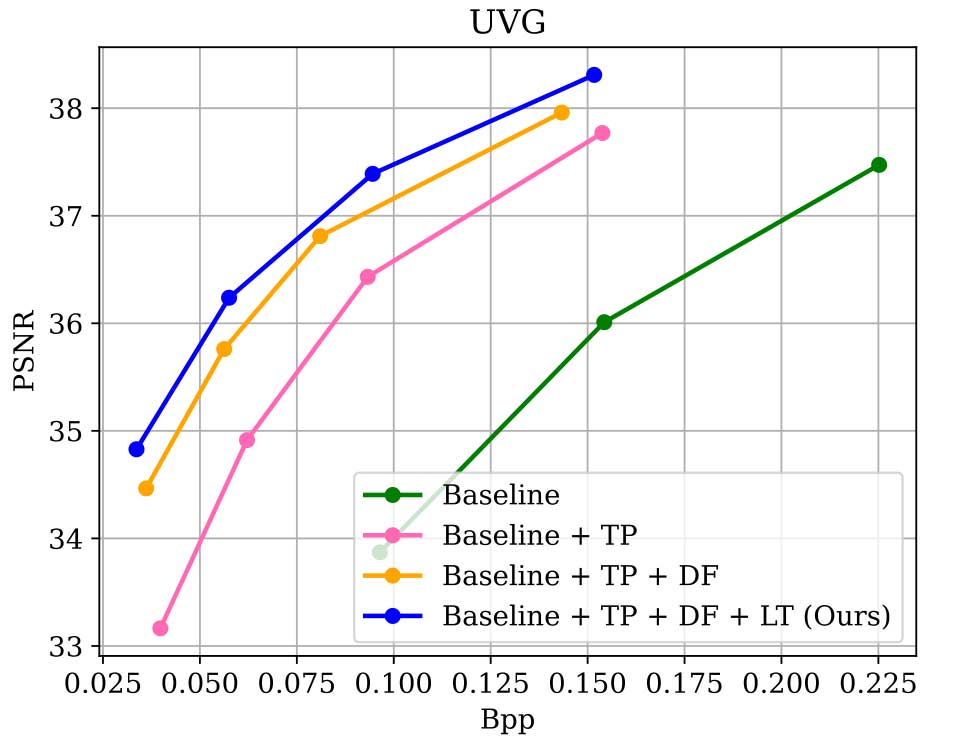
Baseline 表示禁用了潜在块中的时间预测和环内解码融合,只使用来自前一层级的空间先验进行概率建模。Baseline + TP 表示将时间概率预测集成到模型中以减少时间冗余,显然支持时间信息的性能明显提高。在环内解码融合模块的帮助下, Baseline + TP + DF 的模型在 PSNR 上平均提高了 1 dB。此外,使用五帧进行长期微调,即 Baseline + TP + DF + LT ,使 R-D 曲线得到进一步改善,构成了作者方法的完整性能,这表明通过与多帧联合训练,可以有效地平衡帧之间的速率失真关系。
对于不同时间模式的适应能力
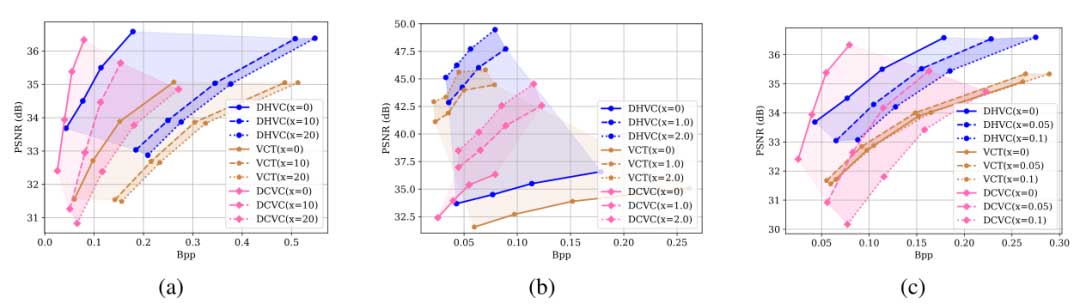
无论是哪种时间模式,以及场景变化有多快,DHVC 方法都具有一致的适用性,并且在所有合成数据集上均优于 VCT 方法。
渐进解码能力
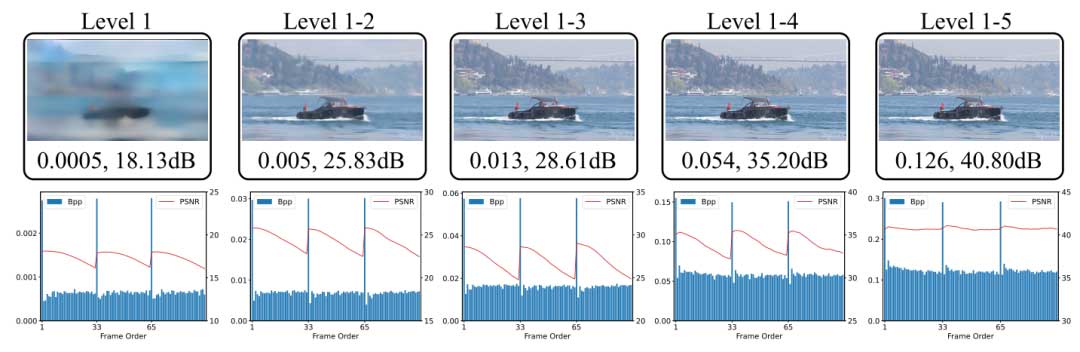
作者展示了 DHVC 方法的渐进解码能力,这在现有方法中很少见,渐进解码提供了相对粗糙的重建,从而在视频流应用中提供了快速且占用较少比特率的预览功能。
结论
作者提出了一种用于基于学习的视频压缩的新型分层概率预测编码框架,称为 DHVC。DHVC 为各种视频样本中流行且具有代表性的学习视频编解码器提供卓越的压缩效率,实现了更好的性能、更低的内存消耗和更快的编码/解码速度。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
