
本文提出了一种基于去噪扩散的、用于高质量人体动作条件合成的框架 MoFusion,该框架可以根据一系列条件上下文(例如文本、音乐)合成时间上可信、语义上准确的长动作序列。此外,本文提出加权策略将运动学损失引入动作扩散框架,提高了动作的可信度。在 AIST++ 和 HumanML3D 数据集的定量评估以及用户研究展示了 MoFusion 相对于 SOTA 基准方法的有效性。
来源:CVPR 2023
论文题目:MoFusion: A Framework for Denoising-Diffusion-based Motion Synthesis
论文链接:https://arxiv.org/abs/2212.04495
论文作者:Rishabh Dabral 等人
内容整理: 林宗灏
引言
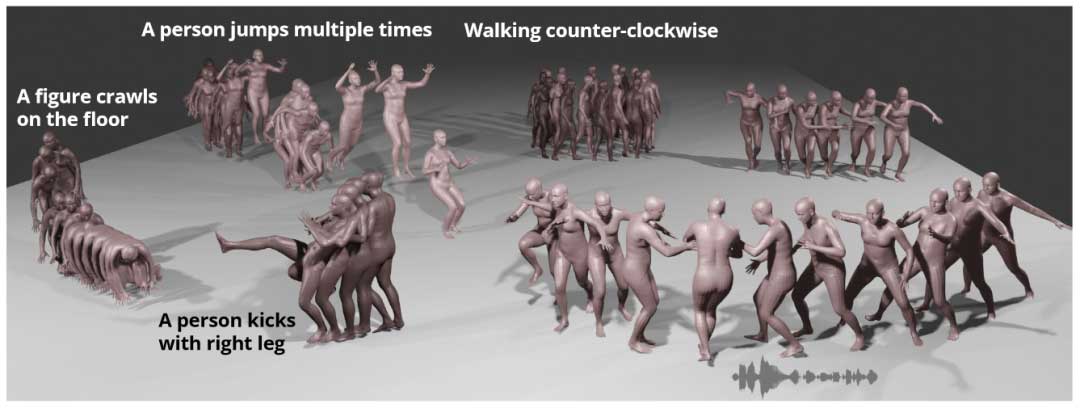
传统人体运动合成方法要么是确定性的,要么是在动作的多样性和质量上进行权衡。针对这些局限性,我们提出了 MoFusion,即一种基于去噪扩散的、用于高质量人体动作条件合成的新框架。MoFusion 可以根据一系列条件上下文(例如文本、音乐)合成时间上可信、语义上准确的长动作序列。我们还介绍了如何通过加权策略,在动作扩散框架中引入运动学损失,以提高动作的可信度。我们分析了动作合成的两个相关子任务:音乐条件的编舞生成和文本条件的动作合成,通过对 AIST++ 和 HumanML3D 数据集的定量评估以及用户研究,我们展示了 MoFusion 相对于 SOTA 基准方法的有效性。本文的主要贡献总结如下:
- 第一种利用去噪扩散模型进行条件化三维人体动作合成的方法。得益于所提出的时变权重,我们引入了运动学损失,使得运动合成结果在时间上可信、在语义上与条件信号一致。
- 我们的框架反映了对多种信号(即音乐和文本)的条件化。对于从音乐到编舞的生成,我们的结果可以很好地推广至新的音乐,并不会出现性能退化或动作重复的问题。
方法
动作合成的扩散
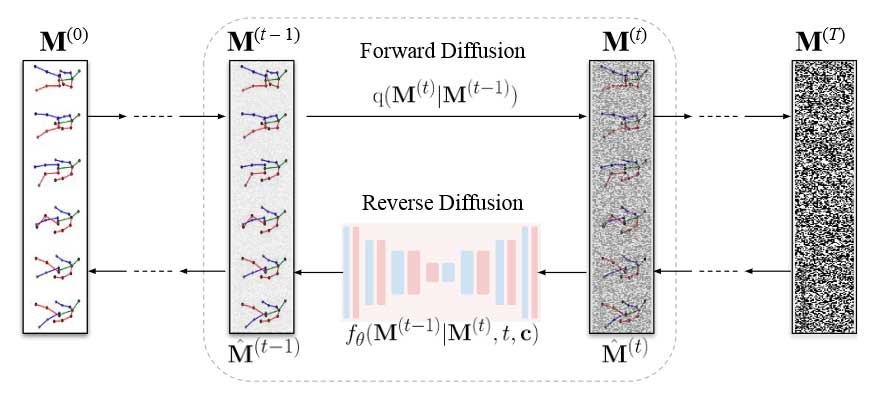
动作生成任务表示为一个反向扩散的过程,需要从噪声分布中采样一个随机噪声向量 z 以生成一个有意义的动作序列(如图 2 所示)。在训练过程中,前向扩散过程以马尔可夫的方式在 T 个时间步内连续向动作序列中添加高斯噪声,其结果是将训练集中有意义的动作序列 M(0) 转换为噪声分布 M(T):
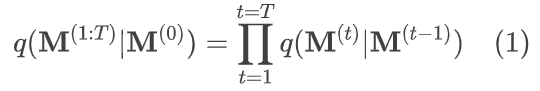

训练目标
训练 MoFusion 的总体损失是两大类损失的加权和:
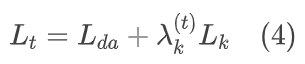

MoFusion 架构
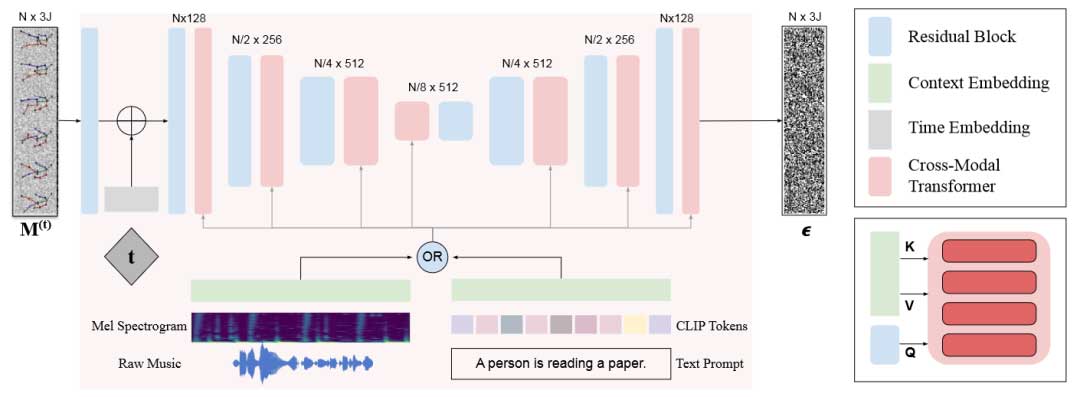
受 1D 卷积网络在动作合成与姿态估计中成功应用的启发,我们使用 1D U-Net 来近似 fθ(·,·)。如图 3 所示,三个下采样块将特征长度从 N 减少至[N/8] ,然后使用上采样块进行上采样。每一个 1D 残差块之后都有一个跨模态 Transformer 块将条件上下文 c 纳入网络。时间嵌入以正弦时间嵌入通过两层 MLP 生成。为了结合上下文,我们使用中间残差运动特征来得到查询向量,使用条件信号来计算键值向量。
音乐-舞蹈合成
为了将网络条件于音乐信号,我们选择使用 Mel 频谱表示,让上下文嵌入层来学习学习在 U-Net 特征空间上的合适投影。理论上,这也允许我们的方法在其他音频(如语音)上进行训练。为了提取 Mel 频谱,我们将音频信号重采样至 16kHz 并将其转换为具有80个 Mel 频段的对数 Mel 频谱。我们使用线性层将输入 Mel 频谱投影至上下文嵌入 c。
文本-动作合成
为了从文本描述中合成动作,我们使用预训练的 CLIP 嵌入。我们首先检索输入中每个单词的 token 嵌入,然后对这些 token 嵌入进行位置编码并送入 CLIP Transformer,最后使用 MLP 投影至上下文嵌入c 。
实验
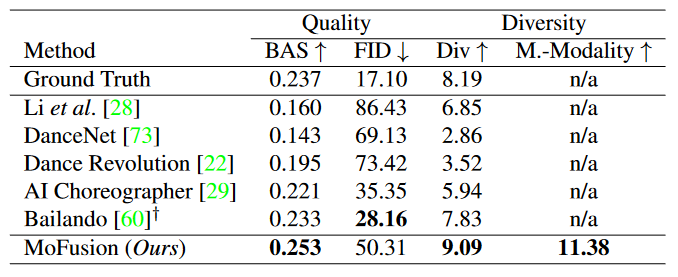
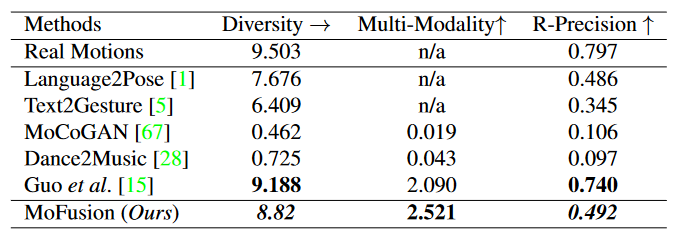
定量结果
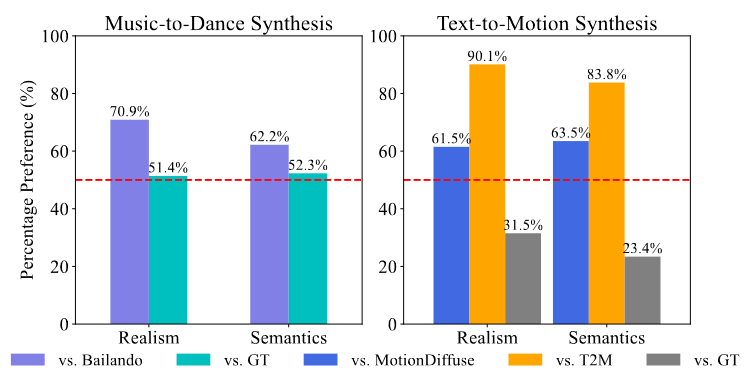
定性结果

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
