
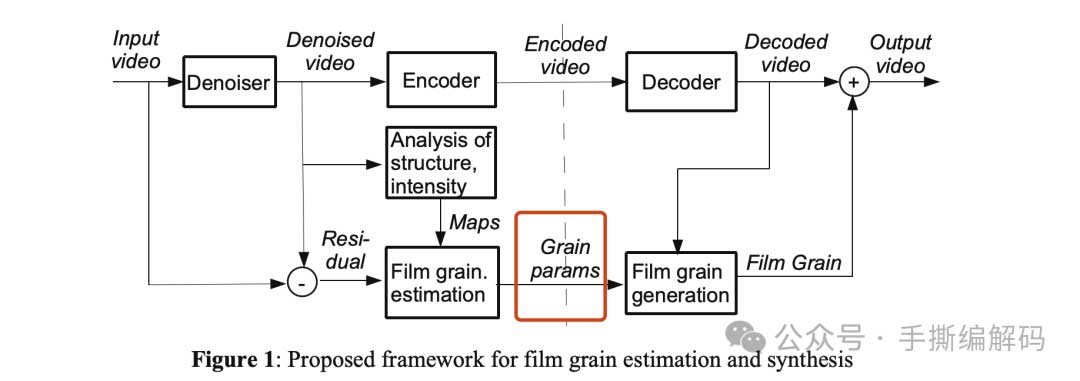
在SVT-AV1开源AV1编码器中,Film Grain技术算法处理框架如下图所示:
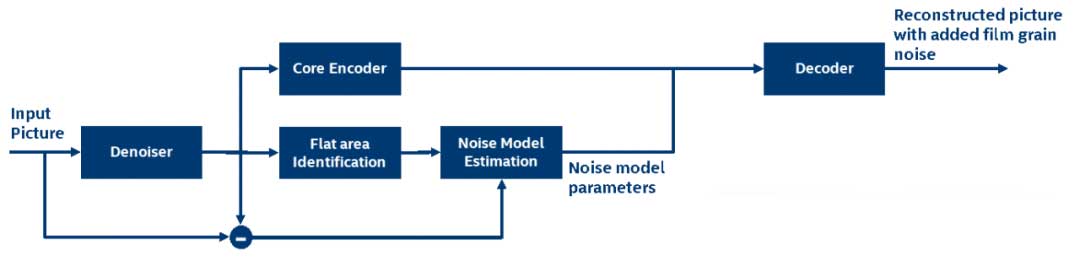
首先对输入视频帧进行降噪处理,降噪以后送去做压缩编码处理。
其次将输入视频帧和降噪后帧的差值用于预估Film Grain参数。
其一噪声模型参数的估计仅仅是在输入视频帧的平坦区域中进行,所以要对去噪后视频帧中的平坦块加以识别,以确保边缘和纹理不会影响到Film Grain的参数估计。
其二如之前介绍,所谓Film Grain实则就是一类“噪声”,这里的噪声模型参数也就是指的Film Grain模型参数。SVT-AV1中对输入视频帧降噪时使用的是二维维纳滤波器(又被称为最小二乘滤波器)。
如果要问编码器端的预估Film Grain参数,到底是在预估哪些东西?
就得看这个噪声模型它具体是什么样的。在解码器端是由一个包含单位方差高斯噪声的自回归模型对Film Grain进行建模合成,以得到对应Film Grain值:

实际这个Film Grain模型是下面这样:
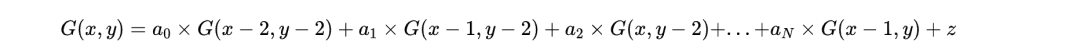
其中G(x,y)代表当前在(x,y)位置的Film Grain值,而G(x-2,y-2),G(x-1,y-2)等则是相邻位置的Film Grain值,z是单位方差高斯噪声,它可以通过预定义查表得到。而a0,a1,a2这些是自回归模型的coefficients。有了相邻位置的Film Grain和这些系数,就可以用上面的递推公式推导出当前位置的Film Grain。
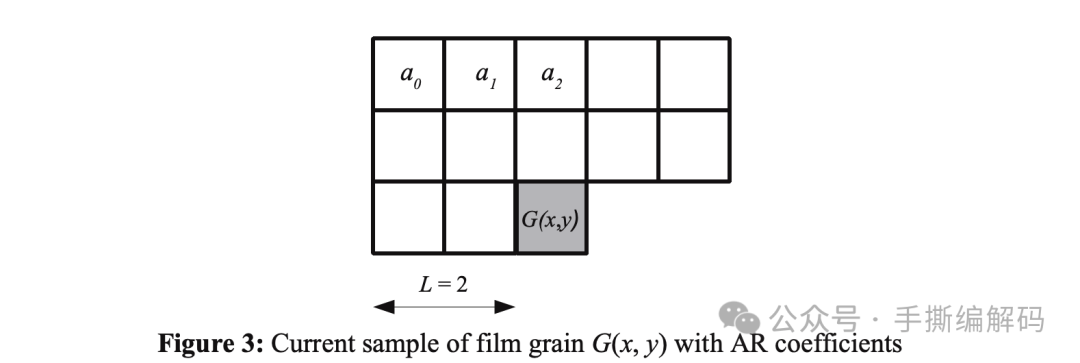
对亮度分量,AR系数的个数等于2L(L+1),对色度分量是2L(L+1)+1,这里L的取值范围是0,1,2,3,即亮度分量最多24个系数,每个色度分量最多有25个系数。L值具体是多大,要看编码器侧是如何决策的。此外,AR系数的数值是编码器侧求解尤尔—沃克方程得到的。

所以,AV1编码器侧要预估的Film Grain模型参数里必须包括AR-coefficients,即a0,a1…aN以及L值。
那编码器侧是不是只要预估这些参数就够了呢?实际上,在解码端得到对应位置的Film Grain值后,还需把它加到对应像素位置的重建像素值上,而这个相加过程在SVT-AV1中使用的模型是:
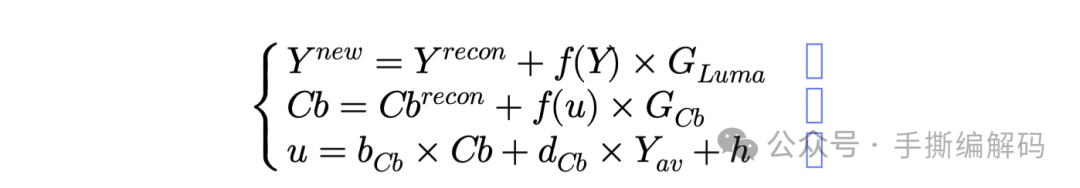
其中Yrecon指的是视频流解码后还未加Film Grain的重建像素值,这里的f(Y)是一个分段线性函数,用于对亮度分量的Film Grain值缩放,这里的自变量Y是亮度重建像素值,颜色分量Cb和Cr也有类似处理过程,不过色度分量用的f(u),这里的u对应的是缩放函数索引,且和亮度分量有关,即亮度分量会影响色度分量的film grain值。
分段线性函数f()如下图所示,它也需要写到码流里。不过可以提前计算函数点存到look-up table (LUT)里 ,由编码器端告诉解码器所对应LUT的索引信息。
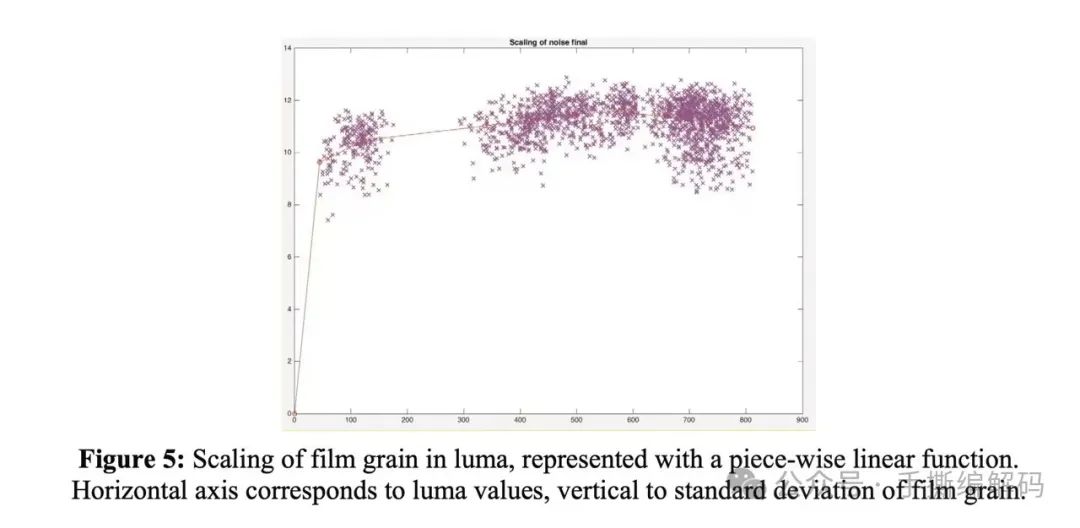
把一个分段线性函数写到码流里,需要写入分段函数上的一些点以及这些点的坐标。AV1标准里亮度分量的分段线性函数对应这些语法元素。
所以对AV1编码器来说,需要将下面这些参数通过码流传送到解码端。
即决定了AR系数个数的L和各个AR系数值,lut->points以及色度分量对应分段线性函数LUT的索引等。这样在解码器侧能根据码流里面的信息得到Film Grain数值。
最后,在SVT-AV1的代码中对Film Grain的处理主要实在picture_analysis_kernel中。
识别平坦区域的函数是:
svt_aom_flat_block_finder_run
二维维纳滤波处理函数是:
svt_aom_wiener_denoise_2d
得到平坦区域的模型参数函数是:
svt_aom_noise_model_update
所以,SVT-AV1作为AV1视频编码标准的一种软件实现方式,它的Film Grain参数预估模型还是自回归模型。编码器侧求解尤尔—沃克方程得到模型系数,并将其写到码流中。解码器侧在Grain Synthesis时不是直接将Film Grain加到重建像素,而是有一个分段线性缩放函数作为Film Grain的强度系数。
参考资料
- https://gitlab.com/AOMediaCodec/SVT-AV1/-/blob/master/Docs/Appendix-Film-Grain-Synthesis.md
- https://norkin.org/pdf/DCC_2018_AV1_film_grain.pdf
作者:codec2021
来源:手撕编解码
原文:https://mp.weixin.qq.com/s/lXdDM0-iHU05HmFhY-45nQ
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
