
基于 Electron 的淘宝直播 PC 推流端已经上线一年多,期间迭代了很多功能,应用也越来越庞大。自上线以来也收到一些用户反馈应用启动慢、打开推流页面慢、运行过程页面交互操作卡、推流画面卡、CPU 占用过高等性能问题。针对这些问题,我们要怎么优化呢?
01 背景
在开始讨论优化之前,我们先来了解下 Electron 是一个使用 JavaScript、HTML 和 CSS 构建 Windows、MacOS、Linux 跨平台的桌面应用程序的框架,嵌入了 Chromium、Node.js 和 Native API:
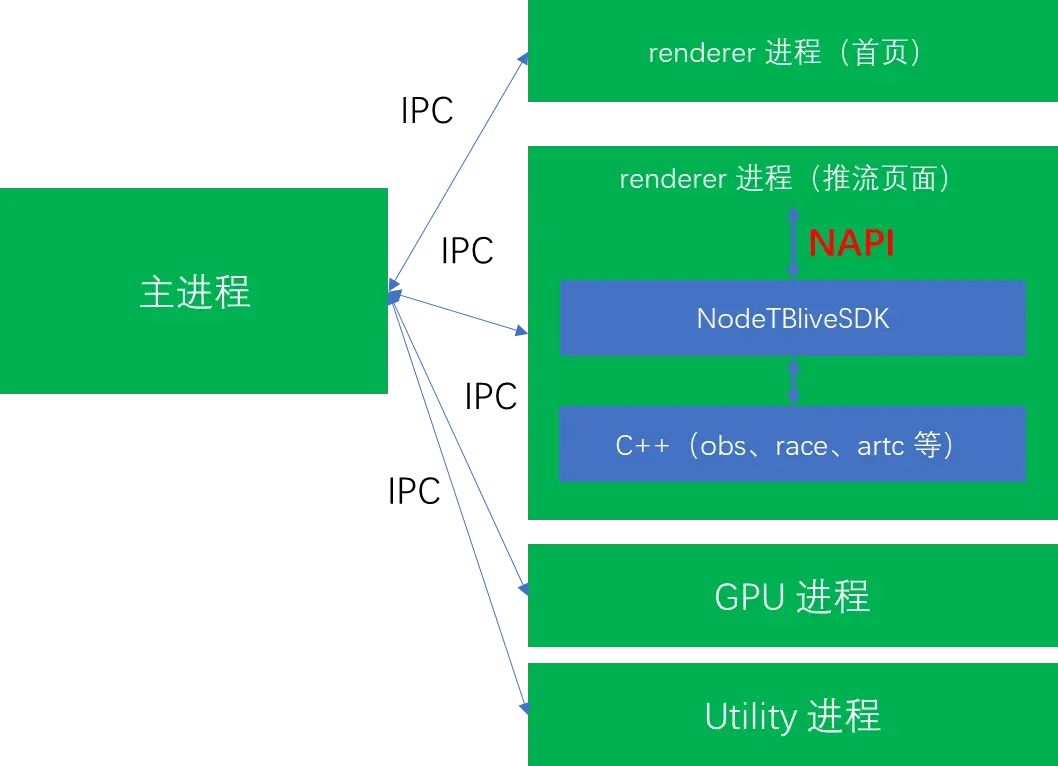
由于 Electron 集成了 Chromium,因此天然支持多进程架构。当淘宝直播 PC 推流端运行起来后,通过查看任务管理器就可以知道除主进程、Utility、GPU 进程外,每新建一个页面窗口就会多一个 renderer 进程,如下图所示:

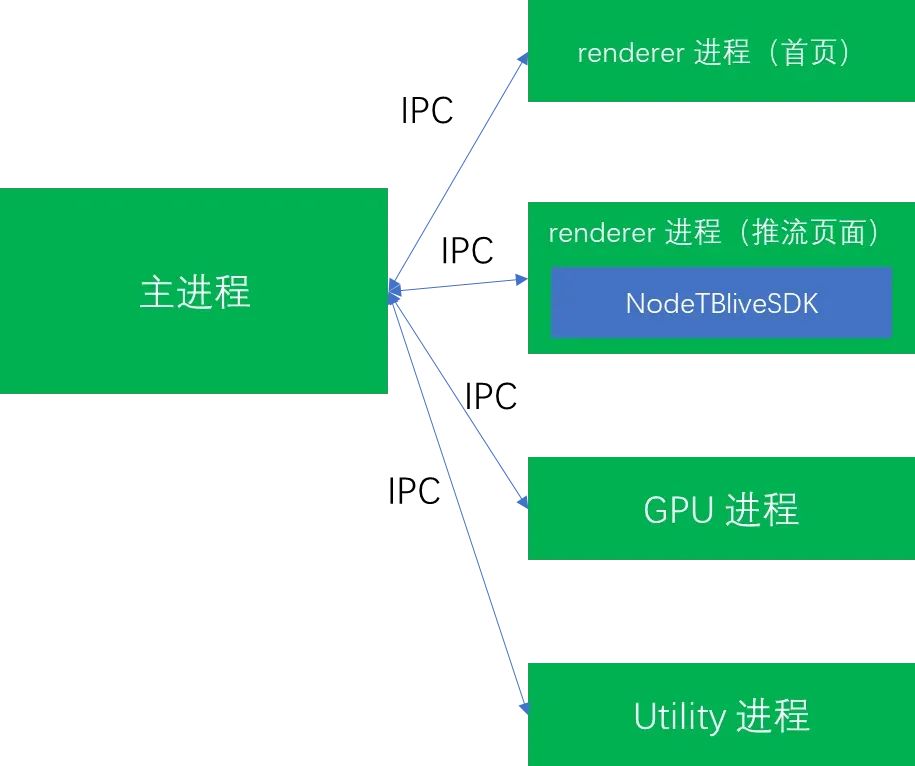
而我们实测也发现也只有推流页面所在 renderer 进程最耗费性能,其中推流 C++ SDK 也运行在该 renderer 进程里。因此,我们接下来主要讨论的是推流页面 renderer 进程是如何优化性能的。
02 如何优化淘宝直播 PC 推流端性能
启动耗时优化
- 应用启动耗时优化
当我们双击打开淘宝直播 PC 推流端应用时,需要初始化一系列的逻辑(如设置缓存、登录所需环境、创建目录、检测内网环境创建系统设置菜单、启动本地服务、初始化 IPC、创建首页、预热推流页面等),整体可交互耗时需要 10s 左右,体验不是很好,用户满意度方面很差。因此,我们进行了一轮优化:
- 启动流程优化检测内网环境创建系统设置菜单优化:请求接口获取是否内网环境比较耗时,同步改为异步electron log 日志输出优化:涉及 IO 操作,多条合并为一条electron store 删除及设置优化:涉及 IO 操作,多条合并为一条删除本地过期目录及杀掉残留独立进程优化:启动执行改为退出时执行创建首页窗口流程优化:首页显示后再执行预热推流页面逻辑
- 包体积压缩优化使用 webpack 配合插件 loader 将 js、css 等资源进行压缩,并通过抽离公共模块,整个 asar 大小从 18M 压缩至 2.5M 左右。这样可以提升 js 加载速度。
- V8 code cacheV8 代码提前编译并进行缓存,等加载执行时速度就快很多了。不过由于 Node.js 启动流程已经针对内置模块的 V8 代码进行编译并缓存了,因此项目中设置也没收益。
经过以上优化后,应用启动耗时从 10s 降低到 2.5s。
- 推流页面启动耗时优化
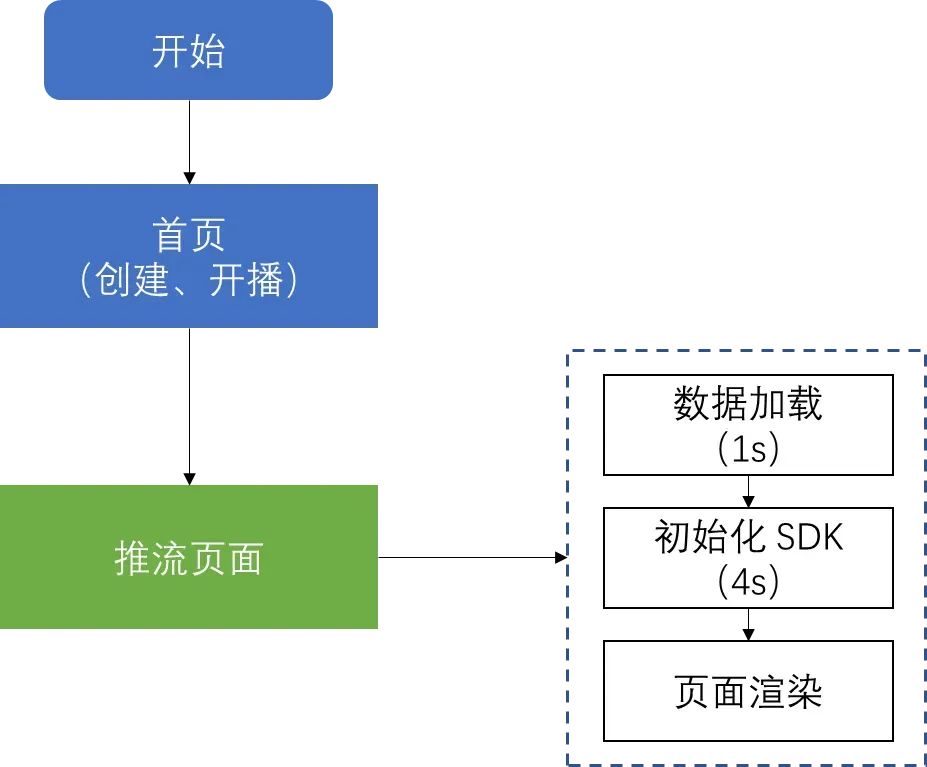
淘宝直播 PC 推流端刚上线时,从首页进入推流页面需要经过数据加载(如通过请求获取直播间配置等数据)、初始化 SDK(C++ 推流 SDK)、页面渲染等流程,整体可交互耗时需要 5s 以上,核心页面 loading 时间比较长:
于是我们进行了一轮优化,通过数据预加载(首页提前加载推流页面数据)、减少 SDK 的初始化耗时(把非关键路径代码改为异步执行),从首页进入推流页面从 5s 以上降至 2s 左右:
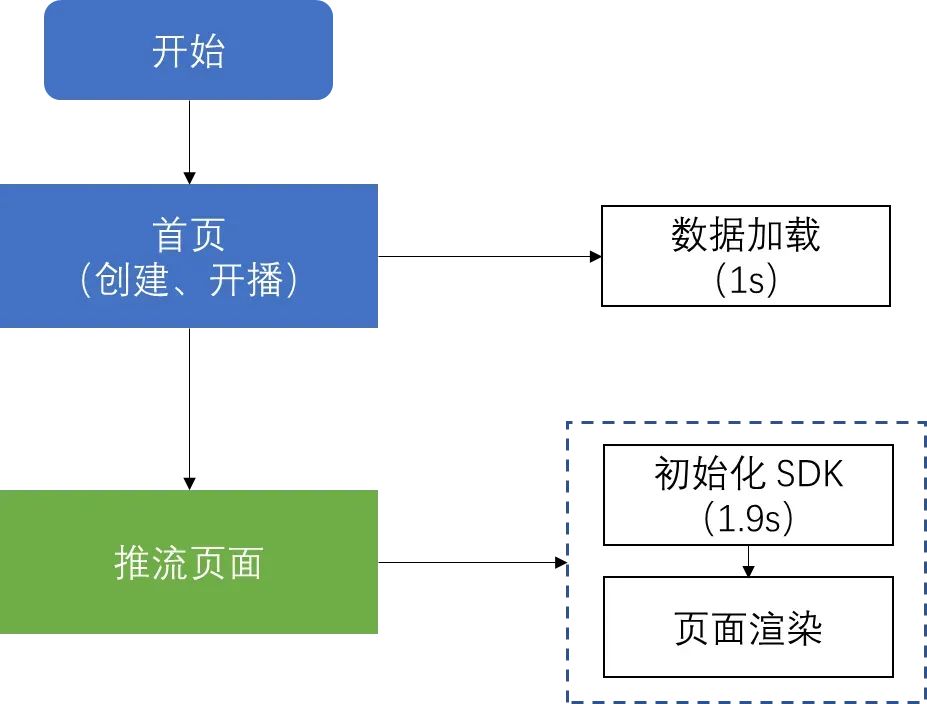
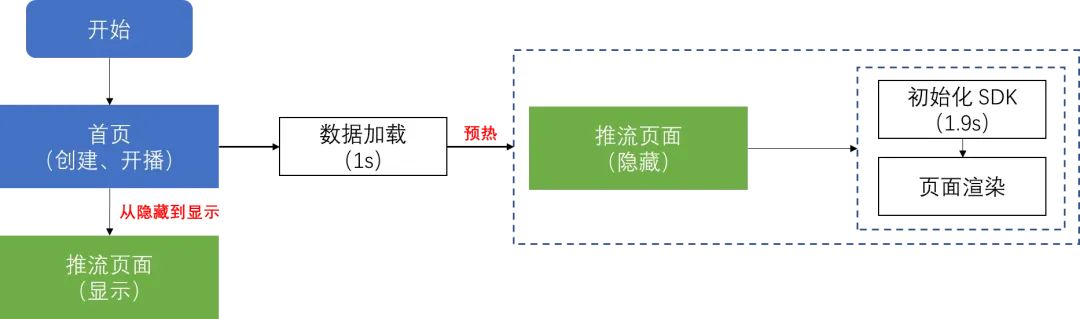
但经过优化后还是没有达到秒开效果,主要原因是初始化 SDK 比较耗时,那有人会问为啥 SDK 不能在首页提前初始化呢?这是因为首页和推流页面都运行在各自的 render 进程里,如果要在首页提前初始化 SDK 的话,就得把 SDK 对象传给推流页面进程,而进程间通信传不了对象,因此该方案行不通。
那还有没其他方案呢?其实我们可以参考预加载的能力,将推流页面进行预热,这样就可以做到提前初始化 SDK 了。通过预热方案后,从首页进入推流页面只需要将隐藏的推流窗口进行显示就行,整体耗时在 50 ms,实现秒开效果。
运行时性能优化
前面优化完核心页面启动耗时后,接下来我们重点介绍如何优化运行时性能。
在做运行时性能优化之前,我们先想一想一个 Electron 应用到底哪里会有性能问题?就拿淘宝直播 PC 推流端为例,我们需要对整个应用进行性能摸底测试,才能知道哪些模块会有性能问题。因此,我们开发了一个性能测试工具,可以分别对前端和 SDK 模块进行单测:
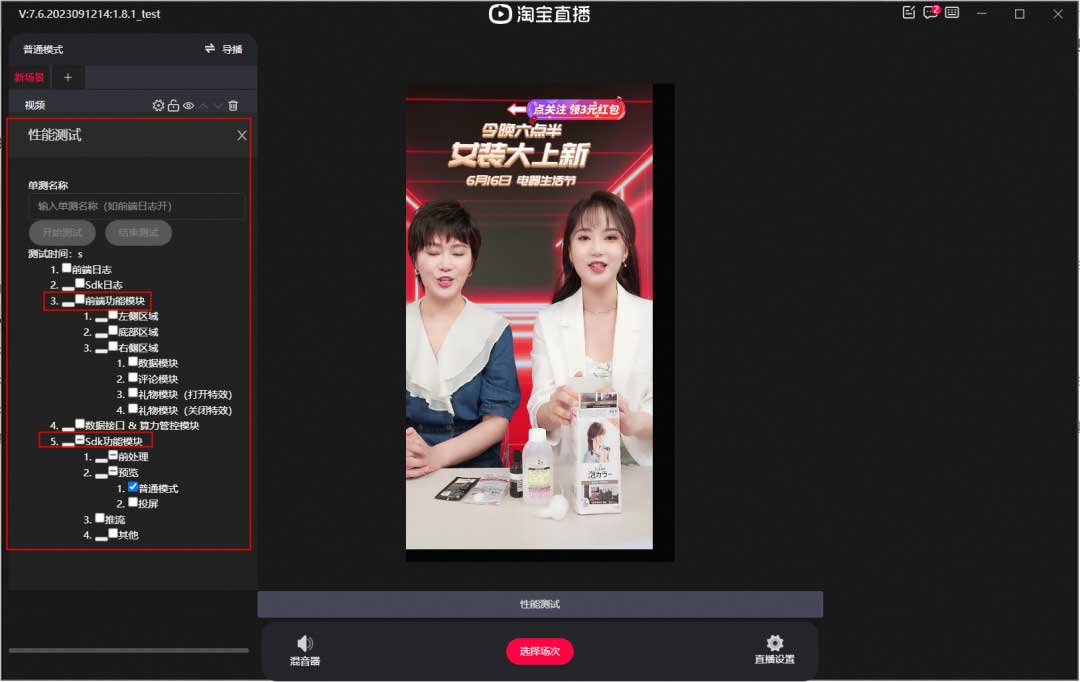
其中测试指标包括 CPU、单帧耗时、渲染输出帧率、GPU、内存、页面帧率、页面卡顿率等,而我们最关心的 CPU 是通过系统 api 获取(对齐业界通用的 ProcessExplorer 三方测试工具),需要在锁频情况下进行测试,CPU 锁频脚本如下:
@echo off
set key1=HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\intelppm
set key2=HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\Processor
set value=start
set newvalue=4
reg add "%key1%" /v "%value%" /t REG_DWORD /d %newvalue% /f >nul 2>&1
if %errorlevel% equ 0 (
echo Successfully changed %key1%\%value% to %newvalue%
) else (
echo Failed to change %key1%\%value% to %newvalue%
)
reg add "%key2%" /v "%value%" /t REG_DWORD /d %newvalue% /f >nul 2>&1
if %errorlevel% equ 0 (
echo Successfully changed %key2%\%value% to %newvalue%
) else (
echo Failed to change %key2%\%value% to %newvalue%
)
pause通过使用性能测试工具进行摸底测试,我们发现了一些模块的性能问题,如轮询请求、baxia、纯净流、端智能、美颜、推流等模块。下面分别从前端和客户端的视角进行性能优化介绍。
- 前端页面性能优化
由于 Electron 集成了 Chromium 内核,因此 Electron 应用的前端页面也可以用 performance 面板来分析性能问题,并进行性能优化。
场景元素操作耗时优化
当我们推纯净流时,推流页面创建的场景元素越多导致操作耗时越长。通过 performance 面板录制后分析发现会重复调用 DuplicateSource NAPI 接口,而该接口调用一次需要花费 100 ms ~ 500 ms。
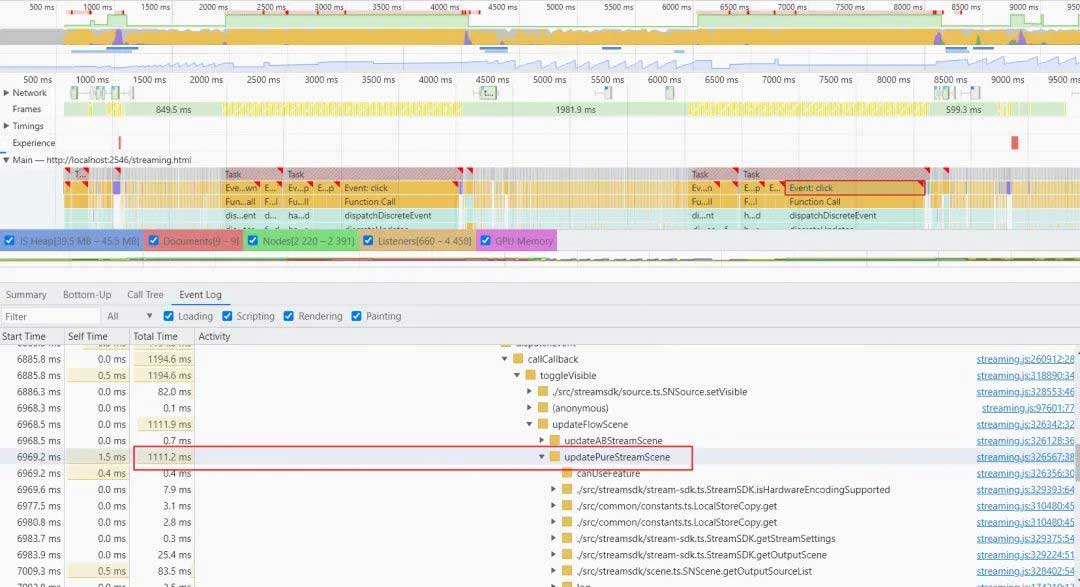
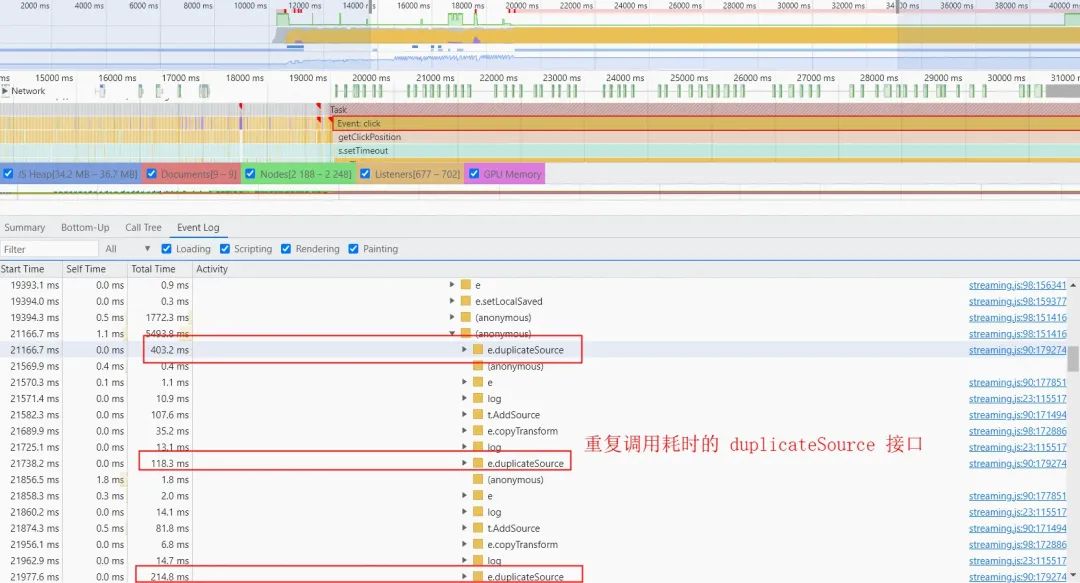
因此,针对纯净流场景进行性能优化,当场景元素变换时只 copy 变更的元素,将 DuplicateSource 接口调用次数降为 1 次,且不会随着场景元素的增加而增加,经测试发现场景中有 50 个元素时操作耗时从 30s 降为 1s。
baxia 安全逻辑耗时优化
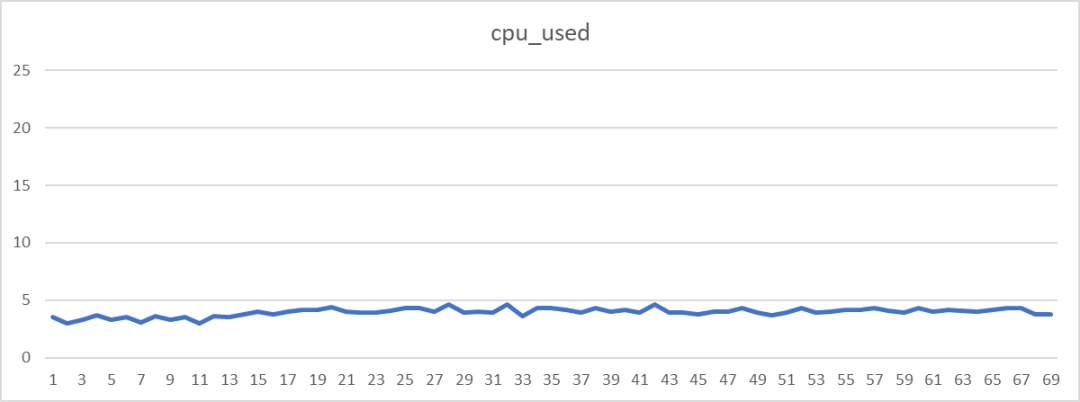
在性能摸底测试时,发现 PM 消息推送过程存在 CPU 间隔性飙升的情况:
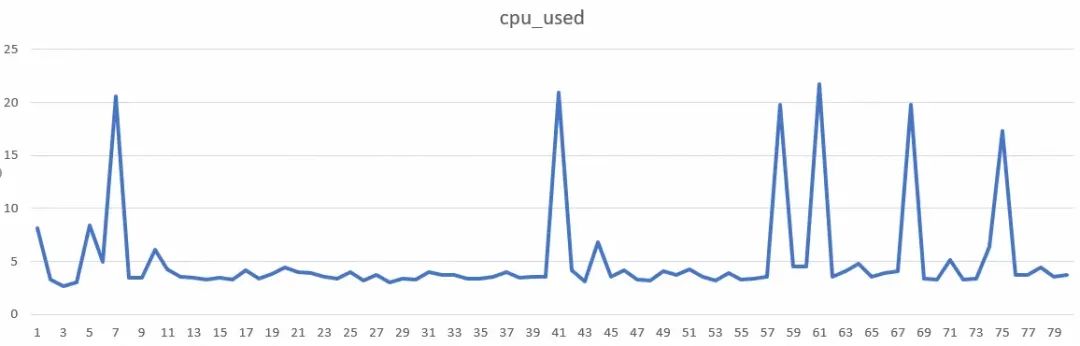
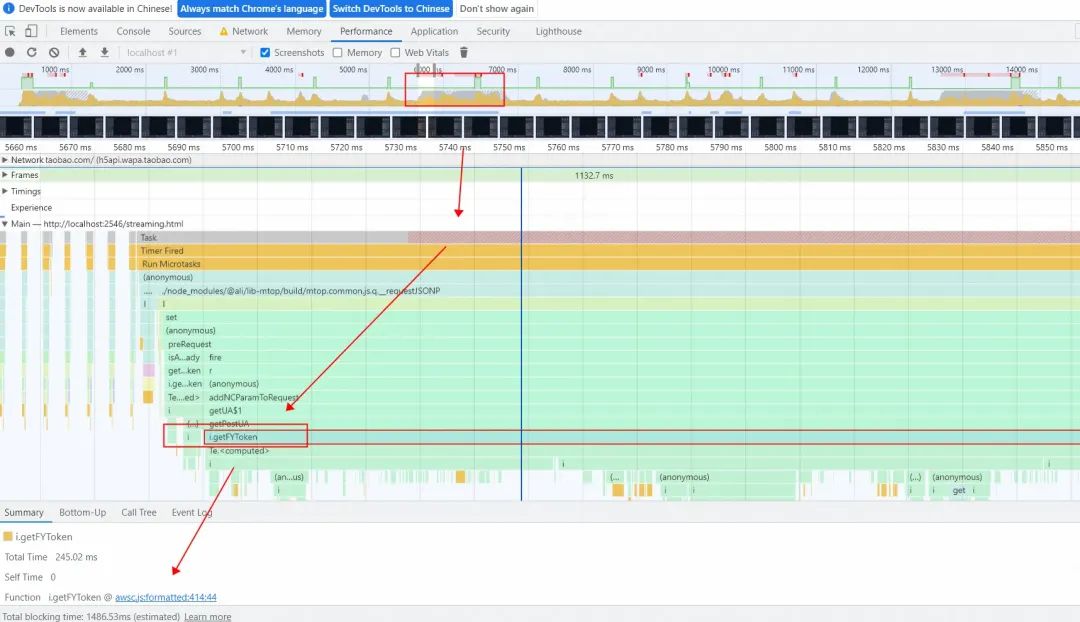
一开始怀疑是 PM 解析消息时消耗 CPU,但通过 performance 面板录制后(下图左侧是长任务,右侧是各个 js 耗时占比),分析原因发现是 baxia 引入的 fireye.js 里调用的 getFYToken 接口(采集底层及硬件信息)非常消耗性能。
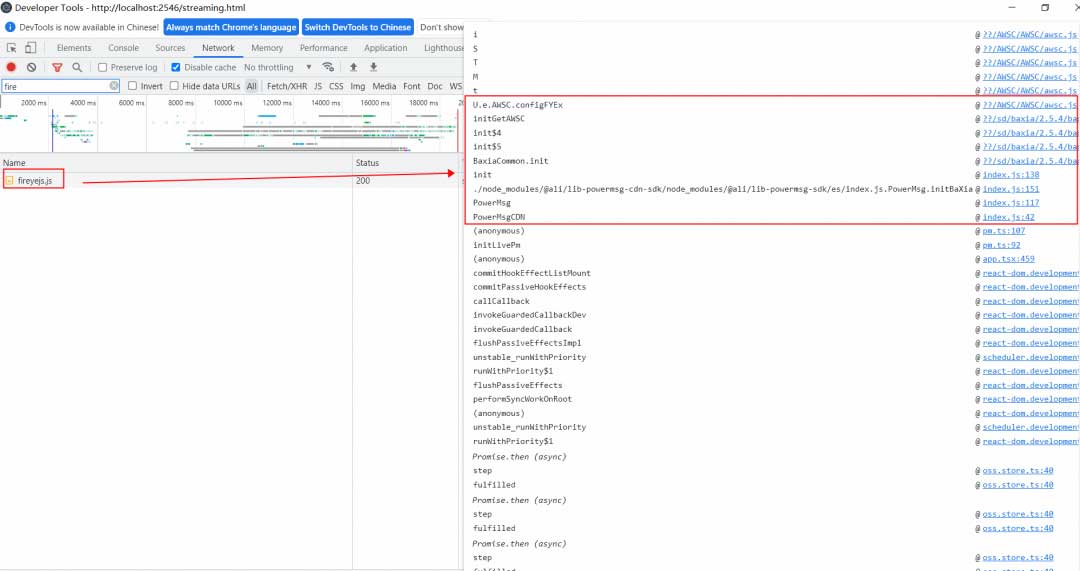
那为啥是 PM 消息推送时会有这个性能问题呢?原来是因为 PM SDK 也用到了 baxia 的 fireye.js 脚本(AWSC),而该脚本是为了防爬、防刷、人机等安全能力。
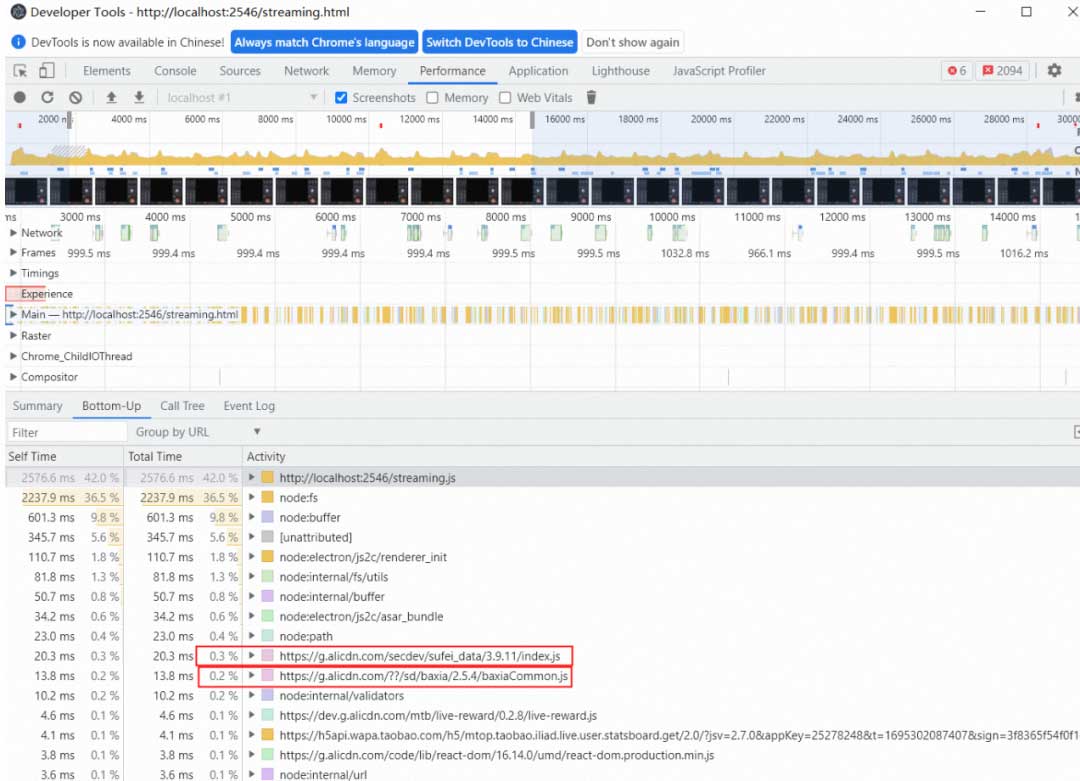
由于我们应用接的 baxia 并没有使用到 AWSC,评估后可以将相关耗时(采集底层及硬件信息)接口函数置空即可:
(window as any).AWSC = { use: () => {}, configFYEx: () => {} }经过处理后,baxia 模块耗时占比只有 0.5%,而且 CPU 使用率非常平稳,不再有飙升情况:
- 客户端性能优化
前面所介绍到的是以前端视角进行性能优化的,那客户端有没像 performance 类似的性能分析工具呢?常用的主要是 Visual Studio 和 Windows Performance Analyzer。
Visual Studio:除了用来日常开发外,调试面板还有个性能分析器功能,可用于帮助开发者分析和优化程序的性能。但是测试发现将 pdb 调试符号映射上后也只能解析出系统动态库及 electron 框架自身的代码,无法进一步解析出应用业务模块代码。
了解完客户端常用性能分析工具后,我们就可以利用这些工具进行性能优化。由于我不直接参与客户端底层的性能优化,只是从应用层面配合优化,因此我只是介绍下整个应用经过一轮性能优化后,大盘 CPU 超过 65% 的直播场次占比从 13% -> 6.7%,工程侧 CPU 占比从 34.5% 降为 9.4%:
- 前处理切独显渲染
- 电脑配置较差时美颜相关算法策略调整
- 采集输入帧率及输出帧率优化
- 端智能智能看点下线及安全相关算法频次调整
- 纯净流默认策略调整
- ARTC 日志优化
- 推流低帧率治理及 264 ultrafast
- ……
03 如何监控淘宝直播 PC 推流端性能
上文提到的只是应用里众多性能问题的几个 case,然后基于本地性能工具进行 case by case 分析优化。那我们是不是可以把性能监控起来,主动发现运行时性能问题并制定一些降级策略呢?
首先我们要明确哪些是应用关心的性能指标,比如淘宝直播 PC 推流端主要看重如下几个性能指标:
前端性能指标
- 页面帧率及卡顿率
- NAPI 及长任务耗时
客户端性能指标
- CPU
- GPU
- 单帧耗时
- 画面帧率
- 内存
其次我们应该如何采集这些性能数据呢?
采集性能数据
- 前端性能指标
页面帧率及卡顿率
我们知道 chrome performance 工具的 Rendering 面板里把 FPS meter 选项勾选上之后,就可以统计出页面帧率。
那从代码层面要如何获取呢?其实可以通过 requestAnimationFrame API 来统计一段时间内的页面帧率(如一秒内有多少帧,就是我们常见的 fps),实现代码如下:
const detectPageFPS = () => {
let lastFameTime = performance.now()
const loop = () => {
const curFrameTime = performance.now()
// 统计每一帧耗时
const fpsTime = curFrameTime - lastFameTime
lastFameTime = curFrameTime
window.requestAnimationFrame(loop)
}
loop()
}然后我们参考业界定义卡顿的标准,当帧与帧之间间隔超过 200 ms 时就认为一次卡顿。最后就可以通过卡顿时间总和 / 总时长得出页面卡顿率。
NAPI 及长任务耗时
首先我们先来了解下 NAPI 是 Node.js 官方提供的一个用来编写 C/C++ 插件的稳定模块,而在淘宝直播 PC 推流端中,推流页面里(如场景元素操作)都是通过 NAPI 接口调用 C++ 的 obs、race、artc 等模块,目前有 200 个 NAPI 接口。
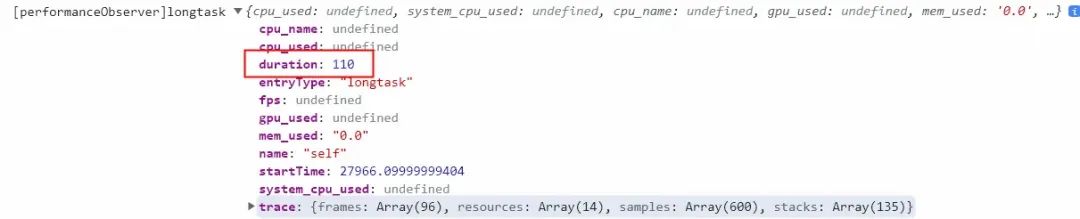
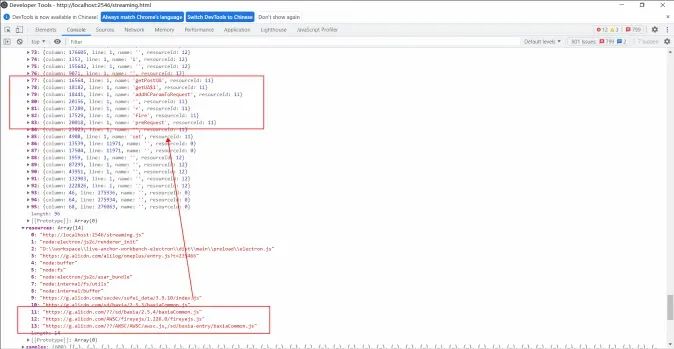
那我们要怎么统计这么多 NAPI 接口耗时呢?Chrome 提供了一个专门用于性能监控的 web API:PerformanceObserver。PerformanceObserver 主要用于监测性能度量事件,在浏览器的性能时间轴记录新的 performanceEntry 时会以回调的方式通知 observer,通过 PerformanceObserver 我们就可以用代码的方式拿到用户本地真实的性能耗时数据了。
首先在每个 NAPI 接口前后标记 mark,并注册 measure 事件:
performance.mark(`${NAPI} startTime`)
// NAPI 接口调用
performance.mark(`${NAPI} endTime`)
performance.measure(`[PerformanceMeasureSdk]${NAPI}`, `${NAPI} startTime`, `${NAPI} endTime`)然后监听 measure 事件,就可以获取到所有已经标记的 NAPI 接口耗时了:
const performanceObserver = new PerformanceObserver(async (list, _obj) => {
const perfEntries = list.getEntries()
for (let i = 0; i < perfEntries.length; i++) {
const p = perfEntries[i]
logger.info(`[Performance]performanceObserver ${p.entryType}`, p.duration)
}
})
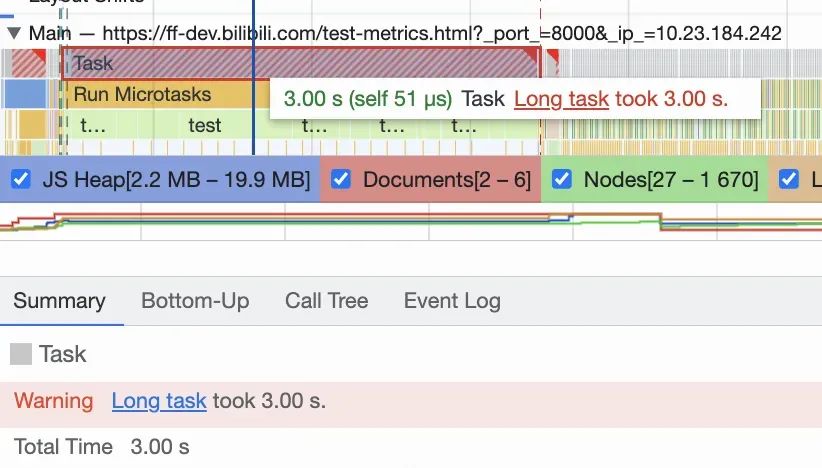
performanceObserver.observe({ type: 'measure', buffered: true })至于长任务耗时,之前是从 chrome performance 面板录制获取(如下图所示),我们也可以通过上文提到的 PerformanceObserver API 来实现。在介绍如何捕获卡顿之前需要先搞明白一个概念,究竟什么是长任务?长任务是指长时间(大于等于 50ms)独占主线程,导致界面卡顿的 JavaScript 代码,比如以下常规场景:
- 长耗时的事件回调
- 代价高昂的回流和其他重绘
- 浏览器在超过 50 毫秒的事件循环的相邻循环之间所做的任务
介绍完长任务后,我们可以通过以下代码来获取:
let profiler = new (window as any).Profiler({ sampleInterval: 10, maxBufferSize: 10000 })
const performanceObserver = new PerformanceObserver(async (list, _obj) => {
const perfEntries = list.getEntries()
for (let i = 0; i < perfEntries.length; i++) {
const p = perfEntries[i]
const trace = await profiler.stop()
logger.info('[Performance]performanceObserver longtask', trace)
// 重新开始记录
profiler = new (window as any).Profiler({ sampleInterval: 10, maxBufferSize: 10000 })
}
})
performanceObserver.observe({ type: 'longtask', buffered: true })在此基础上,我们还可以在触发长任务事件时,使用 js-self-profiling API 把 js 堆栈也一起 dump 下来分析。但因安全问题浏览器默认是不开启的,需要通过拦截请求添加 Document-Policy: js-profiling 响应头来实现:
// 拦截请求,添加 Document-Policy: js-profiling 响应头
win.webContents.session.webRequest.onHeadersReceived(
{
urls: ['*://*/*'],
},
(details: Electron.OnHeadersReceivedListenerDetails, callback: any) => {
if (details.responseHeaders) {
details.responseHeaders['Document-Policy'] = ['js-profiling']
}
callback({ cancel: false, responseHeaders: details.responseHeaders })
},
)最终就可以采集到长任务耗时并抓取 js 堆栈了:
在此基础上,我们还可以利用 PerformanceObserver API 监听 resource 来收集网络请求的信息,也可以监听用户触发的 click 事件来获取用户触发的 DOM 元素,结合前面的 js 堆栈综合分析长任务耗时的性能问题。
- 客户端性能指标
目前应用内的 CPU、GPU、单帧耗时、画面帧率、内存等性能指标都是通过 SDK 获取的,获取方式也比较简单,就不再赘述。
上报性能数据进行算力管控
上文已经介绍了前端、客户端性能指标是如何采集的,接下来就会每隔 10 秒用 UT 接口汇总上报这些性能数据到 Medialab 平台进行监控。
同时,我们也实现了一套算力管控策略。当开始推流时,编码器检测到每 2 分钟内编码帧率 < 15 fps(720p)、18 fps (1080p)(可配置) 时,回调算力状态及原因给前端,进行算力管控(所有管控策略都支持动态配置,包括管控等级和顺序、管控指标、管控项等):
- 第一级:当前应用 CPU < 30% 时,检查是否存在高消耗外部应用,提示用户手动关闭占用高的外部应用
- 第二级:低采集帧率提示,检测到当前摄像头设备帧率过低时给与提示
- 第三级:切硬编
- 第四级:降帧率(720p 最低 20 fps,1080p 最低 25 fps,自动降级不提示),并自动关闭端智能、纯净流、礼物特效播放等功能
- 第五级:开启了美妆、AI磨皮等高功耗功能时,提示用户手动关闭这些功能
- 第六级:降分辨率(toast 提示用户已降级,已有功能)
经过算力管控优化后,我们大盘推流卡顿率降低了很多。
04 总结及展望
总结
基于线上用户反馈的性能问题,我们运用本地性能工具优化了启动耗时(应用启动耗时从 10s -> 2.5s,推流页面启动耗时从 5s -> 50 ms)、运行时性能优化(包括前端页面交互耗时优化、客户端性能优化),并提出可以把性能指标(包括页面帧率及卡顿率、NAPI 及长任务耗时、CPU、单帧耗时等)监控起来主动发现运行时性能问题并制定一些降级策略。
展望
接下来还可以做的事情是继续优化应用的 NAPI 及长任务耗时,优化应用 CPU、单帧耗时等性能指标,针对应用性能风险提示可以分系统、应用、功能模块进行降级处理。
团队介绍
我们是淘天业务技术淘宝直播B端终端团队,负责淘系增长非常快的直播业务,业务上升空间非常大。在技术方面,我们在探索直播间互动、游戏互动、数据可视化、音视频播放器、微前端、智能搭建、Web 3D、Electron跨端开发、桌面推流客户端开发、跨 PC/H5/Native 的多端架构等。在这里你有机会通过一行代码为业务创造亿级 GMV 增量,期待优秀的你!
作者:科来 大淘宝技术
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
