
淘宝人生2(又名:第二人生)是淘宝的一个虚拟人装扮类应用,承担了用户在淘宝的第二个人生的作用。我们旨在通过AI为淘宝人生2的用户提供丰富有趣的可玩性内容,随着最近火热的AIGC技术的发展,我们也进行了相关尝试和落地,目前已经上线了AI拍照风格化、AI写真馆、AI服饰涂鸦等项目。本文主要以AI服饰涂鸦为例介绍我们在AIGC图像领域的探索和应用,希望能够对大家有所启发和帮助,也欢迎大家建议和合作。
01 项目背景
为了能够让淘宝人生2的用户拥有更多可互动性的有趣玩法,提高社区内容发布量,我们开发了AI服饰涂鸦项目,能够让用户自行创作生成相关服饰,增加用户的参与感和成就感。具体玩法主要是:通过选定一张底图,用户可以在图上进行自由涂鸦和创作,同时也支持输入文字描述,然后通过AIGC算法技术,最终生成和用户涂鸦相像的高质量风格图像。下列涂鸦来自淘宝人生2的用户创作:

02 前置技术介绍
本节内容主要是简介一些项目使用到的关键技术,不会长篇大论进行具体的理论分析,只是让大家有一个大致的了解,如果想深入了解相关的原理可以查看论文或者网上大佬们的文章博客。
Stable Diffusion
在具体图像生成算法选择上,我们选择以Stable Diffusion(后续简称为SD)技术为核心,进行开发和优化。其核心是基于Latent Diffusion Models(LDMs)实现的的文生图模型,SD模型基于Latent的扩散模型的优势是因为图像的Latent空间要比Pixel空间小得多,计算效率更高效。下图是其主要框架结构,它先采用AutoEncoder能够将图像压缩到Latent空间,然后通过扩散模型并在U-Net中引入TextCondition来实现基于文本生成图像的Latents,最后送入AutoEncoder的Decoder模块解码得到生成的图像。
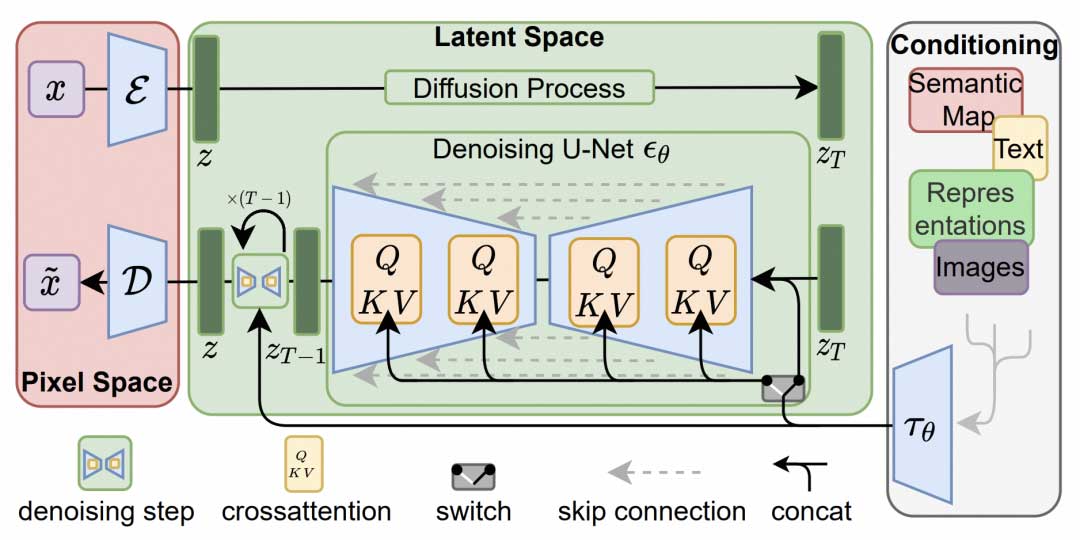
SD模型主要包括了三大件:图像压缩还原模型(变分自编码器VAE),文本编码器(CLIP Text Encoder)和潜空间扩散模型(U-Net结构)。
- VAE:其分为Encoder和Decoder两部分,Encoder将图像压缩到Latent空间,而Decoder将Latent解码为图像。
- CLIPTextEncoder:理解输入的文字描述,把文字信息转换成特征向量,并注入到扩散模型的UNet中,指导图像生成。
- UNet:扩散模型的主体,在潜空间中逐步处理扩散信息,用来实现文本引导下的图像Latent生成。
SD更深入的原理和具体训练过程和我们在这不详细展开,我们关注其整体的推理部分,我们将上述三个大模块组合一下,以一个具体示例进行展示:
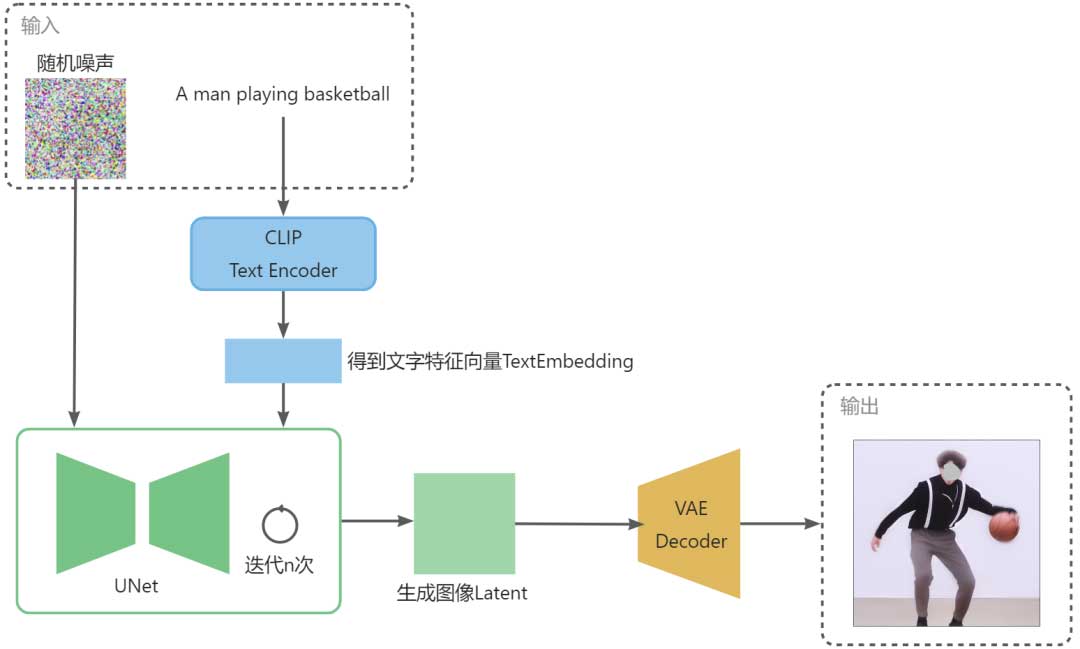
通过上面展示的SD流程,我们即可实现给定一段文本描述prompt后生成相关的图像。
ControlNet
上面SD模型能够通过prompt以及image的输入,生成一张图像,但是其生成的图像不太可控,具有一定的抽卡性质,有非常多千差万别的图像符合输入描述的文本。
而ControlNet的出现,将AI绘画推向了高峰,ControlNet是一个神经网络架构,该网络可以控制SD模型使其支持更多的输入条件,提高图像生成模型在特定结构和布局控制上的能力。
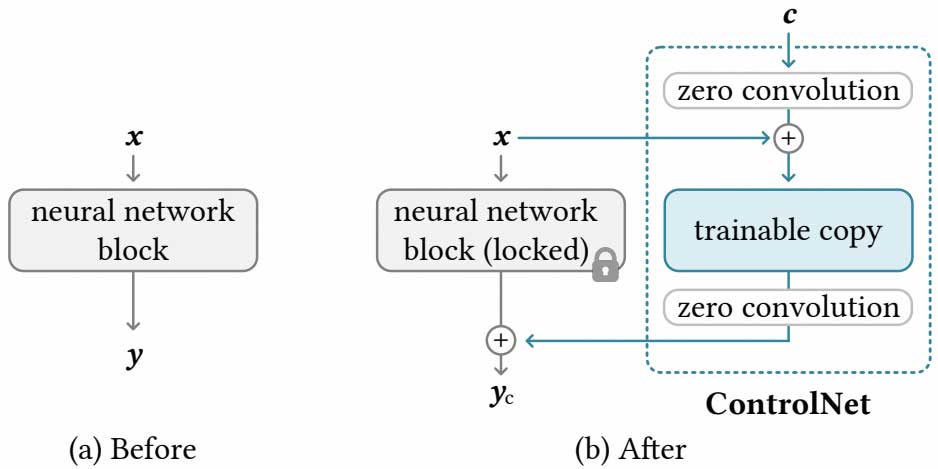
图中ControlNet结果的locked部分固定了原始模型的权重,保留原始模型已经学习到的图像生成能力,通过额外学习网络参数加入到原始模型中,以最终控制图像的生成。其中zero convolution是一个1×1的卷积层,初始化权重和偏差都为0,以保证训练初始阶段随机噪声不会影响主干网络。ControlNet在SD模型中应用的结构如下:
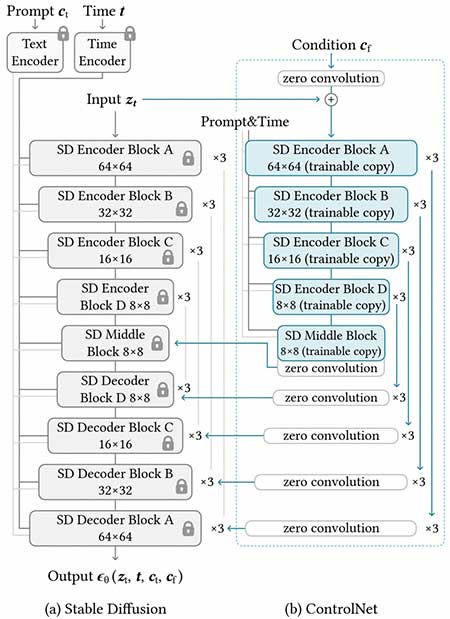
通过不同的控制条件作为输入输出训练,即可实现通过物体边缘、人物姿态、深度图等等条件来控制SD模型推理得到的图达到和输入布局类似的效果。一些不同控制条件下的SD+ControlNet生图效果:

LoRA
由于大模型的训练需要非常高的数据和机器资源成本,即使是进行 Fine-tuning微调也需要较多算力资源的消耗。而LoRA(Low-Rank Adaptation)的提出,便大大节约了算力、提高了效率,它能够让下游细分领域任务的微调大面积应用起来。其最初是为LLM大语言模型设计的低秩适配器,一开始SD并不支持LoRA,据说Simo Ryu是第一个让SD支持LoRA的人。
其主要原理是假设模型在适配特定任务时的参数改变量是低秩的,通过低秩分解来模拟参数的改变量,从而实现间接的训练神经网络的参数,由此引出低秩自适应方法LoRA。
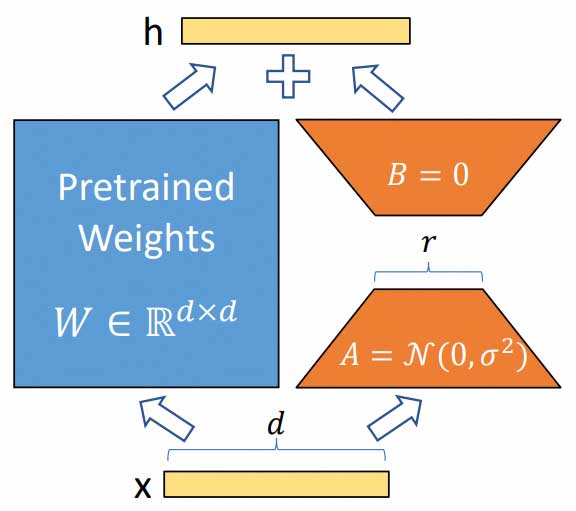
LoRA在SD模型中的训练逻辑是首先冻结SD模型的权重,然后在SD模型的U-Net结构中注入LoRA模块,并将其与CrossAttention模块结合,并只对这部分参数进行微调训练,其中低秩分解是由两个低秩矩阵的乘积组成。LoRA模型能在较小的数据集上进行训练,即使是几张图像也能够完成特定的细分领域微调任务。
虽然LoRA模型能够比较好的适应特定的任务比如图像风格化,但是总体来说在图像的多样性和泛化性上还是有所欠缺的,因此我们在项目中大部分情况下不同的风格还是选择使用不同的底模。
03 生图服务部署
目前大家常用的SD服务,主要是SD-WebUI和ComfyUI,但是对于一个有特定业务需求且要提供给大量用户使用的在线服务而言,稳定性、代码可控性、定制开发、开源协议等等方面都有一定的要求,因此我们基于集团内部已有的能力,站在巨人的肩膀上搭建了基于diffusers库二次开发以适应我们自己业务的SD生图框架。
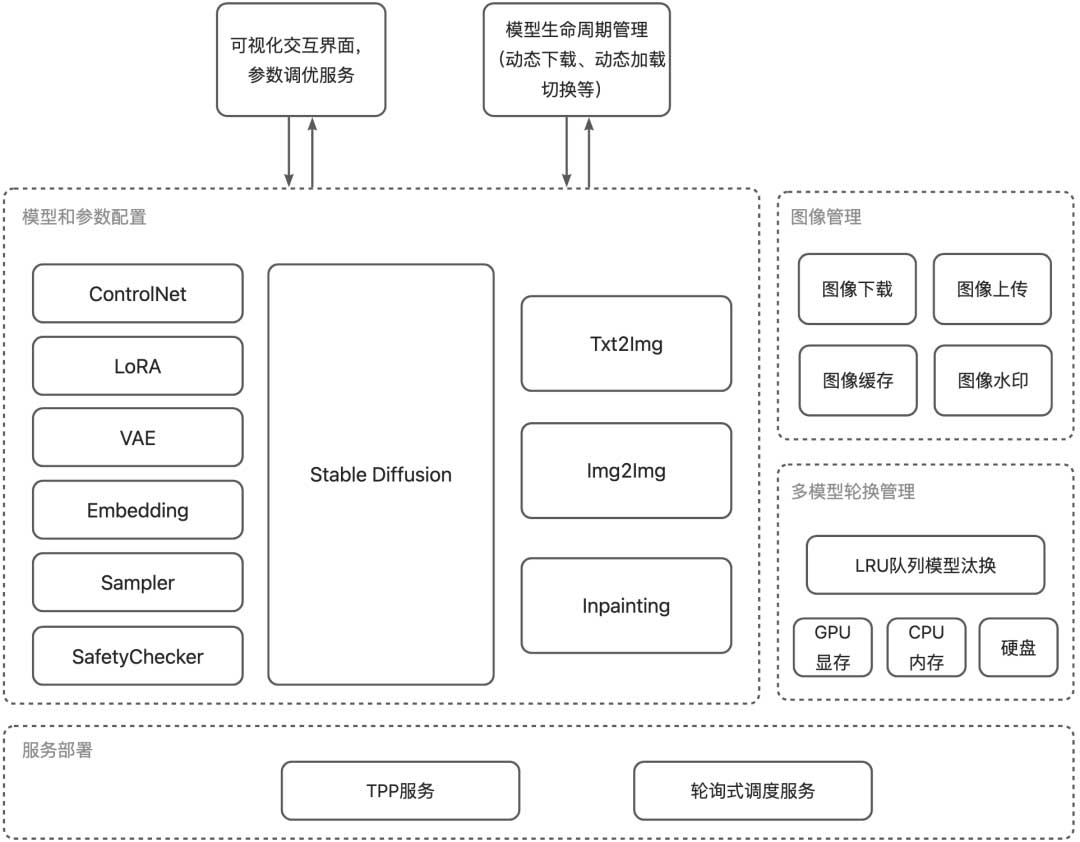
该框架能够通过json入参配置SD绝大部分功能如ControlNet、LoRA、VAE、Sampler等等模块,并使用集团模型加速库来实现高效的文生图和图生图等。
同时也提供了类似于sd-webui的界面方便进行prompt和模型等的参数调优,对模型的下载加载、生命周期管理和图像的管理也进行了开发和优化。
模型管理
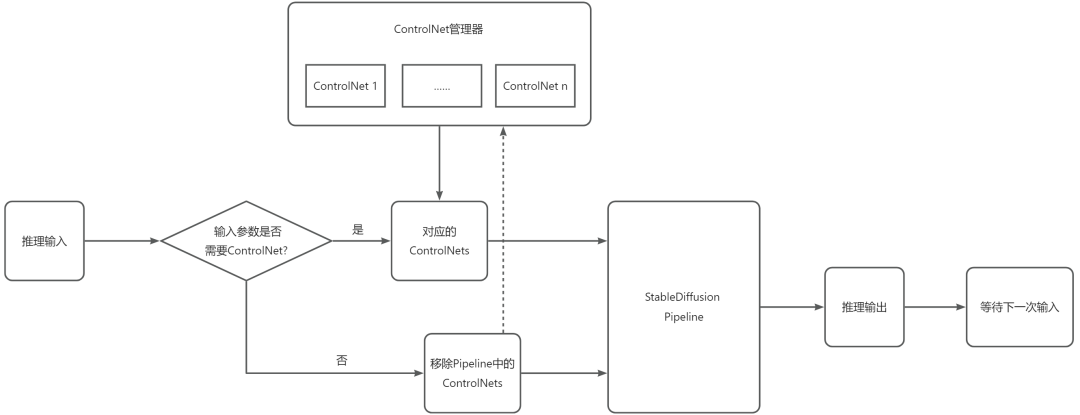
我们对原始SD代码流程进行了优化,将ControlNet作为可插拔的模块进行管理,对ControlNet模型进行缓存,在初始构建SD的Pipeline时,不指定使用的ControlNet,而是在SD模型推理的时候,根据参数来决定动态加入ControlNet,这样做的好处是带ControlNet和不带ControlNet的SD可以共用一个Pipeline,在输入参数变化的时候避免Pipeline切换带来的开销,同时对ControlNet模型的单独管理,也能够使ControlNet在不同底模上的复用。同理,LoRA模型也是类似。
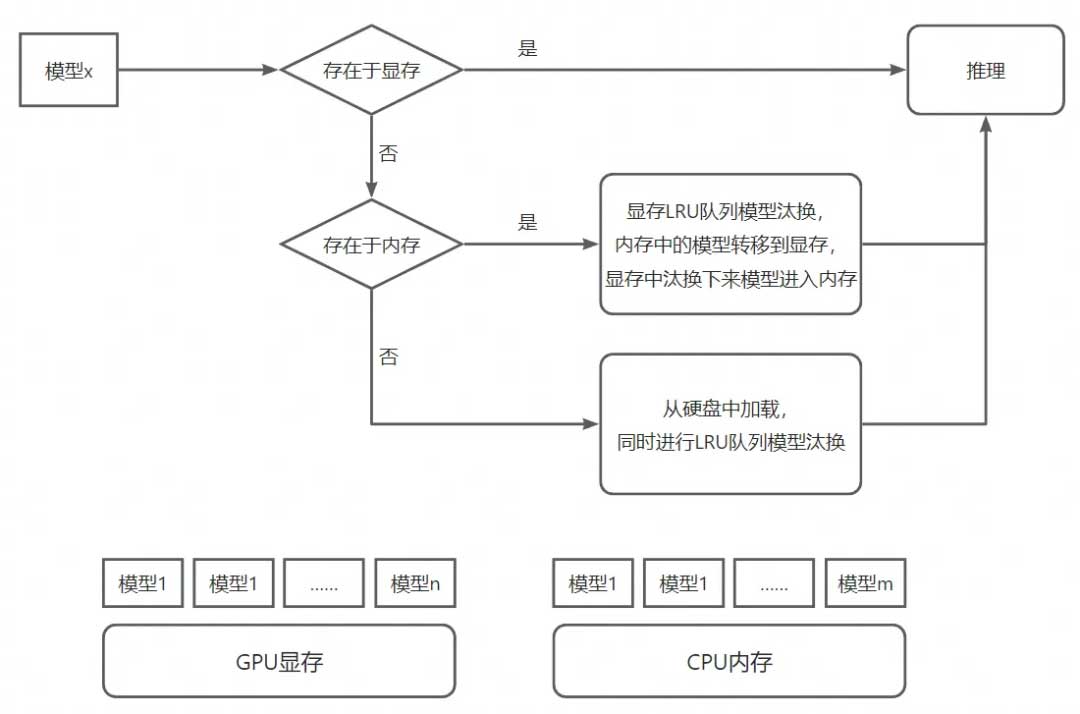
对于场景只有单个底模的业务来说,提前初始化好Pipeline并加载好底模,问题不大。但是许多业务场景下存在多个底模切换推理的问题,而底模通常都非常大,直接从磁盘加载会存在高达几十秒的耗时,这对于在线推理来说是不可忍受的。
显然,我们可以把需要的底模都提前加载到GPU,切换的时候就不需要再重新load,反正推理的时候还是只有一个模型在推理,不会影响推理速度,实现无缝切换。但是GPU显存毕竟是有限的,考虑到从内存转移到显存比直接从磁盘load还是快很多的,而内存可以扩展的更大,因此对于底模的管理,我们加入了显存-内存的LRU队列汰换策略,可以做到支持同时load n个模型进显存(取决于你的GPU显存),同时将m个模型load进内存(取决于你的内存容量),然后通根据入参通过LRU策略进行显存和内存之间的转移和推理。
服务部署
一般常规的方式,是用户发起请求,服务器接受请求,然后分发到空闲的GPU机器进行推理,最后返回。我们采用集团的TPP服务平台,由vipserver绑定了多台GPU机器,然后通过TPP调用vipserver的方式进行服务调用,但是发现实际调度的时候存在负载不均衡的情况,会出现1台机器空着,1台机器在排队的情况,以及存在超时的问题。可能是由于我们的业务场景相对来说QPS较小推理时长较大,对于这种方式的调度没有做针对性优化。
因此,我们需要寻找一种可以榨干GPU的方案。可以想到的是,自己建立一个中心化的请求服务器,所有GPU机器向它报告自己的空闲状态,然后根据机器状态进行用户请求任务的分发。同时我们了解到服务端同学那边之前已经为离线渲染任务做了请求轮询拉取的方案,由于时间和成本关系,于是我们就直接采用了这种方式。所有请求先进入服务端的任务队列,由服务端进行超时、重试、限流等策略控制,算法部署的GPU机器直接对任务队列进行轮询,只要拉取到任务后进行推理返回即可。这样就解决了负载均衡的问题,但是不足的是可能存在轮询的百ms级的时延问题,但是对于大模型推理时间来说这也是可以接受。
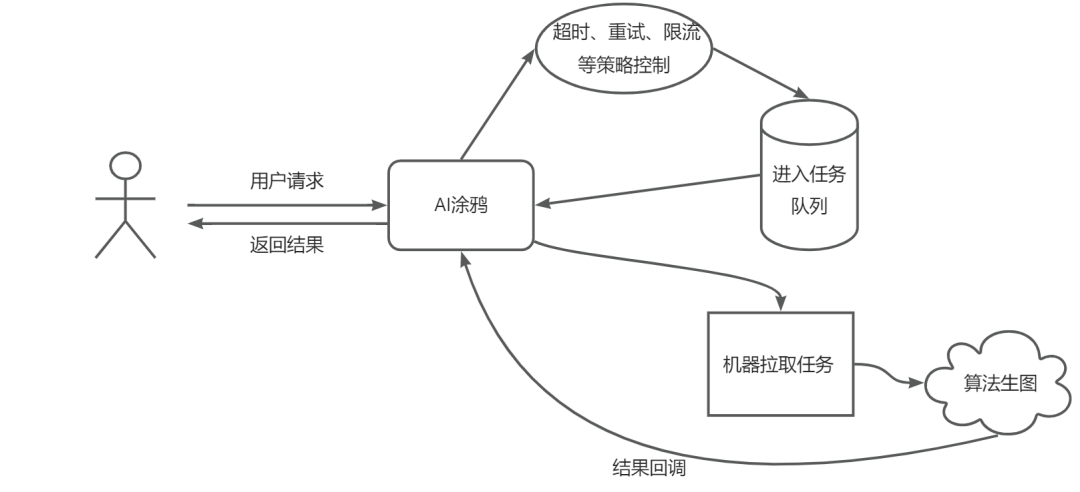
涂鸦项目
回到我们的AI服饰涂鸦项目,我们整体的Pipeline是采用基于SD的文+图+Controlnets来对用户涂鸦进行风格化。针对每期的主题风格,我们会对模型、prompt等参数进行调优和部署,其中用户的涂鸦和背景底图是分别进行传输的,我们对其进行合成后编码成图像潜空间特征,作为初始噪声替代原始SD文生图的随机噪声,文本输入我们以预先设定的prompt和用户自己输入的prompt叠加进行文本特征提取,再选择几个合适的ControlNet对生成图像布局进行一定的约束,最终生成和用户涂鸦相似又不失美感的服饰图像。
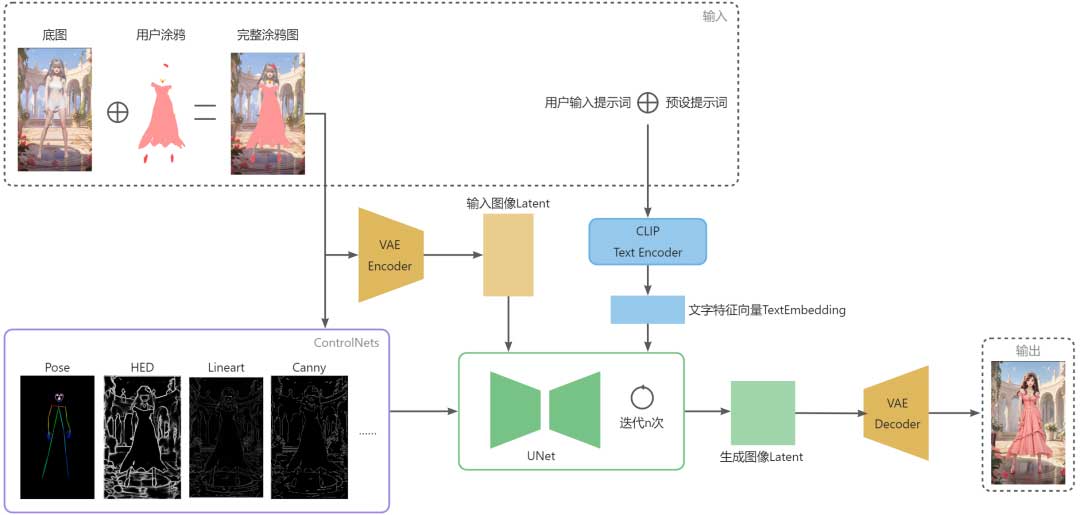
考虑到用户有调皮鬼,可能会把图全部涂黑或者涂满随便画,所以需要加入ControlNet的Pose模型来约束生成人物,同时考虑到用户涂鸦后会破坏人物Pose的识别,所以使用的是对涂鸦前的原图进行识别,最后这样即使乱涂也能生成一定的人物。
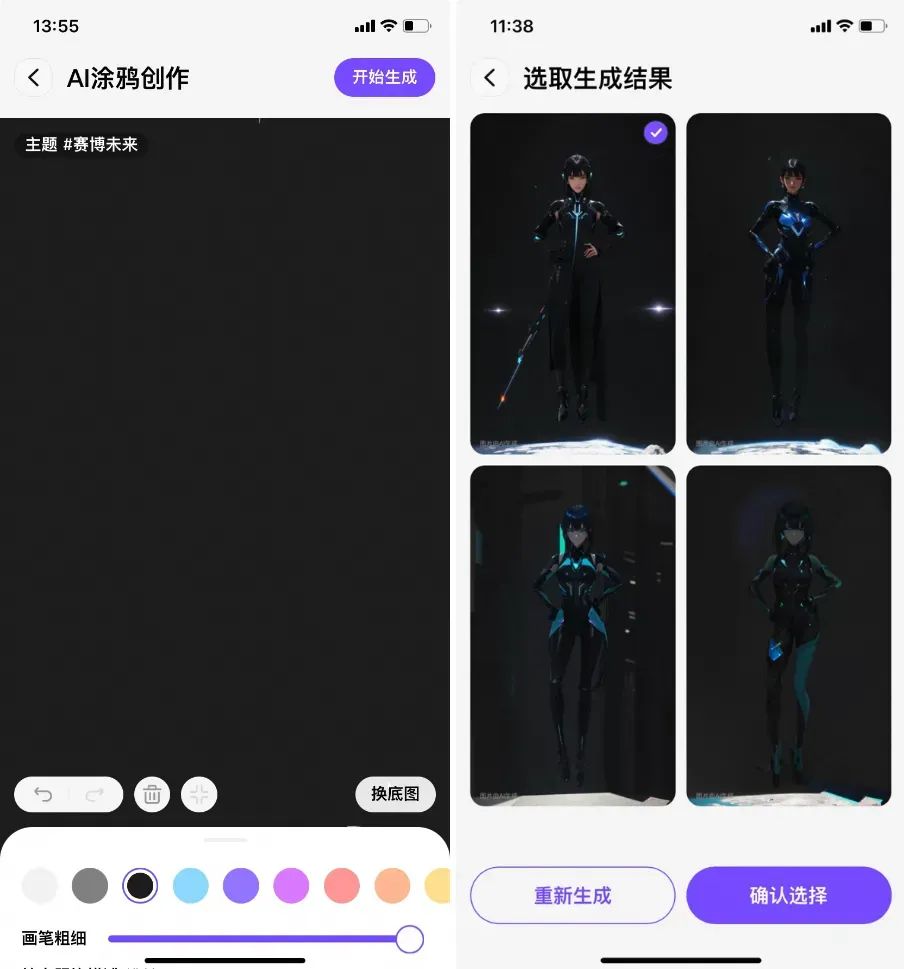
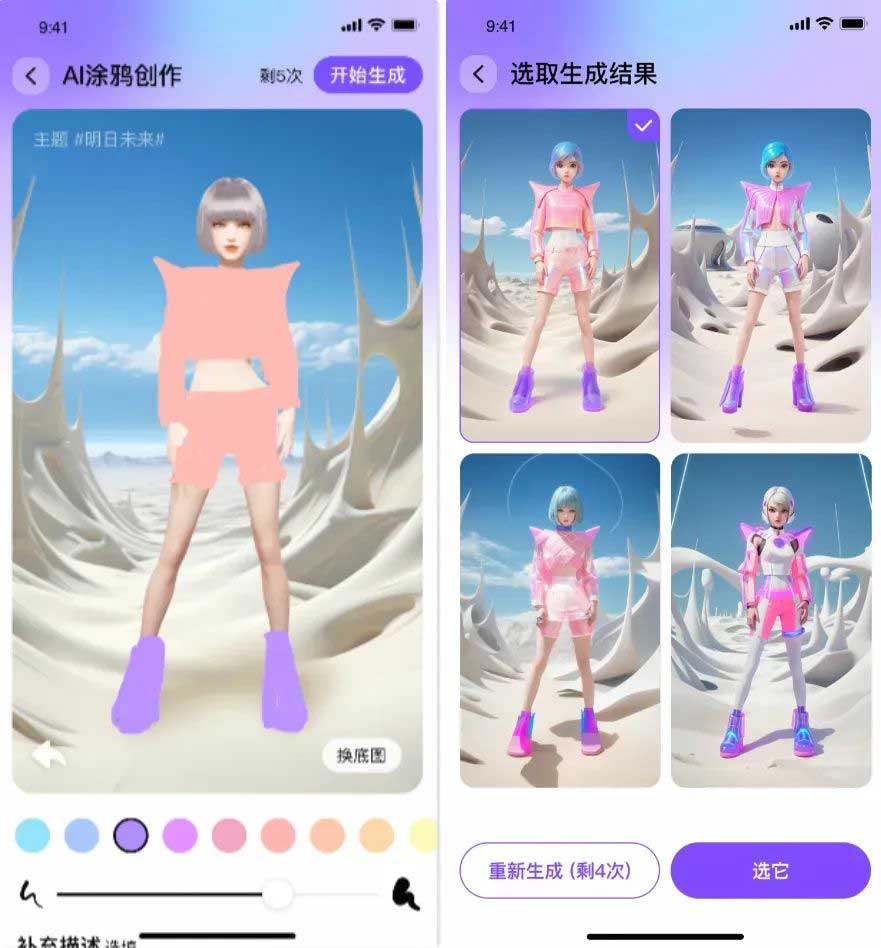
生成多张图
为了让用户一次涂鸦生成多张图片进行挑选,一种最简单的方式就是直接使用4个不同随机种子作为噪声扰动,生成4张不同的图,而由于我们的Pipeline加入了较多的约束信息,会导致这种方式生成的图结果差异性不大。于是我们提供了2个底模4套参数分别来生成4张图,使其跟涂鸦图相似的同时又具有较大的差异性。
目前为了生成较为精美的图像,我们使用了较大分辨率和较高的迭代步数,以至于生成一张图像要接近10s。如果生成4张图,直接串行生成,时间上要比较久了,考虑到用户体验肯定不能让用户等这么久。怎么办?
第一种方式:一张一张逐步返回。每生成完一张图返回一张,让用户每隔一段时间看到一张图,不至于等很长时间再一次性出图,但全部生成完的总体时间还是比较长。第二种方式:加钱。凡是能用钱解决的问题都不是问题,增加GPU推理机器,将用户的一次请求,由服务端分成4个并行任务,然后算法分别在4台机器上同时推理进行返回。最后选择了第二种方案,加机器减少用户的等待时间。
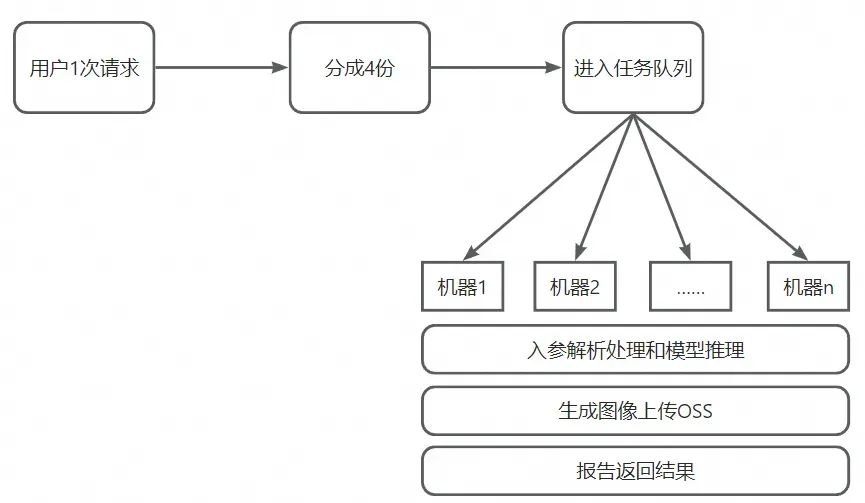
这时候有同学可能就要问了,不能直接在一台机器上同时推理吗?问得好,我们确实尝试过在一台机器上多实例同时进行模型推理,但是结果发现推理时长变长了,应该是受限于计算带宽的瓶颈,不足以支撑多个任务同时推理。
部分优化
我们将部分图片如背景底图和人物Pose图进行了缓存,因为这两种图像数量和样式是由运营配置的,是固定有限的,只需要第一次下载加载缓存后,后续遇到同样的图像可以直接取出进行处理,减少耗时开销。
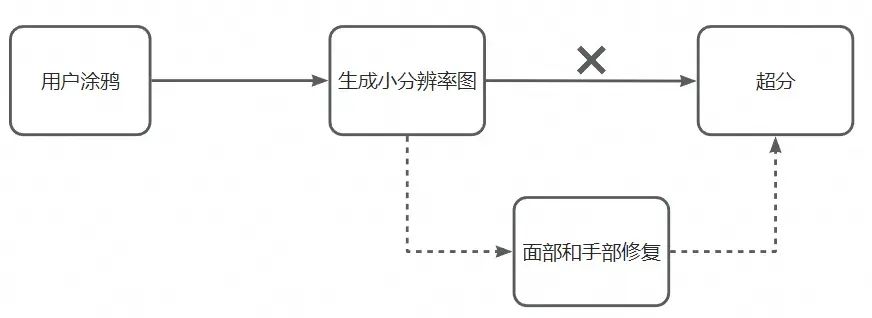
随着生图分辨率增大,推理时长急剧上涨,于是思考是不是可以先生成小分辨率的图再超分到大分辨率,说干就干。干完后发现耗时确实可以少不少时间,但是随之而来的是由于是生成全身像,脸部和手部的区域占比较小,导致其生成的崩坏问题比较明显,这显然无法通过超分解决,遂作罢,并将面部和手部修复作为后续优化手段。
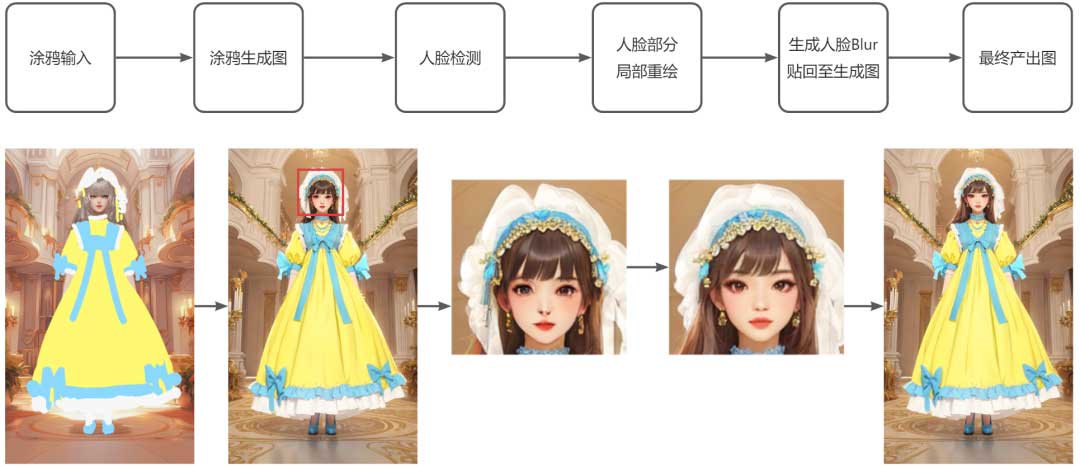
对于我们现在使用的生图分辨率来说,总体来看人脸部分相对来说还是较小,还是会出现生成的人脸有点不和谐的情况,所以加入面部修复被提上了日程。我们首先对SD生成的图像进行人脸检测,然后对人脸部分再使用SD的图生图功能,对人脸部分进行重新生成,最后将生成的人脸进行Blur后贴回到前面的图上。
随着我们主题的上新,模型数量也在不断增加,为了保证耗时和资源利用率,除了通过之前介绍的底模LRU汰换策略之外,我们也在探索其他可优化的方式。
敏感图问题
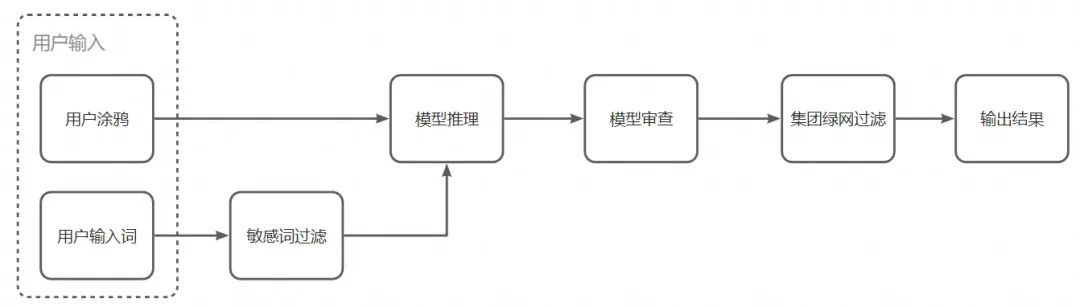
为了避免有比较暴露的图出现,我们加入了一些策略来进行控制。首先我们对输入敏感词进行了一定的过滤,在SD生图中也加入了一些负向提示词,然后SD模型提供了SafetyChecker能够对生成的图像进行过滤,但是其对偏卡通的图像存在一些误检情况,我们对其阈值进行了调整,最后由服务端再送入集团绿网进行检测过滤。
上线撒花
经历了种种磨难,最终成功上线,撒花。用户反响不错,用户的创作水平也非常的可以!放几张来自用户的创作:
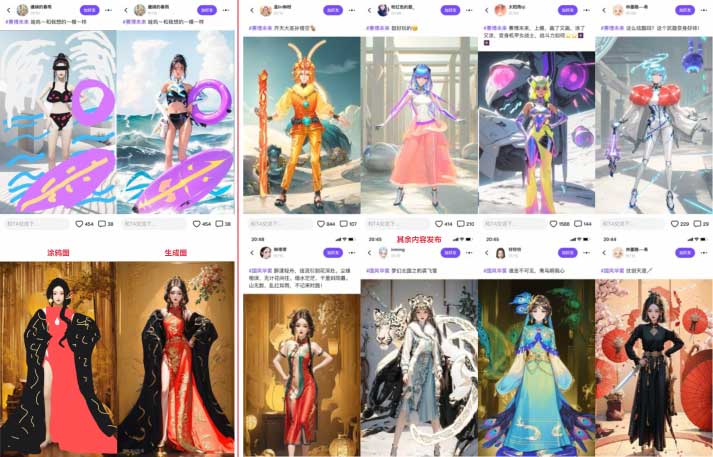
快来淘宝APP进入淘宝人生2,开启你的第二人生,创作属于你的AI涂鸦服饰吧!
引用
[1] https://arxiv.org/abs/2112.10752
[2] https://arxiv.org/abs/2302.05543
[3] https://arxiv.org/abs/2106.09685
[4] https://github.com/AUTOMATIC1111/stable-diffusion-webui
[5] https://github.com/comfyanonymous/ComfyUI
[6] https://github.com/huggingface/diffusers
团队介绍
我们是淘天集团-FC技术部-智能策略团队,主要负责手机天猫搜索、推荐、AI创新等业务研发,以及淘宝人生的AI互动玩法的研发,致力于运用搜推算法、计算机视觉、AIGC等前沿技术,为用户带来更好的购物体验和内容创作。欢迎搜索推荐相关以及AIGC相关的算法同学加入我们,简历可投递至zhujianbo.zjb@taobao.com。
作者:玄羿
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
