
本文将介绍我们最近的一篇利用虚拟数据 (synthetic data) 解决联邦学习中数据异构(data heterogeneity)问题的工作《Feature Matching Data Synthesis for Non-IID Federated Learning》,收录于IEEE Transactions on Mobile Computing (CCF A) 期刊。本文将先介绍本工作的背景与动机(第一部分),接着介绍我们提出的算法HFMDS-FL(第二部分),然后介绍HFMDS-FL算法的理论与实验优势(第三部分),最后进行总结和展望(第四部分)。如果对本工作感兴趣,欢迎移步arXiv (https://arxiv.org/abs/2308.04761) 查看原文,或者与本文作者Zijian Li (zijian.li@connect.ust.hk) 直接联系。
01 研究背景与动机
在传统的机器学习方法中,通常需要将数据收集到一个服务器(server)或云中心进行模型训练。然而,这样的过程可能会导致敏感信息的泄露。为了解决这个问题,联邦学习被提出并迅速发展,它是一种具备隐私保护能力的分布式模型训练方法。联邦学习系统由一个中心服务器和多个用户组成,它允许多个用户协同训练AI模型,而无需将原始数据共享给中心服务器。用户使用私有数据进行模型训练,并上传模型更新到服务器进行模型聚合。最后,聚合后的模型会下发给用户进行下一轮的训练。这种方式既保护了数据的隐私性,又提升了模型的泛化能力。
数据异构是联邦学习一个还没解决的问题,用户之间天然存在的分布不均匀使得收敛速度和最后的准确率都会大受影响。尽管已经有很多工作被提出来解决这个问题,但是在很多场景下的效果往往是最基础的FedAvg算法表现最好 [1]。在这里,我们不禁思考,究竟怎样的算法才能很好地提高收敛速度和模型准确率。
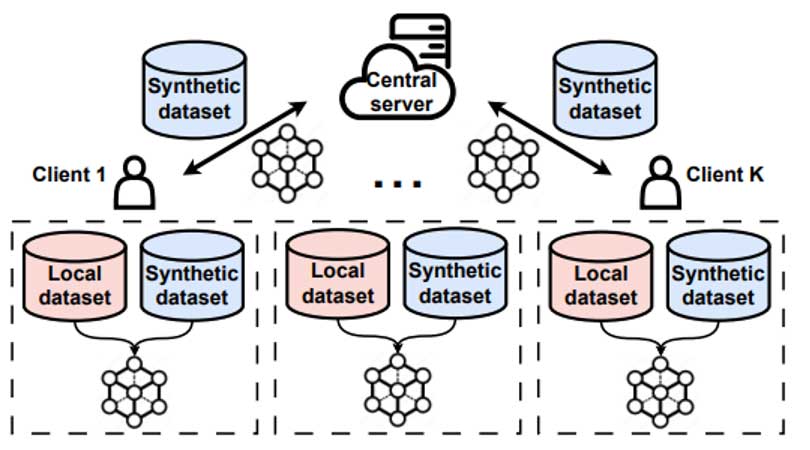
为了解决这个问题,如图1所示,本工作提出一种新型的联邦学习训练框架:利用分享虚拟数据去减少用户之间的数据异构。这种研究路线真正的关键在于如何产生虚拟数据。相比于其他的数据合成方法,比如对多个真实数据做平均 [2] 或者利用对抗生成模型(GAN)[3] 产生数据,我们使用了模型反演(model inversion)的方式去更新虚拟数据,在模型分类准确率,计算开销和隐私保护都有更好的表现。
02 算法:HFMDS-FL
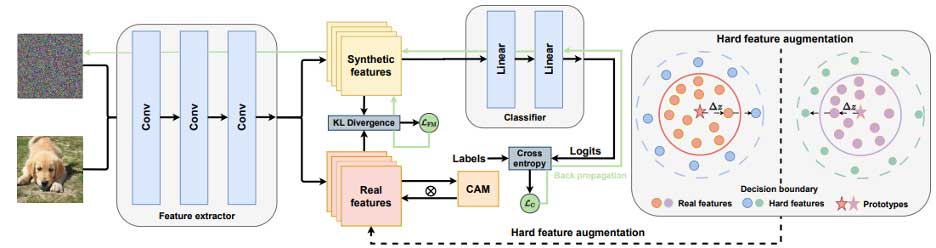
我们所提出的数据合成方法HFMDS的核心思想很简单,如图2所示,就是提取本地数据中相关的特征(relevant feature),通过让虚拟数据(synthetic data)去匹配这些特征,从而使得虚拟数据只学习到这些对任务有用的特征,同时屏蔽那些对任务无关的特征,因此在虚拟数据的有效性和隐私保护方面有一个更好的平衡。在后面两个小节,我们会详细介绍虚拟数据的”合成”方法HFMDS,然后把HFMDS应用到联邦学习中得到HFMDS-FL。
2. 1 特征匹配数据合成(feature match data synthesis)
我们首先利用模型去提取真实数据的特征,为了找出其中的相关特征,我们采用了class activate maps (CAMs),由(模型对这个类的)预测值对特征求偏导取得,相关特征的值会大于0。然后我们就让虚拟数据(synthetic data)去匹配这些特征,再利用梯度下降法去更新虚拟数据,使得虚拟数据能够产生这些相关特征。和传统利用生成模型产生数据不一样,我们利用高斯噪声初始化出虚拟数据(synthetic data),通过梯度下降直接更新虚拟数据,而不是生成模型。这种做法的优势在于数据空间(input space)相比于模型空间(model space)更小,更容易训练,训练开销也会更小。
2.2 边缘特征匹配数据合成(hard feature matching data synthesis)
因为真实数据的特征还是带有一定的隐私信息,为了更好保护隐私,我们提出用边缘特征匹配去训练虚拟数据。边缘特征指的是在分类界限(decision boundary)附近的特征,用这些特征去训练模型往往效果更好,可以增强模型泛化性。因此,我们提出把真实的特征移向分类界限,使得他们变成边缘特征。学习这些边缘特征一方面可以减少虚拟数据带有的真实数据的信息,另一方面用这些虚拟数据去训练模型也可以带来提高模型的泛化性。
最后,我们把所提出的合成方法应用到联邦学习的系统中,得到最后的方法HFMDS-FL。有一点值得注意的是,因为更好模型才能提取出更相关的特征,所以我们会随着联邦学习的过程周期性地产生虚拟数据,并用新生成的虚拟数据分享给别的用户以训练模型,直到模型最后收敛。
03 理论与实验结果
在理论方面,我们在特征对齐 (feature alignment) 和域适应(domain adaptation)方面对HFMDS-FL 解决数据异构进行分析,大家有兴趣可移步原文查看,不在此赘述。
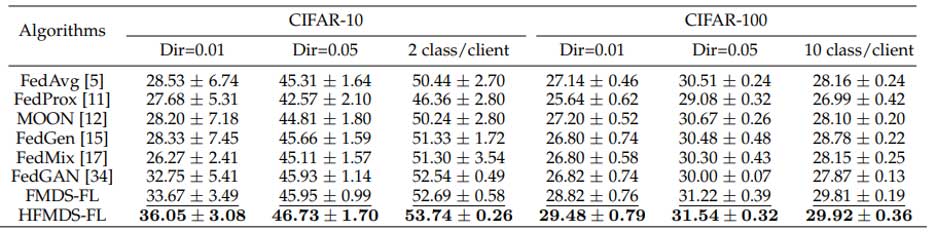
在实验方面,我们在两个图像分类数据集(CIFAR-10和CIFAR-100)上对HFMDS-FL进行验证。表1显示我们的方法在多种数据异构场景下都能比其他方法有更高的分类准确率。
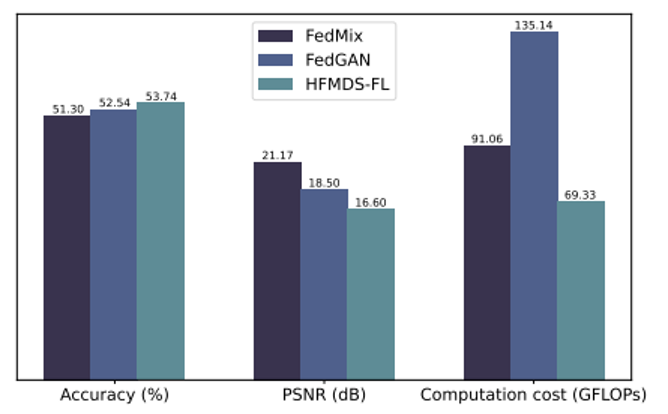
我们还研究了HFMDS-FL和其他数据合成方法在数据合成所需的计算开销和隐私保护情况。图3的结果说明我们的方法所产生的虚拟数据与真实数据的PSNR值更小,说明保护隐私更好,且所需的计算开销也比其他数据合成方法更少。
04 总结
在这个工作中,我们在联邦学习中提出一种隐私保护更好的数据合成方法。大量的结果表明,利用特征匹配去训练虚拟数据要比现有数据合成方法更适合联邦学习,且在解决数据异构问题方面也比其他方法更好,为最后实现隐私保护的分布式训练提供新的思路。
越来越多的工作表明,用户之间分享模型已经不是唯一的方式了。特别在模型异构的场景下,分享虚拟数据反而是一种更有效更直接的方式。我们的方法是每个用户优化各自的虚拟数据,最近已经有文章研究所有用户共同优化虚拟数据 [4]。分享虚拟数据能真正解决数据异构和模型异构问题,是传统联邦学习所没有的。当然,现有的数据合成方法还是会带来很大的隐私泄漏,如何更好地保护用户的隐私问题也是这个研究路线的另一个关键问题。希望本文可以给读者带来一点思考,也希望联邦学习最后可以实现落地!
05 参考文献
[1]. Q. Li, Y. Diao, Q. Chen, and B. He, “Federated learning on non-IID data silos: An experimental study,” in Proc. Int. Conf. Data Eng. (ICDE), Kuala Lumpur, Malaysia, May 2022, pp. 965–978.
[2]. T. Yoon, S. Shin, S. J. Hwang, and E. Yang, “FedMix: Approximation of mixup under mean augmented federated learning,” in Proc. Int. Conf. Learn. Representations (ICLR), May 2022
[3]. Z. Li, J. Shao, Y. Mao, J. H. Wang, and J. Zhang, “Federated learning with GAN-based data synthesis for non-IID clients,” in Proc. Int. Workshop Trustworthy Federated Learn., Mar. 2022, pp. 17–32.
[4]. Singh, Abhishek, Gauri Gupta, Ritvik Kapila, Yichuan Shi, Alex Dang, Sheshank Shankar, Mohammed Ehab, and Ramesh Raskar. “CoDream: Exchanging dreams instead of models for federated aggregation with heterogeneous models.” arXiv preprint arXiv:2402.15968 (2024).
作者:LI, Zijian
审阅:SUN, Yuchang
编辑:LIN, Zehong
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
