
本文探讨了大型语言模型(LLM)(特别是 GPT-3.5-turbo)的应用,以从 Internet 请求评论(RFC)文档中提取规范并自动理解网络协议。LLM在理解医学和法律等专业领域文本上已经有了长足应用,本文研究了它们在自动理解 RFC 方面的潜力。该团队开发了一个从RFC中提取图工件的工具– RuminMiner。然后将提取的工件与自然语言文本耦合,使用 GPT-turbo 3.5(chatGPT)提取协议自动机,并给出提取结果。
作者:SRI International
来源:Hotnets ’23
论文题目:PROSPER: Extracting Protocol Specifications Using Large Language Models
论文链接:https://conferences.sigcomm.org/hotnets/2023/papers/hotnets23_sharma.pdf
内容整理:王柯喻
重要性
网络协议是设备和系统之间通信的基础,但通常复杂多样,使得手动分析和实施耗时且容易出错。而其中一种分析理解方式即为使用 RFC 文档,所以 RFC 文档的理解需要具有高效性与准确性,同时 RFC 中的自动协议理解的应用领域也较为广泛,如攻击合成和协议安全分析,网络故障排除和代码去膨胀等等。同时这个项目也具有一定的挑战性包括:
- RFC 包含自然文本中的协议定义,这本质上是模糊的。
- 规范的 FSM 不仅基于 RFC 中包含的信息,还基于领域专家的输入。但 RFC 文本并没有详尽地涵盖规范 FSM 的所有元素。
相关工作
先前应用 NLP 技术来自动网络协议理解的工作(例如,WHYPER 和 DASE)使用语义解析从手册页、文档和源代码中提取信息。其他工作如 Veritas 和 Prospex 分析网络跟踪消息以自动生成协议自动机。前者提取概率协议状态机(PPSM),而后者使用网络消息聚类。
系统设计
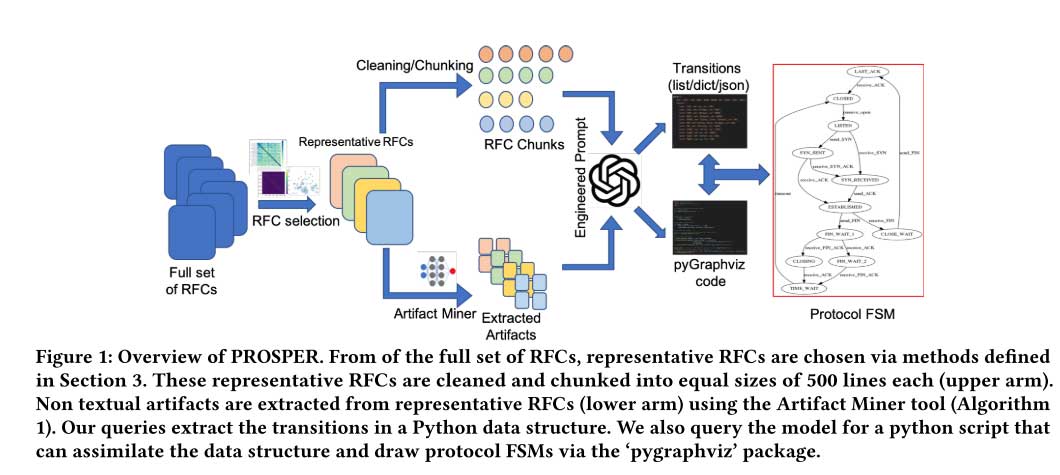
RFC Selection
在 RFC 的选择过程中,需要考虑各种重要网络协议的代表性。初步的过滤过程包括三个阶段:
- 基于 BERT 的主题模型,将 RFC 聚类到不同的主题中,从不同的主题中选择的RFC
- 每个 RFC 提供它废弃、更新或依赖于的其他 RFC,并将这些信息转换为连通组件图。从这个组件图中选择一个 RFC
- 在选择过程中优先考虑在网络领域受到高度重视或有影响力的特定 RFC
RFC Cleansing
RFC 是不遵循严格设计或模板的复杂文档;因此RFC清理过程特别具有挑战性。本文制定了以下清理RFC的一般规则:
- 所有包含作者姓名、页码、出版年份信息和跟踪信息的RFC 标头都被删除
- 删除了 RFC 的目录,避免 LLM 判断 RFC 中存在相关控制语句
- 删除参考文献和附录以及虚假的换行符和空白字符
RFC Chunking
为了遵守 GPT3.5turbo 的最大上下文长度。清理后的RFC 被分割成500行的块,这些块包含纯文本和文本图形。在所有RFC(包括上面选择的代表性 RFC)中,一行中的最大字符数为82。因此,每个块最多由41万个字符组成。
自动 RFC 协议理解
使用 LLM 从两个不同的角度来处理提取的协议信息:从协议定义中自动提取 FSM,以及理解RFC中定义的控制消息的结构,这些信息对于流量分析,入侵检测等各种网络问题都很有价值。
- 从自然语言规范中提取FSM 定义了有限状态机语法,并以类似 XML 的方式标记 RFC,并利用 LLM 破译正确的实体(FSM的状态和触发事件)。
- 从文本图中提取状态变量和数据包头描述 RFC 规范中定义了几种变量,它们构成了在发起连接时发送的数据包的一部分,或者存储在本地并根据接收到的某些信号递增。协议规范中使用的大多数变量都以文本图的形式解释。
- 使用XML Miner从文本工件中提取信息 利用开发的工件提取器(MyMiner),从 RFC 中提取文本图。其次,将提取的工件包含在工程提示符中,并提供给 LLM。

- 工程 LLM prompts
- 策略1 – 手动(贪婪):使用 DCCP 和 TCP 文档作为训练 RFC,手动构造和优化提示(prompt)。这种方法侧重于人工智能地调整和改进提示,以提高FSM提取的效果和准确性。
- 策略2 – 自动提示工程:灵感来自于 APE。这种策略使用 DCCP 和 BGP 文档作为训练RFC,自动优化提示。这可能涉及到算法或机器学习技术来自动调整提示,以实现更高效和准确的信息提取。
系统评估
本文从三个方面对该系统进行了评估:effectiveness , generalizability and coverage enrichment
- effectiveness:通过查询LLM以获得使用前一个 LLM 输出的 python 代码,从而使用 ‘pygraphviz’ 包绘制 FSM,图如下。可以避免LLM返回实体的不确定性(从a list of lists to a hashmap of lists等)。
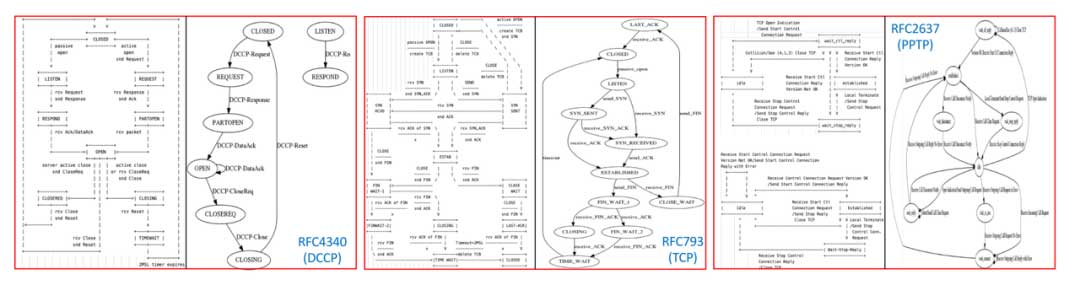
- generalizability:基础模型是在互联网的大数据集上训练的(包括技术论坛,博客,研究论文和规范文档),可以理解大多数 RFC 格式。(进一步微调可能带来更好的性能)。
- enrichment RFC是复杂的技术文档,其中与协议相关的许多信息都表示为文本工件。这些文本人工产物采用字符来表示复杂的连接形状并表达协议实体(状态、通信流、数据流图、消息结构),这会导致文本含义的模糊,但LLM具有读取图标捕捉这些转换的能力。
实验
下表显示了分别使用贪婪优化提示和 APE 工程提示的提取FSM任务的结果。
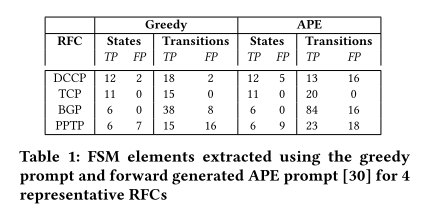
而在 DCCP 中的误判是由于拥塞控制符 CCID2 与 CCID3 被报告为系统状态。在拥塞控制协商阶段,change L/change R 会引起客户端侧的 CCID 过程的改变,因此可以解释成状态改变(CCID协商图理有)。同时可以看出于基于 APE 的提示工程在 TCP,BGP和PPTP RFC 上的性能更好,但它确实引入了更多的误报。
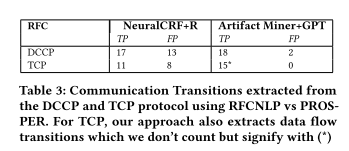
对比了 RFCNPL 与 Prosper 的结果,可以明显看出用工件提取器与LLM的结合带来的优势。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
