
3D-Speaker是通义实验室语音团队贡献的一个结合了声学、语义、视觉三维模态信息来解决说话人任务的开源项目。本项目涵盖说话人日志,说话人识别和语种识别任务,开源了多个任务的工业级模型,训练代码和推理代码。
本项目同时还开源了相应的研究数据集3D-Speaker dataset,涵盖了10000人多设备(multi-Device)、多距离(multi-Distance)和多方言(multi-Dialect)的音频数据和文本,适用于远近场、跨设备、方言等高挑战性的语音研究,供各位AI开发爱好者品鉴。
作者:3D-Speaker团队
来源:阿里语音AI
原文:https://mp.weixin.qq.com/s/6ahPgTx7qwH0kdRGHHX4gQ
结合视觉信息的说话人日志技术
在现实场景中,传统的纯音频说话人日志方案往往受限于低质量语音环境而性能表现下降。特别是在信道切换、噪声干扰的复杂声学环境中,容易产生说话人混淆和说话人转换点不清晰等错误。
相比之下,视觉信息不会受到相应的干扰,许多研究也表明视觉信息可以增强人类对语音信息的感知,提升相应的理解和识别能力。因此,在3D-Speaker项目中,我们开源了结合视觉信息的多模态说话人日志技术,通过挖掘视觉信息进一步改进说话人识别能力。
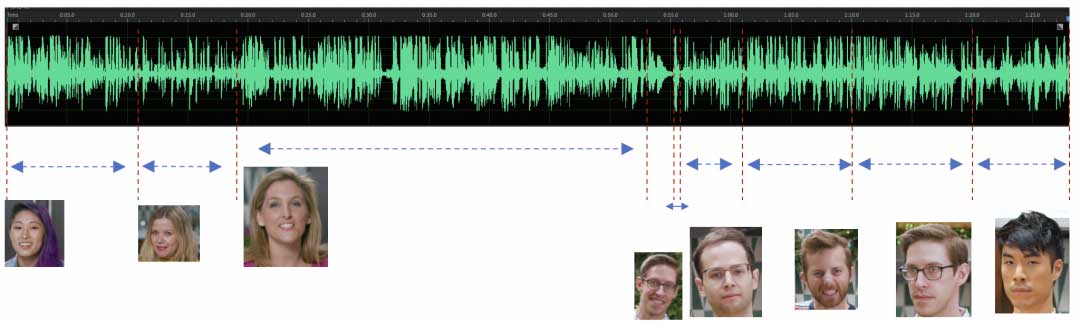
系统如下图所示,除了基于声学的识别路线,我们增加了视觉模态识别pipeline。前者仍然采用声学编码器提取包含说话人信息的声学特征。后者,考虑到人物脸部的动作行为和语音活动高度相关,并且受到声学环境的影响较小,我们重点分析和提取人物脸部的活动特征,通过视觉-音频多模态检测模块识别出当前画面中正在说话的人物信息。最后我们采用一个联合的多模态无监督聚类得到最终的识别结果。
我们在一个2-10人且包含访谈、综艺等多种类型视频数据集上进行试验,实验结果表明,结合了视觉信息的说话人日志系统在分割错误率(Diarization Error Rate)上有着显著的提升。

开源代码链接向下:
https://github.com/alibaba-damo-academy/3D-Speaker/blob/main/egs/3dspeaker/speaker-diarization/run_video.sh
执行即可下载样例视频并进行多模态说话人识别,生成包含说话人标签的结果文件。
结合语义的说话人日志技术
3D-Speaker开源了结合语义信息的说话人日志技术,将说话人日志任务从传统的根据时间戳切割音频,转化为直接对识别的文本内容进行说话人区分。
结合局部语义说话人日志系统
经典的纯声学方案的说话人日志在说话人音色相近,频繁发生切换、抢话等现象,以及声学环境复杂的情况下往往容易产生说话人混淆、说话人转换点不清晰等错误,针对这些问题我们提出了结合语义的说话人日志系统。
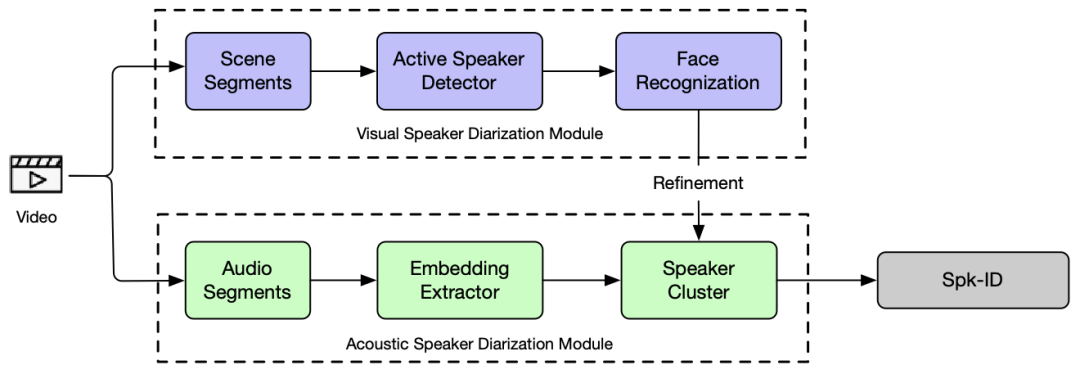
我们的系统如下图所示,区别于直接进行聚类的说话人日志系统的pipeline,我们通过引入Forced-Alignment模块来对齐文本和speaker embedding过程,并且将ASR输出的文本结果输入到语义模块中来提取说话人相关的语义信息。
关于语义部分,我们提出了两个用于提取语义中说话人信息的模块:对话预测(Dialogue Detection)和说话人转换预测(Speaker-Turn Detection),这两个模型基于Bert模型,使用大量带说话人ID的会议文本进行训练,可以用于判断多人对话的局部是否有说话人转换发生以及说话人转换发生的具体文本位置。
由于语义模块的结果也包含一些错误,尤其是在ASR系统解码出的文本上,文本错误会使得语义模型的性能有所下降,我们同时设计了一系列简单而有效的fusion策略来结合语音信息的说话人聚类结果,可以显著提升上述两个子模块的效果。
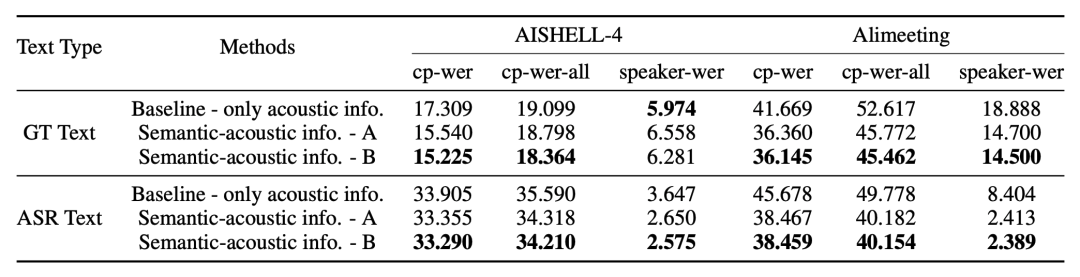
通过结合传统说话人聚类的结果和语义说话人信息,我们可以对纯音频信息的说话人日志结果进行优化。我们在AIShell-4和M2MeT(Alimeeting)数据上的结果表明,结合语义的说话人日志系统在speaker-wer和cp-wer上都有显著提升。
相关模型已经开源:
语义对话预测模型👇:
https://modelscope.cn/models/iic/speech_bert_dialogue-detetction_speaker-diarization_chinese/summary
语义说话人转换预测👇:
https://modelscope.cn/models/iic/speech_bert_semantic-spk-turn-detection-punc_speaker-diarization_chinese/summary
相关技术论文👇:
https://aclanthology.org/2023.findings-acl.884.pdf
语义说话人信息的全局扩散
上述语义说话人信息模块对说话人日志系统的主要作用在于说话人日志局部结果的修正,缺少对于全局说话人结果的优化。因此,我们提出了基于成对约束扩散方法的说话人日志系统(Joint Pairwise Constraints Propagation,JPCP),将局部说话人语义信息对全局说话人日志结果产生影响。
首先我们利用语义模块将说话人语义信息总结成两类成对约束(Pairwise Constraints):Must-Link和Cannot-Link。例如Dialogue Detection判断为非多人对话的一段时间中所有的speaker embedding都在Must-Link中,而Speaker-Turn Detection判断为转换点前后两段的speaker embeddings都在Cannot-Link中,这样我们就可以将语义信息抽象成方便使用的约束信息。
为了减少部分语义结果解码错误或者ASR解码文本错误,我们还设计了一个简单但有效的方法对Must-Link和Cannot-Link进行修正。
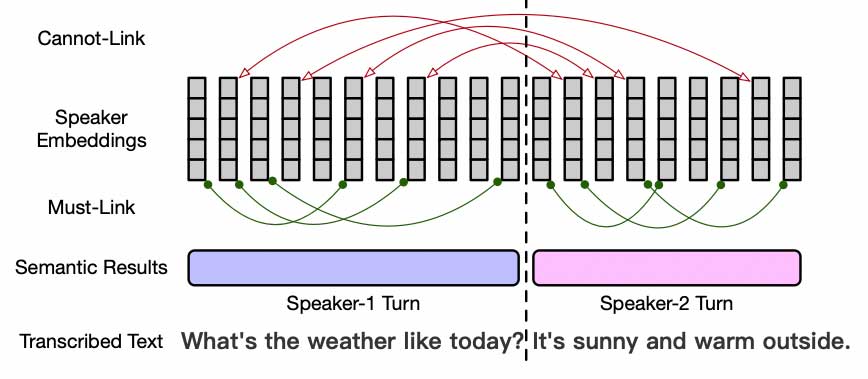
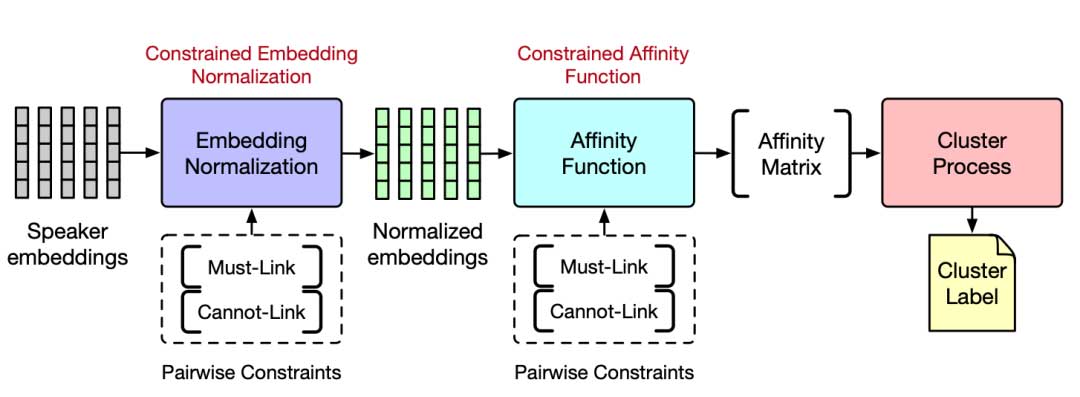
接下来将这些成对约束用于speaker embedding降维和说话人聚类过程中:
(1)利用SSDR(semi-supervised dimension reduction)策略,利用特征值优化将成对约束引入到speaker embedding降维之中,调整了其用于聚类的speaker embedding分布。
(2)引入了E2CP(exhaustive and efficient constraint propagation)方法,利用成对约束调整聚类相似度矩阵,从而改进说话人聚类的效果。
我们的实验基于AIShell-4数据集,该数据集包括人数较多的多说话人会议,输入进入语义模块的文本则来自于ASR系统的解码结果。可以看到我们提出的JPCP方案可以有效提高说话人聚类的效果,并且说话人人数预测错误也得到一定的缓解。
同时为了探索我们方案的上限,我们还在仿真的成对约束上充分探索了我们方案的上限,可以看到当constraints的质量和数量进一步提升时,最终的结果有显著的提升,并且可以更好的减少说话人日志系统说话人人数预测错误。
相关技术论文:https://arxiv.org/pdf/2309.10456.pdf
基于经典声学信息进行说话人和语种识别
3D-Speaker作为一个说话人开源项目,也包含了基于经典声学信息的说话人识别和语种识别相应的模型和算法。其中,说话人识别模块涵盖全监督说话人识别以及自监督说话人识别。
3D-Speaker提供了多种数据增强算法,多模型训练,多损失函数等内容,在各通用数据集上(3D-Speaker, VoxCeleb和CN-Celeb)实现一键式训练推理,简单高效。
多种数据增强算法包括在线WavAugment和SpecAugment增强方式,与离线增强相比,具有增加音频多样性和随机性,提高特征提取鲁棒性,减小磁盘存储等优势。
多模型训练支持各经典模型多卡并行训练,不仅包含经典模型ECAPA-TDNN, ResNet和Res2Net训练代码,还新增自研轻量级模型CAM++和短时鲁棒ERes2Net模型,提升效率的同时增强识别准确率。
多损失函数包含margin-based softmax系列损失函数,提供准确的学习率调节方案和margin变换值,也可使用large-margin-finetune提取区分性更强的说话人矢量。
说话人识别
典型的说话人识别框架一般由帧级别的特征学习层,特征聚合层,段级别表征学习层和分类层构成。通过说话人区分性的训练准则学习鲁棒性说话人特征矢量。全监督说话人识别框架在全监督说话人识别中,我们提出一种基于上下文感知的说话人识别网络(CAM++)和基于全局和局部特征融合的增强式网络(ERes2Net)。
(1) 一个基于上下文感知的说话人识别网络
在说话人识别领域中,主流的说话人识别模型大多是基于时延神经网络或者二维卷积网络,这些模型获得理想性能的同时,通常伴随着较多的参数量和计算量。因此我们提出高效的说话人识别模型CAM++。该模型主干部分采用基于密集型连接的时延网络(D-TDNN),每一层的输入均由前面所有层的输出拼接而成,这种层级特征复用可以显著提高网络的计算效率。同时,D-TDNN的每一层都嵌入了一个轻量级的上下文相关的掩蔽(Context-aware Mask,CAM)模块。
CAM模块通过全局和段级的池化操作,提取不同尺度的上下文信息,生成的mask可以去除掉特征中的无关噪声。TDNN-CAM形成了局部-段级-全局特征的统一建模,可以学习到特征中更加丰富的说话人信息。CAM++前端嵌入了一个轻量的残差二维卷积网络,可以捕获更加局部和精细的频域信息,同时还对输入特征中可能存在的说话人特定频率模式偏移具有鲁棒性。
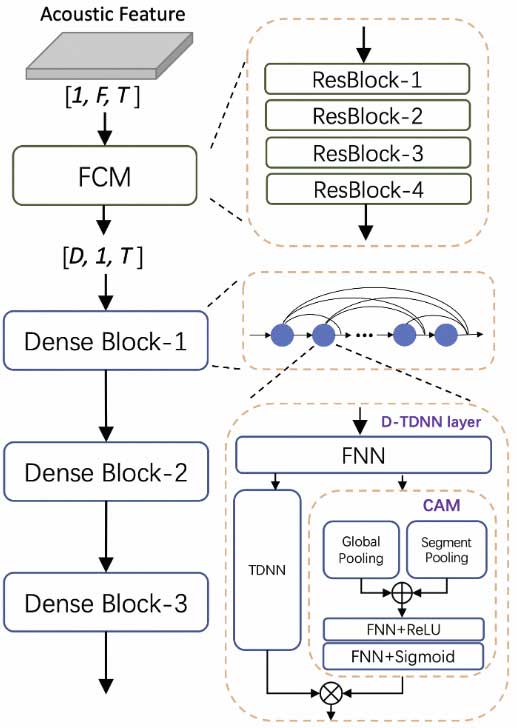
相关技术论文:https://www.isca-speech.org/archive/pdfs/interspeech_2023/wang23ha_interspeech.pdf
(2)基于全局和局部特征融合的增强式网络
有效融合多尺度特征对于提高说话人识别性能至关重要。现有的大多数方法通过简单的操作,如特征求和或拼接,并采用逐层聚合的方式获取多尺度特征。本文提出了一种新的架构,称为增强式Res2Net(ERes2Net),通过局部和全局特征融合提高说话人识别性能。
局部特征融合将一个单一残差块内的特征融合提取局部信号;全局特征融合使用不同层级输出的不同尺度声学特征聚合全局信号。为了实现有效的特征融合,ERes2Net架构中采用了注意力特征融合模块,代替了求和或串联操作。
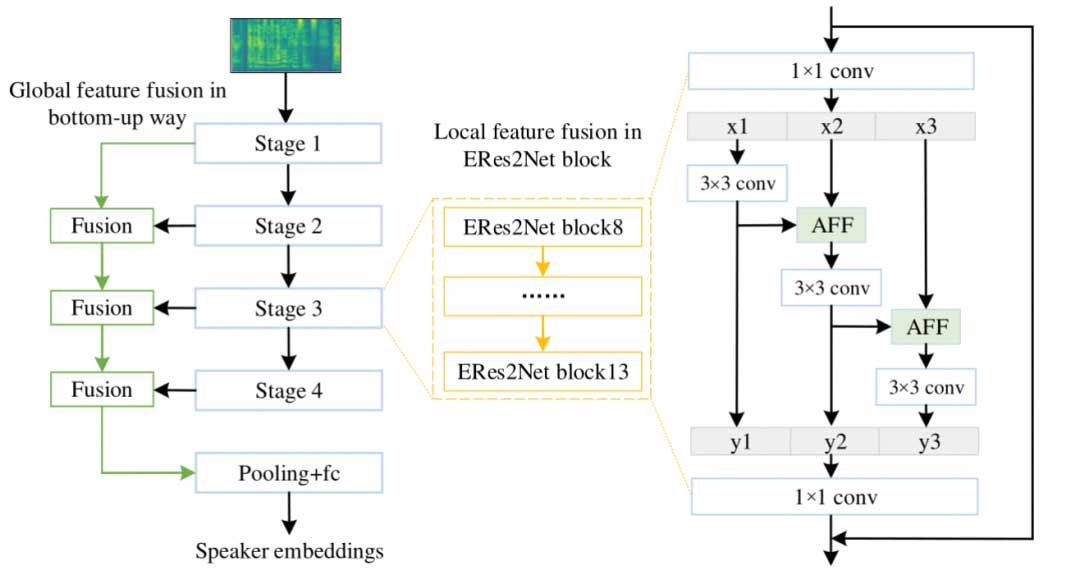
相关技术论文:https://www.isca-archive.org/interspeech_2023/chen23o_interspeech.pdf
自监督说话人识别框架
自监督学习是从一种无标签的数据中发掘潜在标签信息从而提取鲁棒性特征的方法。在当前海量无标签语音数据的条件下,训练一个鲁棒性强的说话人识别系统是一个极具挑战性的任务。基于此,我们提出了两种非对比式自监督学习框架正则化DINO(Regularized Distillation with NO labels)和自蒸馏原型网络(Self-Distillation Prototypes Network)。
(1) 正则化DINO框架的自监督说话人识别
传统的非对比式自监督学习框架存在模型坍塌的问题。基于此,我们将自监督学习框架DINO应用于说话人识别任务,并针对说话人识别任务提出多样性正则和冗余度消除正则。多样性正则提高特征多样性,冗余度正则减小特征冗余度。不同数据增强方案的优劣在该系统中得以验证。大量的实验在公开数据集VoxCeleb上开展,表现出Regularized DINO框架的优越性。
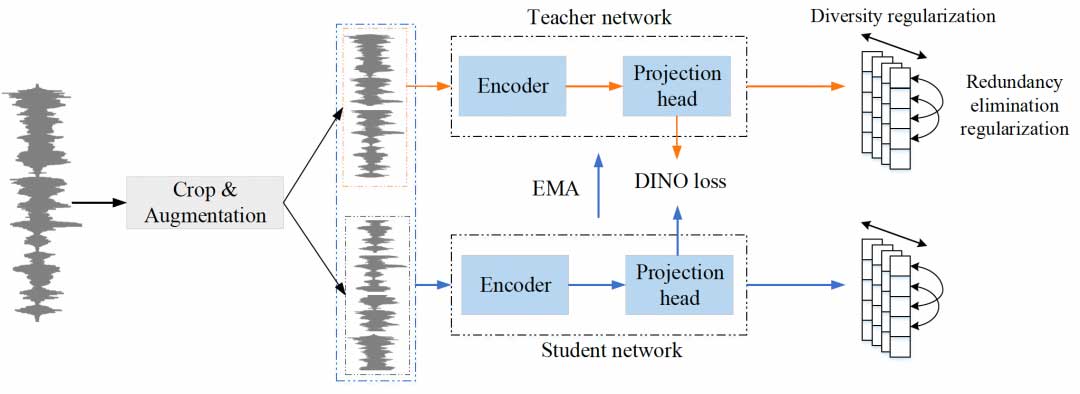
相关技术论文:https://arxiv.org/pdf/2211.04168.pdf
(2)基于自蒸馏原型网络的自监督说话人识别
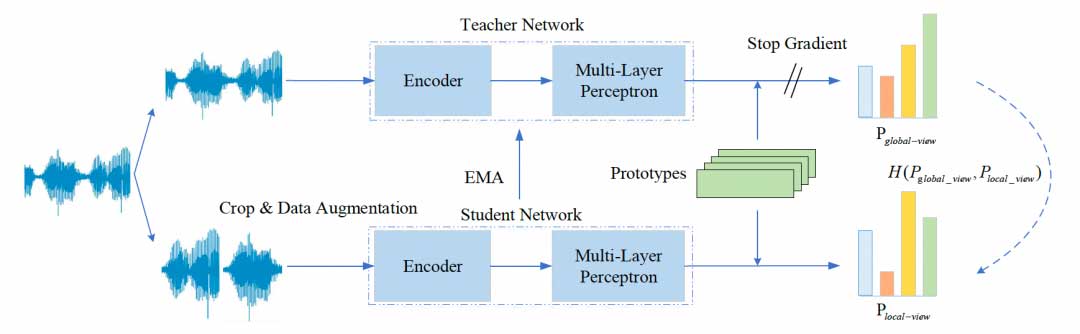
深度学习在说话人识别中广泛应用并取得优异性能,但是利用大量有标签语音数据训练神经网络提取说话人嵌入矢量需要耗费极大的人工成本,所以如何利用海量无标签数据获取优质说话人矢量成为一大研究痛点。因此我们提出一种基于自蒸馏原型网络的自监督学习说话人确认方法,提高说话人嵌入矢量的泛化性能。
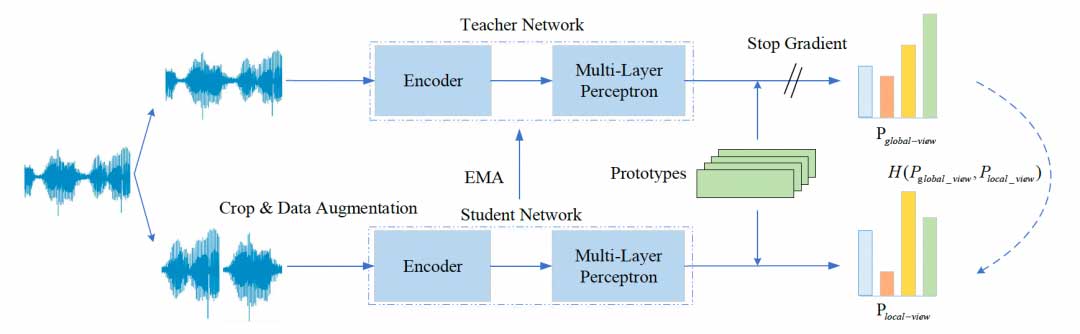
自蒸馏原型网络由教师模型和学生模型构成,如上图所示,将同一条语音切分成若干长时和短时语音,长时语音输入教师特征编码器,教师多层感知机以及原型网络,短时语音输入学生特征编码器,学生多层感知机以及原型网络,使用教师模型输出指导学生模型输出,完成自蒸馏过程。
相关技术论文:https://arxiv.org/pdf/2308.02774.pdf
语种识别
语种识别通过网络提取语音中具有语种信息的矢量进行语种判别。主要分为传统的语种识别算法与结合音素信息的语种识别算法。传统的语种识别算法与说话人识别框架相似,通过上述网络(CAM++, ERes2Net或ECAPA-TDNN)提取具有语种信息的矢量,通过训练收敛的分类器来直接输出当前语种信息。
传统语种识别算法无法准确识别背景噪声大,远场数据,短时数据以及非同源数据等情况。基于此,我们结合语音识别中提取的音素信息来进一步提升特征鲁棒性。当前训练脚本使用开源数据集3D-Speaker中各方言数据,包含普通话,粤语以及各地官话等,也可自行构造训练集识别其他语种。
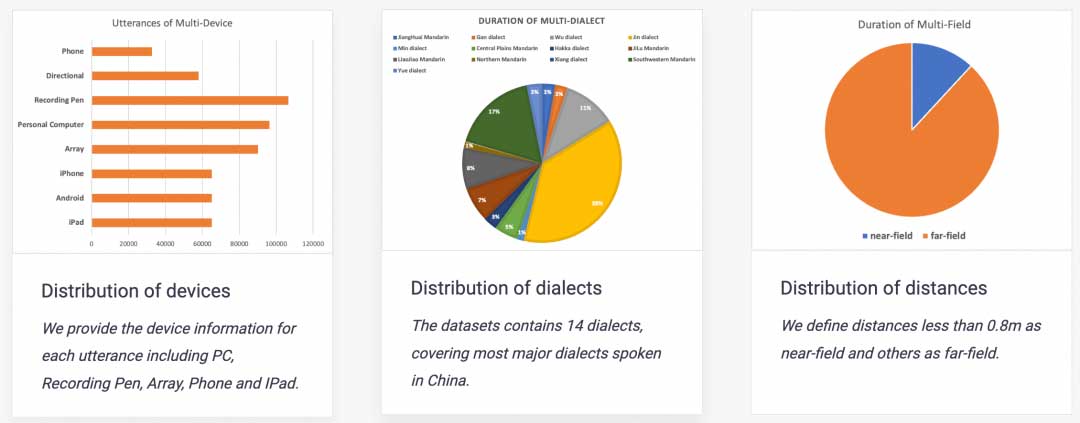
3D-Speaker数据集开源
3D-Speaker同时还开源了相应的研究数据集3D-Speaker dataset,涵盖了10000人多设备(multi-Device)、多距离(multi-Distance)和多方言(multi-Dialect)的音频数据和文本,适用于远近场、跨设备、方言等高挑战性的语音研究。
下载地址:https://3dspeaker.github.io/
数据集论文:https://arxiv.org/pdf/2306.15354.pdf
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
