
视频合成能力的开发背景
想要开发一个具有视频合成功能的应用,从原理层面和应用层面都有一定的复杂度。原理上,视频合成需要应用使用各种算法对音视频数据进行编解码,并处理各类不同音视频格式的封装;应用上,视频合成流程较长,需要对多个输入文件进行并行处理,以实现视频滤镜、剪辑、拼接等功能,使用应用场景变得复杂。
视频合成应用的代表是各类视频剪辑软件,过去主要以原生应用的形式存在。近年来随着浏览器的接口和能力的不断开放,逐渐也有了Web端视频合成能力的解决思路和方案。
本文介绍的是一种基于FFmpeg + WebAssembly开发的视频合成能力,与社区既有的方案相比,此方案通过JSON来描述视频合成过程,可提高业务侧使用的便利性和灵活性,对应更多视频合成业务场景。
2023年上半年,基于AI进行内容创作的AIGC趋势来袭。笔者所在的团队负责B站的创作、投稿等业务,也在此期间参与了相关的AIGC创作工具类项目,并负责项目中的Web前端视频合成能力的开发。
技术选型
如果需要在应用中引入音视频相关能力,目前业界常见的方案之一是使用FFmpeg。FFmpeg是知名的音视频综合处理框架,使用C语言写成,可提供音视频的录制、格式转换、编辑合成、推流等多种功能。
而为了在浏览器中能够使用FFmpeg,我们则需要WebAssembly + Emscripten这两种技术:
- WebAssembly是浏览器可以运行的一种类汇编语言,常用于浏览器端上高性能运算的场景。汇编语言一般难以手写,因此有了通过其他高级语言(C/C++, Go, Rust等)编译到WebAssembly的方案。
- Emscripten则是一个适用于C/C++项目的编译工具包,我们可以用它来将C/C++项目编译成WebAssembly,并移植到浏览器中运行。WebAssembly + Emscripten两者构筑了C语言项目在浏览器中运行的环境。再加上FFmpeg模块提供的实际的音视频处理能力,理论上我们就可以在浏览器中进行视频合成了。
编译FFmpeg至WebAssembly
想要通过Emscripten将FFmpeg编译至WebAssembly,需要使用Emscripten。Emscripten本身是一系列编译工具的合称,它仿照gcc中的编译器、链接器、汇编器等程序的分类方式,实现了处理wasm32对象文件的对应工具,例如emcc用于编译到wasm32、wasm-ld用于链接wasm32格式的对象文件等。
而对于FFmpeg这个大型项目来说,其模块主要分为以下三个部分
- libav系列库,是构成FFmpeg本身的重要组成部分。提供了用于音视频处理的大量函数,涵盖格式封装、编解码、滤镜、工具函数等多方面
- 第三方库,指的是并非FFmpeg原生提供,需要在编译FFmpeg时,通过编译配置来选择性添加的模块。包括第三方的格式、编解码、协议、硬件加速能力等
- fftools,FFmpeg提供的三个可执行程序,提供命令行参数界面,使得音视频相关功能的使用更加方便。三个可执行程序分别用于音视频合成、音视频播放、音视频文件元信息提取。因此在编译FFmpeg至WebAssembly时,我们需要按照“优先库,最终可执行程序”的顺序,首先将libav系列库和第三方库编译至wasm32对象文件,最后再编译可执行程序至wasm32对象文件,并与前面的产物链接为完整的FFmpeg WebAssembly版。
自行编译FFmpeg到WebAsssembly难度较大,我们在实际在为项目落地时,选择了社区维护的版本。目前社区内维护比较积极,功能相对全面的是ffmpeg.wasm(https://github.com/ffmpegwasm/ffmpeg.wasm)项目。该项目作者也提供了如何自行编译FFmpeg到WebAssembly的系列博文(https://itnext.io/build-ffmpeg-webassembly-version-ffmpeg-js-part-1-preparation-ed12bf4c8fac)
FFmpeg在浏览器的运行
FFmpeg本身是一个可执行命令行程序。我们可以通过为FFmpeg程序输入不同的参数,来完成各类不同的视频合成任务。例如在终端中输入以下命令,则可以将视频缩放至原来一半大小,并且只保留前5秒:
ffmpeg -i input.mp4 -vf scale=w='0.5*iw':h='0.5*ih' -t 5 output.mp4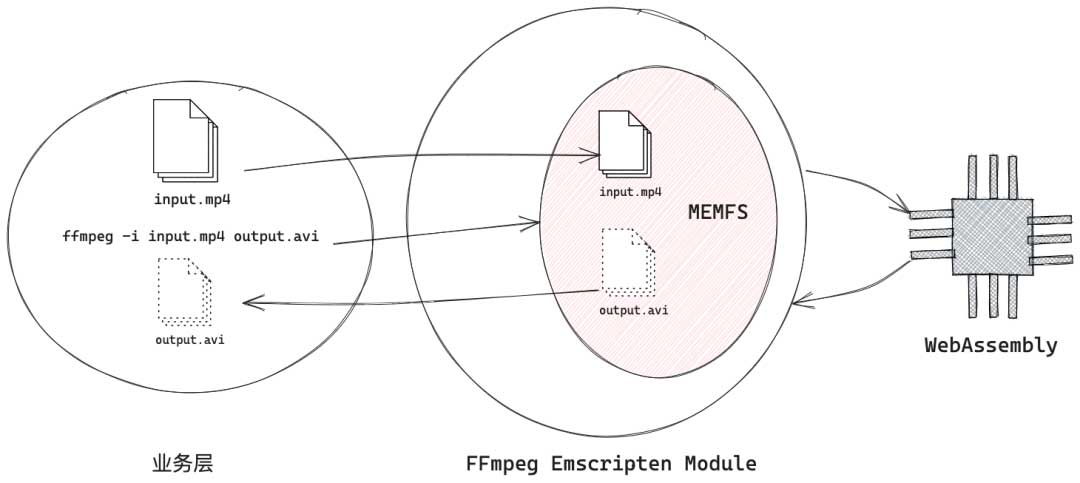
而在浏览器中,FFmpeg以及视频合成的运行机制如上所示:在业务层,我们为视频合成准备好需要的FFmpeg命令以及若干个输入文件,将其预加载到Emscripten模块的MEMFS(一种虚拟文件系统)中,并同时传递命令至Emscripten模块,最后通过Emscripten的胶水代码驱动WebAssembly进行逻辑计算。视频合成的输出视频会在MEMFS中逐步写入完成,最终可以被取回到业务层
对FFmpeg命令行界面进行封装
上面的例子中,我们为FFmpeg输入了一个视频文件,以及一串命令行参数,实现了对视频的简单缩放加截断操作。实际情况下,业务侧产生的视频合成需求可能是千变万化的,这样直接调用FFmpeg的方式,会导致业务层需要处理大量代码处理命令行字符串的构建、组合逻辑,就显得不合适宜。同时,我们在项目实践的过程中发现,由于项目需要接入 WebCodecs 和 FFmpeg 两种视频合成能力,这就需要一个中间层,从上层接收业务层表达的视频合成意图,并传递到下层的WebCodecs 或 FFmpeg 进行具体的视频合成逻辑的“翻译”和执行。
API设计

如上所示,描述一个视频合成任务,可以采用类似“基于时间轴的视频合成工程文件”的方式:在视频剪辑软件中,用户通过可视化的操作界面导入素材,向轨道上拖入素材成为片段,为每个片段设置位移、宽高、不透明度、特效等属性;同理,对于我们的项目来说,业务方自行准备素材资源,并按一定的结构搭建描述视频合成工程的对象树,然后调用中间层的方法执行合成任务。
分层设计
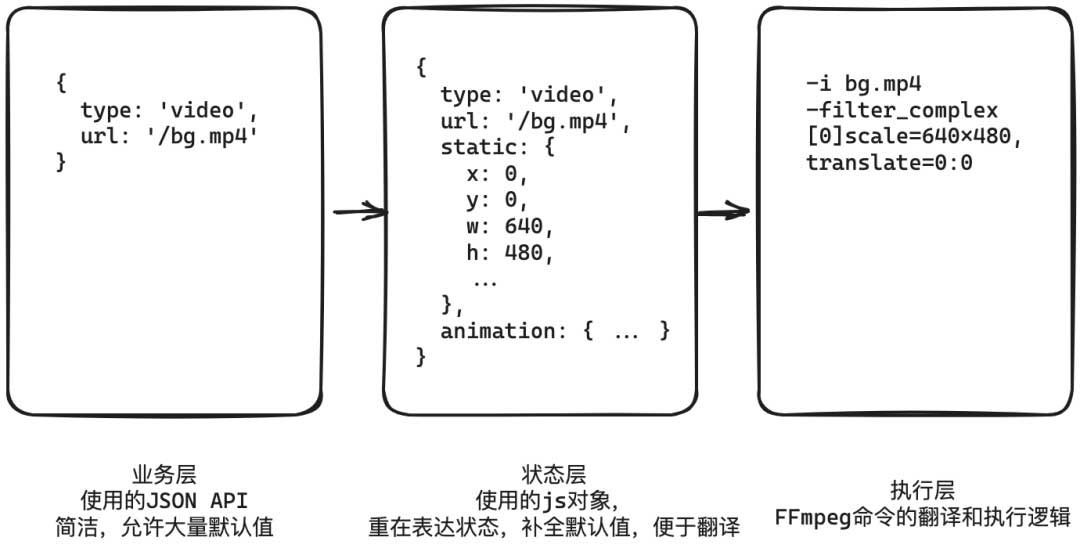
以上是我们最终形成的一个分层结构:
- 业务方代码使用一个JSON对象来描述自己的视频合成意图。为了方便业务方使用,这一层允许大量使用默认值,无需过多配置;
- 状态层是一个对象树,将视频的全局属性、片段的属性等状态补齐,方便后续的翻译;同时,这一层的各个对象都支持读写,未来可以用于可视化视频编辑器的场景等;
- 执行层负责FFmpeg命令的翻译和执行逻辑。如果状态层抽象得当,则这个执行层也可以被WebCodecs的翻译和执行模块替换
执行流程
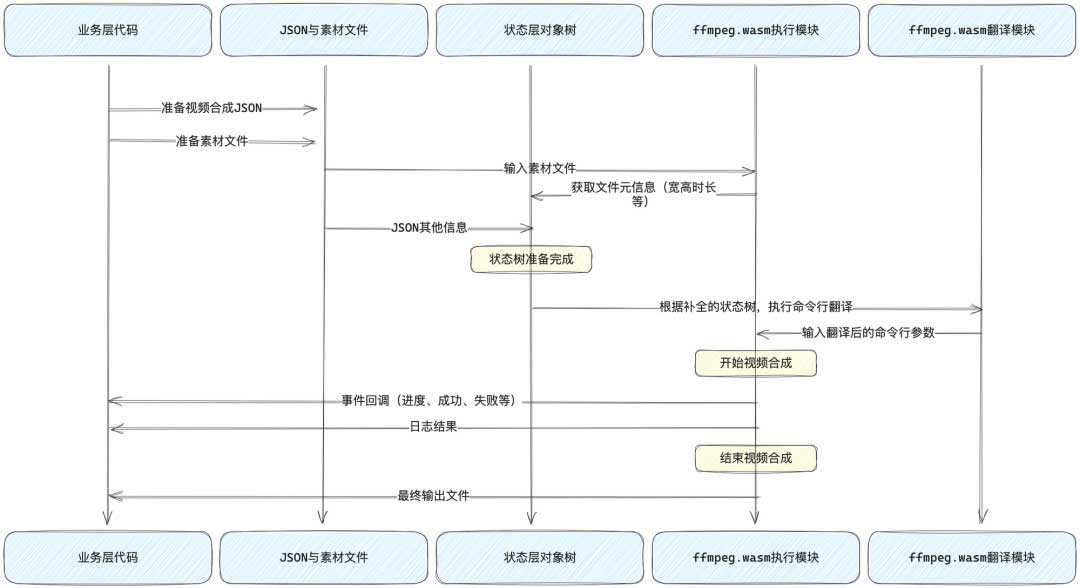
以上是我们最终实现的FFmpeg前端视频合成能力,各个模块在运行时的相互调用时序图。各个模块之间并不是简单地按顺序层层向下调用,再层层向上返回。有以下这些点值得注意
状态树,是JSON + 文件元信息综合生成的
例如,业务方想要把一个宽高未知的视频片段,放置在最终合成视频(假设为1280×720)的正中央时,我们需要将视频片段的transform.left设置为(1280 – videoWidth) / 2,transform.top 设置为 (720 – videoHeight) / 2。这里的videoWidth, videoHeight就需要通过FFmpeg读取文件元信息得到。因此我们设计的流程中,需要对所有输入的资源文件进行预加载,再生成状态树。
输出结果多样化
实践过程中我们发现,业务方在使用FFmpeg能力时,至少需要使用以下三种不同的形式的输出结果:
- 事件回调:例如业务方所需的合成进度、合成开始、合成结束等
- 合成结果的二进制文件:合成结束时异步返回
- 日志结果:例如获取文件元信息,获取音频的平均音量等操作,FFmpeg的输出都是以log的形式
因此我们为执行层的输出设计了这样的统一接口
export interface RunTaskResult {
/** 日志树结果 */
log: LogNode
/** 二进制文件结果 */
output: Uint8Array
}
function runProject(json: ProjectJson): {
/** 事件结果 */
evt: EventEmitter<RunProjectEvents, any>;
result: Promise<RunTaskResult>;
}部分代码实现
执行主流程
runProject 函数是我们对外提供的视频合成的主函数。包含了“对输入JSON进行校验,补全、预加载文件并获取文件元信息、预加载字幕相关文件、翻译FFmpeg命令、执行、emit事件”等多种逻辑。
/**
* 按照projectJson执行视频合成
* @public
* @param json - 一个视频合成工程的描述JSON
* @returns 一个evt对象,用以获取合成进度,以及异步返回的视频合成结果数据
*/
export function runProject(json: ProjectJson) {
const evt = new EventEmitter<RunProjectEvents>()
const steps = async () => {
// hack 这里需要加入一个异步,使得最早在evt上emit的事件可以被evt.on所设置的回调函数监听到
await Promise.resolve()
const parsedJson = ProjectSchema.parse(json) // 使用json schema验证并补全一些默认值
// 预加载并获取文件元信息
evt.emit('preload_all_start')
const preloadedClips = [
...await preloadAllResourceClips(parsedJson, evt),
...await preloadAllTextClips(parsedJson)
]
// 预加载字幕相关信息
const subtitleInfo = await preloadSubtitle(parsedJson, evt)
evt.emit('preload_all_end')
// 生成project对象树
const projectObj = initProject(parsedJson, preloadedClips)
// 生成ffmpeg命令
const { fsOutputPath, fsInputs, args } = parseProject(projectObj, parsedJson, preloadedClips, subtitleInfo)
if (subtitleInfo.hasSubtitle) {
fsInputs.push(subtitleInfo.srtInfo!, subtitleInfo.fontInfo!)
}
// 在ffmpeg任务队列里执行
const task: FFmpegTask = {
fsOutputPath,
fsInputs,
args
}
// 处理进度事件
task.logHandler = (log) => {
const p = getProgressFromLog(log, project.timeline.end)
if (p !== undefined) {
evt.emit('progress', p)
}
}
evt.emit('start')
// 返回执行日志,最终合成文件,事件等多种形式的结果
const res = runInQueue(task)
await res
evt.emit('end')
return res
}
return {
evt,
result: steps()
}
}翻译流程
FFmpeg命令的翻译流程,对应的是上述runProject方法中的parseProject,是在所有的上下文(视频合成描述JSON对象,状态树文件预加载后的元信息等)都齐备的情况下执行的。本身是一段很长,且下游较深的同步执行代码。这里用伪代码描述一下parseProject的过程
1. 实例化一个命令行参数操作对象ctx,此对象用于表达命令行参数的结构,可以设置有哪些输入(多个)和哪些输出(一个),并提供一些简便的方法用以操作filtergraph
2. 初始化一个视频流的空数组layers(这里指广义的视频流,只要是有图像信息的输入流(例如视频、占一定时长的图片、文字片段转成的图片),都算作视频流);初始化一个音频流的空数组audios
3. (作为最终合成的视频或音频内容的基底)在layers中加入一个颜色为project.backgroundColor, 大小为project.size,时长为无限长的纯色的视频流;在audios中加入一个无声的,时长为无限长的静音音频流
4. 对于每一个project中的片段
1. 将片段中所包含的资源的url添加到ctx的输入数组中
2. (从所有已预加载的文件元信息中)找到这个片段对应的元信息(宽高、时长等)
3. (处理片段本身的截取、宽高、旋转、不透明度、动画等的处理)基于此片段的JSON定义和预加载信息,翻译成一组作用于该片段的FFmpeg filters,并且这一组filters之间需要相互串联,filters头部连接到此片段的输入流。得到片段对应的中间流。
4. 获取到的中间流,如果是广义的视频流的,推入layers数组;如果是广义的音频流的,推入audios数组
5. 视频流layers数组做一个类似reduce的操作,按照画面中内容叠放的顺序,从最底层到最顶层,逐个合并流,得到单个视频流作为最终视频输出流。
6. 音频流audios数组进行混音,得到单个音频流作为最终输出流。
7. 调用ctx的toString方法,此方法是会将整个命令行参数结构输出为string。ctx下属的各类对象(Input, Option, FilterGraph)都有自己的toString方法,它们会依次层层toString,最终形成整体的ffmpeg命令行参数动画能力
适当的元素动画有助提高视频的画面丰富度,我们实现的视频合成能力中,也对元素动画能力进行了初步支持。
业务端如何配置动画
在视频剪辑软件中,为元素配置动画主要是基于关键帧模型,典型操作步骤如下:
- 选中画布中的一个元素后
- 在时间轴上为元素的某一属性添加若干个关键帧
- 在每个关键帧上,为该属性设置不同的值。例如将位于第1秒的关键帧的x方向位移设置为0,将位于第5秒的关键帧的x方向位移设置为100
- 软件会自动将1-5秒的动画过程补帧出来,预览播放(以及最后合成的结果中)就可以看到元素从第1秒到第5秒向下平移的效果。而在前端开发中,通过CSS的@keyframes所声明的动画,也与上述关键帧模型吻合。除此之外,在CSS动画标准中,我们还需要附加以下这些信息,才能将一段关键帧动画应用到元素上
- delay延迟(动画在元素出现后,延迟多少时间再开始播放)
- iterationCount(动画需要重复播放多少次)
- duration(在单次重复播放内,动画所占总时长)
- timingFunction(动画的补帧方式。线性方式实现简单但关键帧之间的过渡生硬,因此一般会采用“ease-in-out”等带有缓进缓出的非线性方式)。除此之外还有direction, fillMode等配置,这些并未在我们的视频合成能力中实现,故不再赘述。
在视频合成描述JSON中,我们参照了CSS动画声明进行了以下设计,来满足元素动画的配置
- 为片段了定义了 x, y, w, h, angle, opacity这六种可配置的属性(涵盖了位移、缩放、旋转、不透明度等)
- 对于需要静态配置的属性,在static字段的子字段中配置
- 对于需要动画配置的属性,在animation字段的子字段中逐个关键帧进行配置
- animation字段同时可以进行duration, delay等动画附加信息的配置
以下是元素动画配置的例子
// 视频片段bg.mp4,在画面的100,100处出现,并伴随有闪烁(不透明度从0到1再到0)的动画,动画延迟1秒,时长5秒
{
"type": "video",
"url": "/bg.mp4",
"static": {
"x": 100,
"y": 100
},
"animation": {
"properties": {
"delay": 1,
"duration": 5
},
"keyframes": {
"0": {
"opacity": 0
},
"50": {
"opacity": 1
},
"100": {
"opacity": 0
}
}
}
}
FFmpeg合成添加动画效果的原理
动画效果的本质是一定时间内,元素的某个状态逐帧连续变化。而FFmpeg的视频合成的实际操作都是由filter完成的,所以想要在FFmpeg视频合成中添加动画,则需要视频类的filter支持按视频的当前时间,逐帧动态设置filter的参数值。
以overlay filter为例,此filter可以将两个视频层叠在一起,并设置位于顶层的视频相对位置。如果无需设置动画时,我们可以将参数写成overlay=x=100:y=100表示将顶层视频放置在距离底层视频左上角100,100的位置。
需要设置动画时,我们也可以设置x, y为包含了t变量(当前时间)的表达式。例如overlay=x=t*100:y=t*100,可以用来表达顶层视频从左上到右下的位移动画,逐帧计算可知第0秒坐标为0,0,第1秒时坐标为100,100,以此类推。
像overlay=x=expr:y=expr这样的,expr的部分被称为FFmpeg的表达式,它也可以看成是以时间(以及其他一些可用的变量)作为输入,以filter的属性值作为输出的函数。表达式中除了可以使用实数、t变量、各类算术运算符之外,还可以使用很多内置函数,具体可参考FFmpeg文档中对于表达式取值的说明(https://ffmpeg.org/ffmpeg-utils.html#Expression-Evaluation)
常见动画模式的表达式总结
由于表达式的本质是函数,我们在把动画翻译成FFmpeg表达式时,可以先绘制动画的函数图像,然后再从FFmpeg表达式的可用变量、内置函数、运算符中,进行适当组合来还原函数图像。下面是一些常见的动画模式的FFmpeg表达式对应实现
动画的分段
假设对于某元素,我们设置了一个向上弹跳一次的动画,此动画有一定延迟,并且只循环一次,动画已结束后又过了一段时间,元素再消失。则此元素的y属性函数图像及其公式可能如下
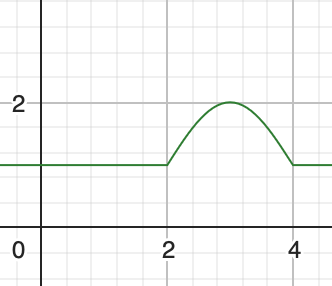
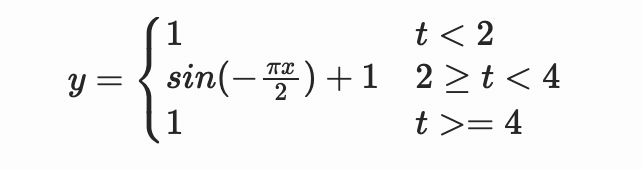
通过以上函数图像我们可知,此类函数无法通过一个单一部分表达出来。在FFmpeg表达式中,我们需要将三个子表达式,按条件组合到一个大表达式中。对于分段的函数,我们可以使用FFmpeg自带的if(x,y,z)函数(类似脚本语言中的三元表达式)来等价模拟,将条件判断/then分支/else分支 这三个子表达式 分别传入并组合到一起。对于分支有两个以上的情况,则在else分支处再嵌入新的if(x,y,z)即可。
# 实际在生成表达式时,所有的换行和空格可以省略
y=
if(
lt(t,2), # lt函数相当于<操作符
1,
if(
lt(t,4),
sin(-PI*t/2)+1,
1
)
)我们可以实现一个递归函数nestedIfElse,来将N个条件判断表达式和N+1个分支表达式组合起来,成为一个大的FFmpeg表达式,用于分段动画的场景
function nestedIfElse(branches: string[], predicates: string[]) {
// 如果只有一个逻辑分支,则返回此分支的表达式
if (branches.length === 1) {
return branches[0]
// 如果有两个逻辑分支,则只有一个条件判断表达式,使用if(x,y,z)组合在一些即可
} else if (branches.length === 2) {
const predicate = predicates[0]
const [ifBranch, elseBranch] = branches
return `if(${predicate},${ifBranch},${elseBranch})`
// 递归case
} else {
const predicate = predicates.shift()
const ifBranch = branches.shift()
const elseBranch = nestedIfElse(branches, predicates) as string
return `if(${predicate},${ifBranch},${elseBranch})`
}
}
线性和非线性补帧
补帧是将关键帧间的空白填补,并连接为动画的基本方式。被补出来的每一帧中,对应的属性值需要使用插值函数进行计算。
对于线性插值,FFmpeg自带了lerp(x,y,z)函数,表示从x开始到y结束,按z的比例(z为0到1的比值)线性插值的结果。因此我们可以结合上面的if(x,y,z)函数的分段功能,实现一个多关键帧的线性补帧动画。例如,某属性有两个关键帧,在t1时属性值为a,在t2时属性值为b,则补帧表达式为
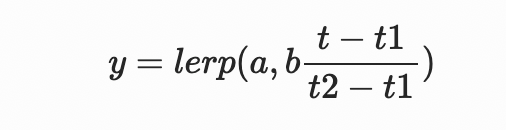
对于非线性补帧,我们可以将其理解为在上述线性补帧公式的基础上,将lerp(x,y,z)函数的z参数(进度的比例)再进行一次变换,使得动画的行进变得不均匀即可。以下公式中的t’代表了一种典型的缓慢开始和缓慢结束的缓动函数(timing function),将其代入原公式即可
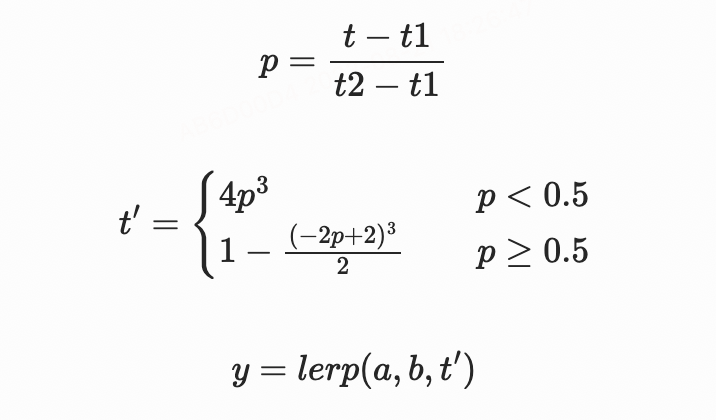
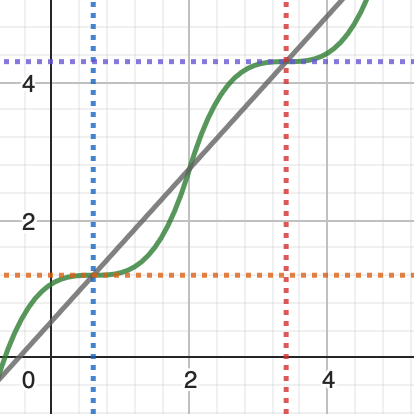
线性/非线性 补帧的函数图像)
以下是对应的代码实现
// 假设有关键帧(t1, v1)和(t2, v2),返回这两个关键帧之间的非线性补帧表达式
function easeInOut(
t1: number, v1: number,
t2: number, v2: number
) {
const t = `t-${t1})/(${t2-t1})`
const tp = `if(lt(${t},0.5),4*pow(${t},3),1-pow(-2*${t}+2,3)/2)`
return `lerp(${v1},${v2},${tp})`
}循环
如果我们需要表达一个带有循环的动画,最直接的方式是将某个时段上的映射关系,复制并平移到其他的时段上。例如,想要实现一个从画面左侧平移至右侧的动画,重复多次时,我们可能使用下面这样的函数:
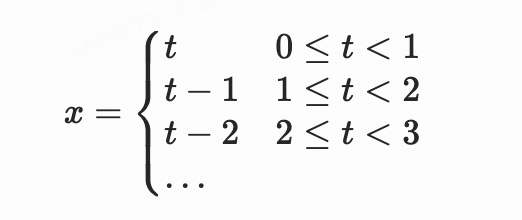
以上使用分段函数的写法的问题在于,如果循环次数过多时,函数的分支较多,产生的表达式很长,也会影响在视频合成时对表达式求值的性能。
事实上,我们可以引入FFmpeg表达式中自带的mod(x,y)函数(取余操作)来实现循环。由于取余操作常用来生成一个固定范围内的输出,例如不断重复播放的过程。上面的函数,在引入mod(x,y)后,可以简化为 x=mod(t,1)。
上述对于动画分段、循环、补帧如何实现的问题,其共通点都是如何找到其对应函数,并在FFmpeg中翻译为对应的表达式,或者对已有表达式进行组合。
据此,我们实现了KFAttr(关键帧属性,用以封装关键帧和动画全局配置等信息)和TimeExpr(以KFAttr作为入参,并翻译为FFmpeg表达式)两个类。其中,TimeExpr的整体算法大致如下:
1.将动画分成前,中,后三部分。前半部分是由于delay配置导致的,元素已出现但动画还未开始的静止部分;中间部分是动画的主体部分;后半部分是由于动画重复次数较少,元素未消失但动画已结束的静止部分
2.对于前半部分,表达式设置为等于关键帧中第一帧的值;对于后半部分,表达式设置为等于关键帧中最后一值的值
3.对于中间部分
- 3.1 将keyframes中声明的每个关键帧点(某个百分比及其对应值),结合动画的duration配置,缩放为新的关键帧点(某个时间点及其对应值)
- 3.2 根据上述关键帧,获取predicates数组(也就是动画中间部分,进入每一个分支的条件表达式,例如t<2, t<5 等)
- 3.3 根据上述关键帧,获取branches数组(也就是动画中间部分,每一个分支本身的表达式)。每一个branch声明了一个关键帧到下一个关键帧的连接,也就是补帧表达式
- 3.4 使用nestedIfElse(branches, predicates)组合出中间部分的表达式
4.再次使用nestedIfElse,将前、中、后三部分组合成最终的表达式
浏览器里视频合成的内存不足问题
在项目实践的过程中,我们发现浏览器中通过ffmpeg.wasm进行视频合成时,有一定机率出现内存不足的现象。表现为以下Emscripten的运行时报错(OOM为Out of memory的缩写)
exception thrown: RuntimeError: abort (00M). Build with -s ASSERTIONS=1 for more info.RuntimeError: abort (00M). Build with -s ASSERTIONS=1 for more info.分析后我们认为,内存不足的问题主要是由于以下这些因素导致的
- 视频合成本身是开销很大的计算过程,这是由于音视频文件往往都有着很高的压缩率,在合成时,音视频文件被解码成未压缩的数据,占用了大量内存
- 和原生环境相比,浏览器中的应用会额外受到单个标签页可使用的最大内存的限制。例如在64位系统的Chrome中,一个标签页最多可使用的内存大小为4GB
- 浏览器沙盒机制,不允许Web应用直接读写客户端本地文件。而Emscripten为了使得移植的C/C++项目仍能够拥有原来的文件读写的能力,实现了一个MEMFS的虚拟文件系统。将文件预加载到内存中,把对磁盘的读写转换为对内存的读写。这部分文件的读写也占用了一定的内存。在浏览器中运行视频合成时,还会额外受到浏览器对于单个标签页可使用的最大内存的限制(在64位的Chrome中,最多可为一个标签页分配4G内存)
为了应对以上问题,在实践中,我们采取了以下这些策略,来减少内存不足导致的合成失败率:
视频合成的严格串行执行
视频合成的过程出现了并发时,会加剧内存不足现象的产生。因此我们在runProject以及其他FFmpeg执行方法背后实现了一个统一的任务队列,确保一个任务在执行完成后再进行下一个任务,并且在下一个任务开始执行前,重启ffmpeg.wasm的运行时,实现内存垃圾回收。
时间分段,多次合成
实践中我们发现,如果一个FFmpeg命令中输入的音视频素材文件过多时,即使这些素材在时间线上都重叠(也就是某一时间点上,所有的素材视频画面都需要出现在最终画面中)的情况很少,也会大大提高内存不足的概率。
我们采取了对视频合成的结果进行时间分段的策略。根据每个片段在时间轴上的分布情况,将整个视频合成的FFmpeg任务,拆分成多个规模更小的FFmpeg任务。每个任务仅需要2-3个输入文件(常规的视频合成需求中,同屏同时播放的视频最多也在3个左右),各任务单独进行视频合成,最后再使用FFmpeg的concat功能,将视频前后相接即可。
减少重编码的场景
视频合成的重编码(解码输入文件,操作数据并再编码),会消耗大量的CPU和内存资源。而视频和音频的前后拼接操作,则无需重编码,可以在非常短的时间内完成。
对于不太复杂的视频合成场景,往往并不是画面的每一帧都需要重新编码再输出的。我们可以分析视频合成的时间轴,找出不需要重编码的时间段(指的是此时画面内容仅来自一个输入文件,并且没有缩放旋转等滤镜效果,没有其他层叠的内容的时间段)。对这些时间段,我们通过FFmpeg的流拷贝功能截取出来(通过-vcodec copy命令行参数实现)即可,这样进一步减少了CPU和内存的消耗。
在视频中添加文字的实践
在视频中添加文字是视频合成的常见需求,这类需求可以大致分为两种情况:少量的样式复杂的艺术字,大量的字幕文字。
FFmpeg自带的filters中提供了以下的文字绘制能力,包括:
- subtitles,配合srt格式的字幕文件。适合大量添加字幕,对样式定制化不高的场景
- drawtext,绘制单条文字,并进行一些简单的样式配置。如果不使用filters,由于我们是在浏览器作为上层环境使用FFmpeg的,此时也可以使用DOM API提供的一些文字转图片的技术(例如直接使用Canvas API的fillText绘制文字,或者使用SVG的foreignObject对包含文字的html文档进行图片转换等),把文字当作图片文件进行处理。
最初在支持视频合成方案的文字能力时,我们选择了后者的文字转图片技术,基本满足了业务需求。这一做法的优势在于:复用DOM的文字渲染能力,绘制效果好并且支持的文字样式丰富;并且由于转换为图片处理,可以让文字直接支持缩放、旋转、动画等许多已经在图片上实现的能力。
但正如上面提到的“为FFmpeg的命令一次性输入过多的文件容易引起OOM”的问题,文字转为图片后,视频合成时需要额外导入的图片输入文件也增加了。这也促使我们开始关注FFmpeg自带的文字渲染能力。
FFmpeg自带subtitles, drawtext等文字渲染能力,底层都使用了C语言的字体字符库(包括freetype字体光栅化,harfbuzz文字塑形,fribidi双向编码等),在每一帧编码前的filter阶段,将字符按指定的字体和样式即时绘制成位图,并与当前的framebuffer混合来实现的。这种做法会耗费更多的计算资源,但同时因为不需要缓存或文件,使用的内存更少。因此我们对于制作字幕这样需要大量添加固定样式的文字的场景,提供了相应的JSON配置,并在底层使用FFmpeg的subtitles filter进行绘制,避免了OOM的问题。
基于浏览器和FFmpeg本身的现有能力,在视频中添加文字的方案还可以有更多探索的可能。例如可以“使用SVG来声明文字的内容和样式,并在FFmpeg侧进行渲染”来实现。SVG方案的优点在于:文字的样式控制能力强;可以随意添加任意的文字的前景、背景矢量图形;与位图相比占用资源少等。后续在进行自编译的FFmpeg WebAssembly版相关调研时,会尝试支持。
后续迭代
通过 Emscripten 移植到浏览器运行的 FFmpeg,在性能上与原生FFmpeg有很大差距,大体原因在于浏览器作为中间环境,其现有的API能力不足,以及一些安全政策的限制,导致 FFmpeg 对于硬件能力的利用受限。随着浏览器能力和API的逐步演进,FFmpeg + WebAssembly 的编译、运行方式都可以与时俱进,以达到提高性能的目的。目前可以预见的一些优化点有:
- 文件IO方面,接入浏览器的OPFS(https://developer.mozilla.org/en-US/docs/Web/API/File_System_Access_API#origin_private_file_system)。这是浏览器中访问文件系统的一种新API,有较高的读写性能。未来有可能被Emscripten实现,以替换掉当前默认的MEMFS
- 并行计算方面,考虑使用WebAssembly SIMD(https://v8.dev/features/simd)。SIMD可以更充分地使用CPU进行并行计算。对于图像处理较多的编码场景(例如x264编码器),适当地使用WebAssembly的SIMD来优化代码有助于提高编码性能
- 图像处理方面,尝试使用WebGL优化。WebGL为浏览器提供了基于显卡的并行计算的能力,特别适合对视频抠像、滤镜、转场等应用场景进行加速。
作者:梁晴天,哔哩哔哩高级开发工程师
来源:哔哩哔哩技术
原文:https://mp.weixin.qq.com/s/1XmH55nqs7wavsWJNT-tSw
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
