
本文是对 ELECARD Video Compression Book 第三章的翻译。本章节的内容包括消除视频图像中的时间或空间冗余的可能方法、HEVC中图像处理的逐块基础、空间预测的四个主要步骤、正在编码的块内像素值的计算方法。
章节名:Spatial (Intra) prediction in HEVC
作者:Oleg Ponomarev
来源:https://www.elecard.com/page/spatial_intra_prediction_in_hevc
内容整理:李江川 原标题《[强基固本-视频压缩] 第三章:HEVC中的空间(帧内)预测》
引言
HEVC标准所实现的视频编码系统被分类为基于块的混合编解码器。“基于块”在这里意味着每个视频帧在编码过程中被划分为块,然后应用压缩算法。那么“混合”是什么意思呢?在很大程度上,编码过程中视频数据的压缩是通过从视频图像序列中消除冗余信息来实现的。显然,在时间上相邻的视频帧中的图像极有可能看起来彼此相似。为了消除时间冗余,在先前编码的帧中搜索与当前帧中要编码的每个块最相似的图像。一旦找到,该图像就被用作正在被编码的区域的估计(预测),然后从当前块的像素值中减去预测的像素值。在预测良好的情况下,差分(残差)信号包含的信息明显少于原始图像,这为压缩提供了保障。然而,这只是消除冗余的一种方法。HEVC提供了另一个选择,使用与当前块相同的视频帧中的像素值进行预测。这种预测被称为空间或帧内预测(intra)。因此,“混合”一词所指的是同时使用两种可能的方法来消除视频图像中的时间或空间冗余。还应当注意,帧内预测效率在很大程度上决定了整个编码系统的效率。现在让我们更详细地考虑HEVC标准提供的帧内预测的方法和算法的主要思想。
帧内预测的块划分
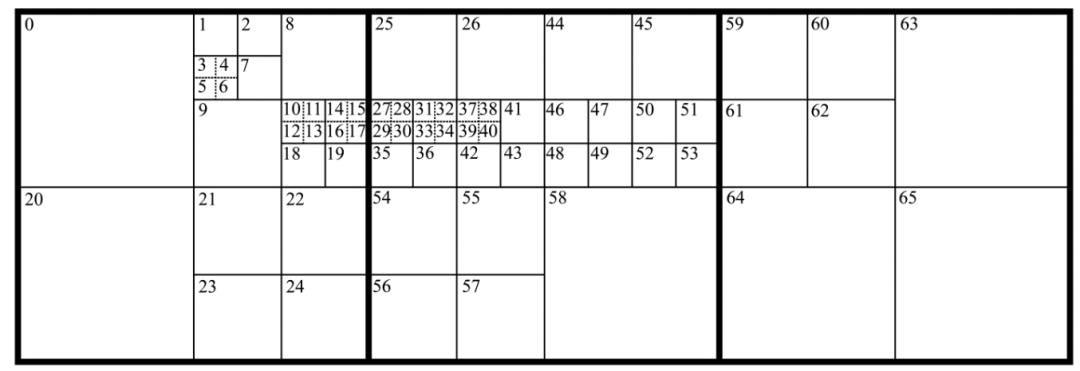
如前所述,HEVC系统中的编解码是在逐块的基础上执行的。将视频帧划分为块的过程是自适应的,即根据图像的性质进行定制。第一步,将图像从左到右、从上到下划分为相同的方形块,称为LCU(最大编码单元)。LCU大小是编码系统的参数,并且在编码开始之前指定。此大小可以取8 x 8、16 x 16、32 x 32 或 64 x 64。每个LCU可以划分为4个称为CU(编码单元)的正方形子块,每个子块也可以划分为更小的单元。因此,LCU是四叉树的根。最小CU的大小或最小四叉树深度也是编码系统的参数,可以取8 x 8、16 x 16、32 x 32 或 64 x 64 。在HEVC中对PU(预测单元)执行空间帧内预测。PU的大小与CU的大小相同,但有两个例外。首先,PU大小不能超过 32 x 32,因此一个64 x 64大小的CU包含四个32 x 32大小的PU。其次,可以将具有最小允许大小的四叉树的最低级别的CU进一步划分为大小为其一半的四个正方形PU。因此,HEVC中的一组有效PU尺寸包括以下值:4 x 4、8 x 8、16 x 16、32 x 32。将图像划分为CU和PU的示例如图1所示。较粗的实线标记LCU边界,而较细的实线界定CU子块。虚线表示在CU包含四个PU的情况下的PU边界。块内的数字显示了在编码期间访问PU的顺序。
参考像素与预测模式
在HEVC中使用相邻块的像素值来对要编码的块内部的像素值进行空间预测,这些相邻块的像素值被称为参考像素。图2显示了参考像素相对于当前编码块的位置。在该图中,当前块用字母C标记(本例中的大小为8 x 8)。字母A、B、D、E和F表示包含参考像素的块,像素位置以灰色显示。然而,并非总是所有参考像素都可用于预测。显然,图1中的CU块0、1、2和8无法访问块D、A和B中的像素,因为这些块位于视频帧的最顶部。但这并不是唯一的参考像素被认为不可用的情况。根据标准,仅允许位于已编码块中的那些参考像素用于预测。这种限制使得可以在每个块被编码之后对其进行解码,然后使用解码的像素作为参考。这确保了同一位置的像素值在编码和解码系统中有相同的预测结果。例如,考虑图1中块17的参考像素的可用性。当预测该块时,只有来自块A、D和E的像素可作为参考。在给定访问顺序下,块17周围的其余块尚未被编码,因此不能用于预测。
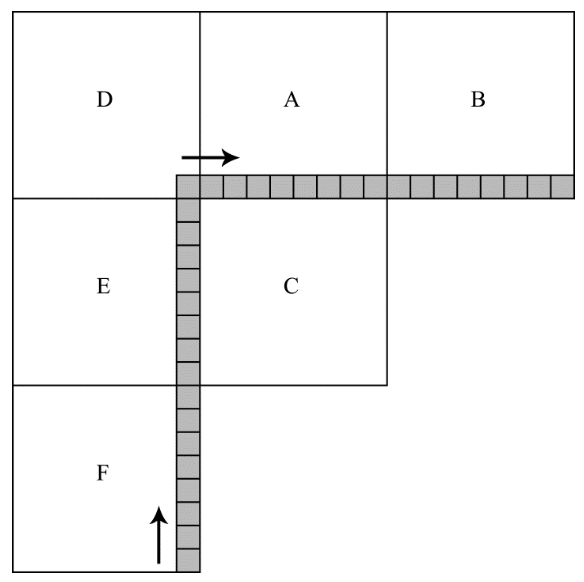
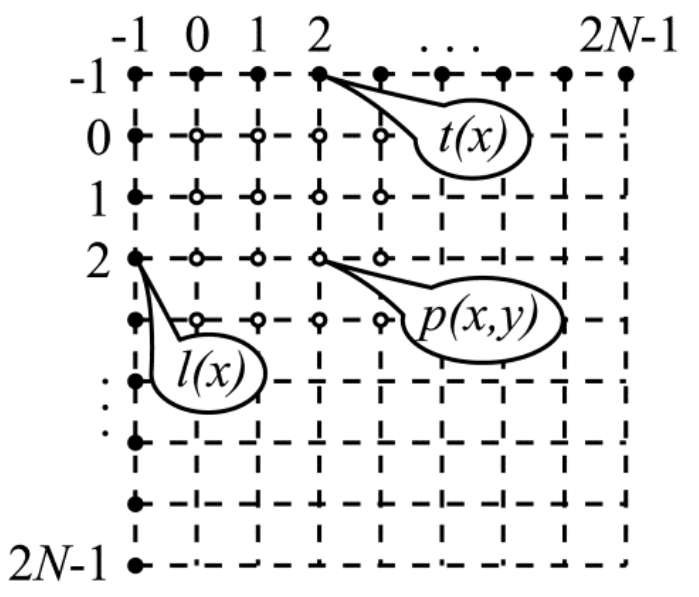
总的来说,HEVC提供了在执行空间预测时基于参考像素值计算被编码区域中的样本值的35种不同预测模式。每个模式都由一个从0到34的唯一数字标识。空间预测的过程由四个步骤组成,对于不同的预测模式和不同的块大小,可以省略其中一些步骤。第一步是为不可用的参考像素生成预测值,这一步总是在存在不可用的参考像素时执行。这一步的过程非常简单,将所有不可用像素指定为最近的可用样本的值。例如,如果块D、A和B不可用,则所有这些块的参考像素被分配块E中最上面的参考样本的值。如果块B不可用,则该块中的整行样本被分配块A中最右边的参考像素的值。最后,如果块A、B、D、E、F都不可用,则将所有参考像素设置为最大可能值的一半。例如,如果视频中的样本由8位数字表示,则所有参考像素被分配为127。预测的第二步是对参考样本序列进行滤波,首先从下到上(即从块F中的最底部样本到块D中的唯一样本),然后从左到右(即从框A中的最左边样本到框B中的最右边样本)访问它们。在滤波过程中访问样本的方向如图2中的箭头所示。滤波器类型由被编码的块的大小决定。对于某些预测模式以及当预测块的大小为 4 x 4 时,省略该步骤。第三步涉及正在编码的块内的像素值的计算。由于不同的预测模式的计算方法差异很大,这里需要更详细地介绍它们。首先需要引入一下的数学符号。N 是要编码的块的大小。p(x,y)表示预测值,其中x和y是要编码的块内的预测像素的坐标。块中左上角的待预测像素的坐标是(0,0),而右下角具有坐标(N-1,N-1)。t(x)是位于要编码的块上方(图2中的块D、A和B)的参考样本的序列,其中x可以取-1、0、1、……、2N-1。最后,是位于被编码块左侧的参考样本的序列,其中的取值范围也是-1到2N-1。以上介绍的数学符号如图3所示。
前面已经提到,每个预测模式都由一个唯一的数字来标识。接下来按照数字顺序进行介绍。
Mode.0
这种模式也被称为直流模式。在这种模式下,所有样本都被分配了和参考样本的算术平均值相同的计算结果:
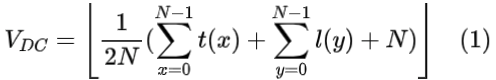
其中代表[·]取模运算。
Mode.1
这种模式也被称为平面模式。此模式中的每个值都是作为两个插值结果和的算术平均值计算得到的。和是水平和垂直方向上的线性插值结果。插值过程如图4所示。
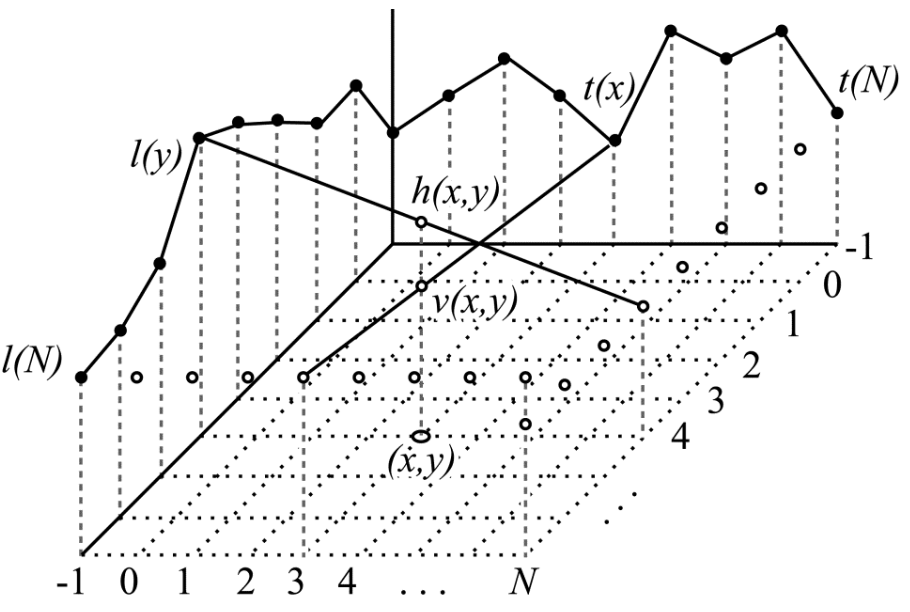
为了得到h(x,y),需要计算l(y)和位于N+1位置的t(N)的插值结果。而得到v(x,y)则需要对t(x)和l(N)进行插值,这个过程可以表述为:
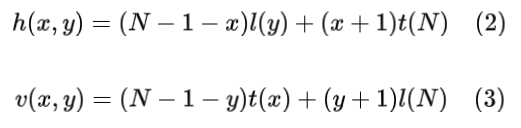
于是,h(x,y)就是两个插值结果的算数平均数:

角度模式
剩下的模式编号为2到34,称为角度模式。在这些模式中,会将需要预测的像素投影到参考样本上。如果正在预测的像素位于参考样本之间,则使用相邻参考样本的插值作为预测结果。在这组模式中有两个对称的组。对于模式2至17,参考值从下到上分布。对于模式18到34,它们是从左到右分布的。模式编号和参考样本分布方向之间的映射如图5所示。

这里以模式18到34为例进行详细介绍。对于这些模式,由预测模式编号指定并决定样本分布方向的角度φ取自垂直方向,具体示例可见图6。模式18至25的φ具有负值,而模式27至34的该角度具有正值。

使用图6作为参考,让我们考虑一下如何计算p(x,y)。很明显,在角度φ指定的方向上,点(x,y)在包含参考样本的水平轴(在图6中表示为r(x))上的投影坐标可以表示为:

还有一个关于垂直方向上的角度预测的问题没有被考虑到,这里简要讨论。对于φ为负角度(正是图6所示的情况),需要来自垂直列l(y)的参考样本对x'<0的参考样本进行预测。在这种情况下使用的垂直列l(y)的参考样本y’的位置由角度φ确定,或者更准确地说,由量cot(φ)确定:

y’是以1/256 的精度进行计算的。为了加快计算速度,同样将所有可能角度256cot(φ)的四舍五入值预先制成表格。这意味着,在对负角度进行预测之前,有必要计算y’的所有可能值,并将对应的l(y’)放入到r(x)的负半轴上。
HEVC会以类似的方式执行水平方向上的角度预测(模式2到17)。在这种情况下,角度是在水平方向进行投影的。这里,预测模式2至9对应于角度φ的正值,模式11至17对应于负值。这里就不再展开。
后处理
前面已经提到,空间预测的过程可以分为四个步骤,其中三个我们已经讨论过了。在第四步,对p(x,y)的预测值进行额外的滤波操作。该滤波阶段仅对35种预测模式中的3种使用。这些模式的编号为0(DC)、10(参考样本在该块内从左到右复制)和26(参考样本在该块内从上到下复制)。当使用这些预测模式时,在参考样本和预测值之间的块边界上可能发生像素值的急剧转变。在DC模式中,这种转换在左侧边界和顶部边界上都是可能的。因此,对沿着这两个边界的样本进行滤波。在模式10中,这种急剧转变只能发生在顶部边界上,因此只有位于顶部的那些样本才会被滤波。在模式26中,左边界是发生急剧转变的地方,并且在相位置应用滤波操作。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
