
多通道语音识别(Multi-channel ASR)的目标是识别由多个麦克风(如麦克风阵列)拾取的多通道音频,相较于标准的单通道语音识别,多通道语音识别通过有效利用多通道信号提供的空间信息,帮助提升语音识别的性能。在实际应用中,由于麦克风阵列的几何拓扑结构和数量往往不确定,因此构建一个可以适应多个数量、多种麦克风阵列几何拓扑结构的多通道语音识别模型是十分必要的。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)和理想汽车合作的论文“Automatic Channel Selection and Spatial Feature Integration for Multi-channel Speech Recognition across Various Array Topologies”被语音研究顶级国际会议ICASSP2024接收。该论文提出了一个可以适应多个数量、多种麦克风阵列几何拓扑结构的多通道语音识别模型。在给定说话人信息的CHiME-7语料库上进行了相关实验,论文提出的模型在Eval集上比基线模型的DA-WER(Diarization Attributed WER)相对降低了40.1%。现对该论文进行简要的解读。
论文题目:Automatic Channel Selection and Spatial Feature Integration for Multi-channel Speech Recognition across Various Array Topologies
合作单位:理想汽车
作者列表:穆秉甡,郭鹏程,郭大可,周盼,陈伟,谢磊
论文原文:https://arxiv.org/abs/2312.09746

背景动机
随着深度学习的不断发展,语音识别(ASR)技术取得了长足的进步,其性能也获得了大幅提升。然而ASR系统在实际远距离拾音场景中的表现远未达到满意的效果,干扰来自背景噪声、混响、说话人重叠和需要适配各种麦克风阵列几何结构拓扑等。为了应对这些挑战,CHiME系列竞赛应运而生,竞赛的宗旨是通过鼓励多通道信号处理算法的研究和创新来促进鲁棒 ASR系统的发展。
CHiME-7多设备多场景远场语音识别(DASR)的任务重点是设计一个可以泛化各种麦克风阵列几何拓扑(线性阵列、环形阵列、分布式阵列等)的ASR系统[1]。在此任务中,使用多个麦克风阵列(即分布式麦克风阵列)同时捕获来自不同空间位置的音频,从而更好地覆盖声源。然而当麦克风阵列数量增多时,由于某些麦克风阵列会靠近噪声源,导致该麦克风阵列录制的音频受到背景噪声的严重影响,若将这些音频输入到多通道ASR中,会导致ASR性能显著下降,因此将所有麦克风阵列录制的音频输入到多通道ASR中是不可取的。此外,如何有效地利用位于不同位置的麦克风阵列的空间信息仍然是一个挑战。最后,探索如何在不使用先验的阵列特定信息的情况下实现ASR系统对各种麦克风阵列几何拓扑结构的适配是一个值得研究的实际问题。
本文提出的方法
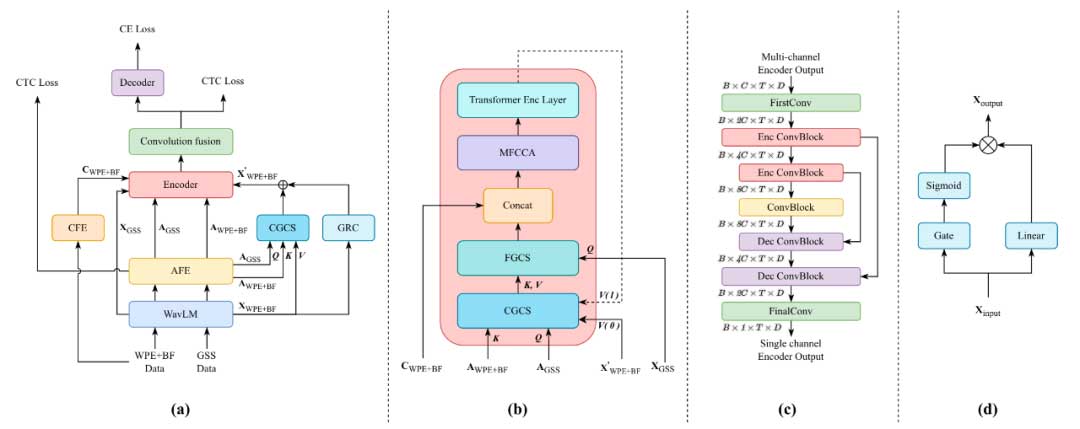
图1展示了本文提出的ASR模型方案,包含冻结WavLM作为初始音频特征提取器、通道级别音频特征提取器(AFE)、通道间空间特征提取器(CFE)、粗粒度通道选择模块(CGCS)、细粒度通道选择模块(FGCS)、门控残差连接模块(GRC)、多帧跨通道注意力机制(MFCCA)[5]、Transformer编码器、卷积融合模块和解码器。首先,我们将会介绍数据处理流程,后续依次介绍上述模块以及它们的作用。
数据处理
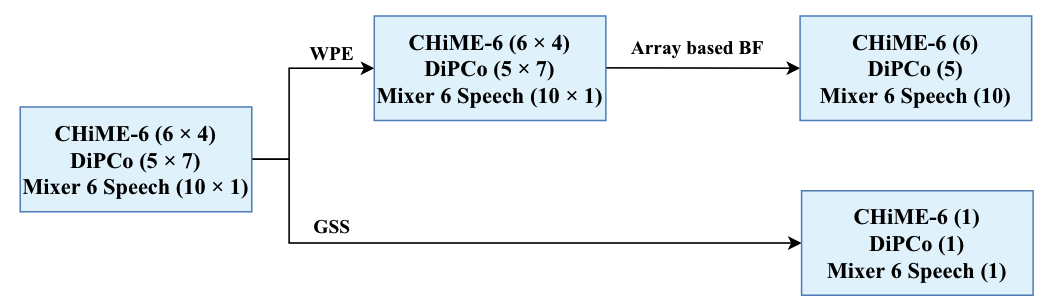
CHiME-7 DASR 任务包含三个数据集:CHiME-6[2]、DiPCo[3]和Mixer 6[4]。CHiME-6数据集录制于晚宴场景,每段音频由6个远场的线性麦克风阵列录制,每个麦克风阵列有4个通道,还提供由每个说话人佩戴的双耳麦克风录制的2通道音频作为近场音频。DiPCo数据集也是晚宴场景,每段音频由5个远场环形麦克风阵列录制,每个麦克风阵列有7个通道(6个通道加中间1个通道),还提供单通道的近场音频。Mixer 6是采访和打电话场景,每段音频由14个分布在房间不同位置的单通道麦克风录制,其中有3个麦克风录制的音频可以作为近场音频。由于每个数据集中存在大量通道,因此数据预处理势在必行。图2展示了本文的数据处理流程,首先我们使用GSS算法对所有通道的音频进行处理,得到单通道音频,这些单通道音频为自动通道选择的“基准”。然后使用加权预测误差(WPE)对每个通道的音频去混响,再使用基于阵列的BeamformIt算法将来自每个麦克风阵列的多通道音频转换为单通道音频。经过WPE和BeamformIt算法的处理,来自多个麦克风阵列录制的多通道音频被转换为一个多通道音频,其中通道的数量等于麦克风阵列的数量。这些多通道音频为自动通道选择的“候选”。
基于注意力机制的粗粒度通道选择
我们认为音频中的语言信息的丰富程度与其所包含的噪声相关。音频包含的噪声越多,对人声的干扰就越大,因此保留的语言信息就越少。粗粒度通道选择是根据多通道音频中每个通道所包含的语言信息的丰富程度来进行的,为语言信息丰富的通道赋予较高的权重,相反,为语言信息匮乏的通道赋予较低的权重。我们使用门控循环单元(GRU)[6]作为通道级别的音频特征提取器,将GRU最后的隐状态作为每个通道的特征表示。为了使GRU提取的特征与语言信息相关,我们用CTC损失函数来指导GRU。粗粒度通道选择在两个位置,第一个位置是编码器外面,第二个位置是每层编码器中。前者对输入到编码器的多通道音频特征进行预先选择,并通过图1(d)所示的门控残差连接模块与选择前的多通道音频特征相加;后者在编码器第一层的输入为刚刚预先选择过的多通道音频特征,在编码器其他层的输入为上一层编码器的输出。
基于注意力机制的细粒度通道选择
粗粒度通道选择利用通道级语言信息来选择包含丰富语言信息的通道。而细粒度通道选择专注于计算GSS音频特征和多通道音频特征之间的帧级相似度,它为与GSS音频特征的每帧相似高的多通道音频特征的帧分配更高的权重。细粒度通道选择存在于每层编码器中,以GSS音频特征和经过粗粒度通道选择的多通道音频特征为输入,输出经过细粒度通道选择后的多通道音频特征。
添加通道间空间特征的MFCCA
MFCCA对相邻帧之间的跨通道信息进行建模,同时利用通道和帧信息。由于MFCCA只接收多通道音频特征的输入,通过注意力机制隐式建模不同通道之间的空间信息,于是我们提出通过结合额外的通道间空间特征(通道间相位差,cosIPD[7])来改进 MFCCA,以提高其空间信息感知能力。具体来说,我们通过一个基于GRU的cosIPD特征提取器将多通道音频的cosIPD特征与细粒度通道选择后的结果进行拼接,输入到MFCCA中。
卷积融合
为了融合多通道输出,先前的研究主要沿通道维度平均或合并特征。为了减轻直接减少通道维度从而保留通道特定信息的不利影响,MFCCA采用直接堆叠多个卷积层来逐渐减少通道维度。然而,随着通道维度逐渐减小,特别是在多个卷积层堆叠之后,它可能会导致通道特定信息丢失。受 U-Net 架构的启发,我们改进了卷积融合模块。图1(c)为卷积融合模块的结构图。基于U-Net的卷积融合模块采用跳跃连接和多尺度特征的融合。跳跃连接允许在 U-Net 编码器和解码器之间直接传输特定于通道的信息,有助于防止在堆叠的多个卷积层中的传播过程中特定于通道的信息丢失。此外,该模块结合了不同通道维度的多通道音频特征,使其能够捕获多个尺度的通道特定信息。每个 ConvBlock 由 2-D 卷积层、Layer Normalization 和 PReLU 激活函数组成。卷积融合模块的输入通道数是固定的。因此,如果输入的通道数小于预先配置的值,则需要通过重复特征来扩展通道。
实验
基线系统
我们的基线与 CHiME-7 DASR 任务的基线相同 [1]。值得注意的是,由于提供了人工标注的说话人信息,所以省略了说话人日志部分。基线使用包络方差方法的通道选择,然后通过 GSS 进行后续处理。对于基线 ASR,我们使用由混合 CTC/Attention的Transformer结构的编码器-解码器 ASR 模型,并使用冻结的WavLM作为特征提取器。
实验设置
我们所有的系统都是通过ESPnet工具包实现的。我们按照基线ASR系统的设置来构建我们的系统,其中包括WavLM特征提取器、12 层Transformer编码器和6层Transformer解码器。MHSA和FFN层的尺寸分别设置为256和2048。我们的所有系统都在完整的CHiME-7训练集上进行了训练,训练集按照上面提到的数据处理流程进行处理,总共 276 小时。此外,我们所有的系统都是通过基于Transformer的语言模型重新评分的,该模型是在CHiME-7和LibriSpeech语料库的组合上进行训练的。在训练期间,我们冻结 WavLM 的参数。AFE 使用预训练的ASR系统进行初始化,该系统利用仅使用CTC损失进行训练的4层双向GRU编码器。提取空间特征cosIPD时,窗口长度、帧移和STFT长度分别为32ms、16ms和512。
实验结果
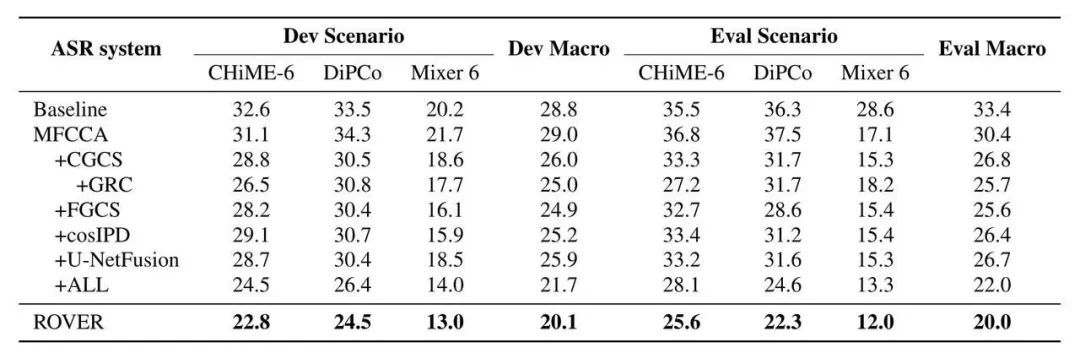
表 1 展示了我们提出的方法在 CHiME-7 Dev 和 Eval 集上的 DA-WER 结果。如表 1 所示,我们提出的所有方法均优于基线。在所有提出的方法中,细粒度通道选择带来的好处最为显著。这是因为细粒度通道选择可以从多通道音频特征中选择与GSS音频特征最相关的帧级特征。此外,粗粒度通道选择和门控残差连接的结合使用与单独使用粗粒度通道选择相比,DA-WER的降低效果更强,是仅次于细粒度通道选择的第二有效方法。这种现象可以归因于原始特征与编码器外部通过粗粒度通道选择的特征直接求和,这个过程可能会重新引入许多不利于ASR的特征,而门控残差连接通过有选择地重新引入原始特征有效地解决了这个问题。将cosIPD特征加入到MFCCA会导致 DA-WER显著降低。这可归因于MFCCA对空间特征的直接建模,明显增强了其感知空间信息的能力。使用用基于U-Net的卷积融合模块替换MFCCA中的卷积融合模块,使得ASR系统能够在压缩通道维度同时保留更多的通道特定信息。通过将所有提出的方法进行结合,我们实现了最佳的单系统性能。最后,我们利用ROVER来结合所有上述ASR系统的结果。
通道选择的可视化分析
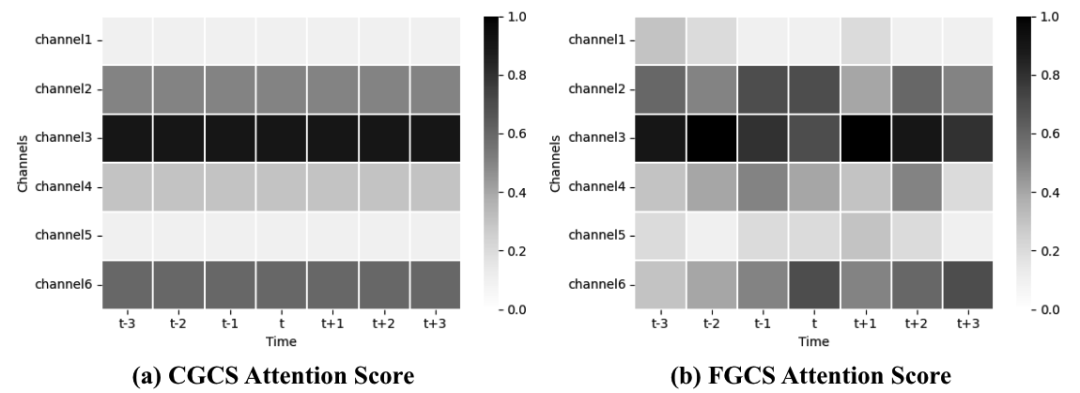
粗粒度通道选择可以根据不同通道语言信息的丰富程度分配不同的分数,具有更丰富语言信息的通道被分配更高的分数。细粒度通道选择根据多通道音频特征与GSS音频特征之间的帧级相似度为多通道音频特征的每一帧分配不同的分数,多通道音频特征中与GSS音频特征表现出较高相似度的帧被分配较高的分数。包含更丰富语言信息的通道往往具有更多与GSS音频特征高度相似的帧。如图3所示,第三通道具有最丰富的语言信息,并且具有最多数量的与GSS音频特征最相似的帧。
参考文献
[1] S. Cornell, M. Wiesner, and et al., “The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios,” arXiv preprint, 2023.
[2] S. Watanabe, M. Mandel, and et al., “CHiME-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings,” in Proc. CHiME Workshop, 2020.
[3] M. Van Segbroeck, A. Zaid, and et al., “DiPCo–Dinner Party Corpus,” arXiv preprint, 2019.
[4] L. Brandschain, D. Graff, and et al., “The Mixer 6 corpus: Resources for cross-channel and text independent speaker recognition,” in Proc. LREC, 2010.
[5] F. Yu, S. Zhang, and et al., “MFCCA: Multi-Frame CrossChannel attention for multi-speaker ASR in Multi-party meeting scenario,” in Proc. SLT. IEEE, 2023.
[6] K. Cho, B. Van Merri ̈ enboer, and et al., “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” in Proc. EMNLP, 2014.
[7] R. Gu, J. Wu, and et al., “End-to-end multi-channel speech separation,” arXiv preprint, 2019.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
