
本次分享内蒙古大学S2LAB与字节跳动、港中文(深圳)合作,关于情感对话语音合成的工作《Emotion Rendering for Conversational Speech Synthesis with Heterogeneous Graph-Based Context Modeling 》。该工作利用异构图实现情感上下文建模机制,生成符合对话语境的情感语音,实现了对话语音合成的情感渲染。该工作被AAAI 2024录用。
论文地址:
https://arxiv.org/abs/2312.11947
Demo地址:
https://walker-hyf.github.io/ECSS
代码地址:
https://github.com/walker-hyf/ECSS
0 ABSTRACT
对话语音合成(CSS)旨在,在对话环境中用合适的韵律和情感变化准确地表达话语。由于情感对话数据集的稀缺以及情感状态建模的困难性,先前的研究尚未彻底解决情感表达问题。在这篇论文当中,我们提出了一个新颖的情感对话语音合成模型,名为ECSS,其主要包括两部分:(1)为了增强情感理解,我们引入了一个基于异构图的情感上下文建模机制,将多源的对话历史作为输入建模对话上下文,并且学习上下文中的情感线索。(2)为了达到情感渲染的目的,我们采用了一个基于对比学习的情感渲染器模块推理目标语句准确的情感风格。为了解决数据稀缺问题,我们在现有对话数据集(DailyTalk)上标注了额外的情感信息,包括情感类别和强度。客观和主观评估都表明我们的模型在理解和渲染情感方面优于目前的基线模型。这些评估也证明了全面的情感标注是重要的。源码及音频样例可以在以下网址获得:
https://github.com/walker-hyf/ECSS
1 Introduction
对话语音合成(CSS)旨在在对话上下文中用合适的语言学韵律和情感韵律表达目标话语(Guo et al. 2020)。随着人机对话的发展,CSS已成为智能交互系统不可或缺的一部分(Tulshan and Dhage 2019; Zhou et al. 2020; Seaborn et al. 2021; McTear 2022),并且在虚拟助理、语音代理等领域发挥着重要作用。
不像单句话语的语音合成技术,只是根据其话语的内容来预测说话风格(Wang et al. 2017; Li et al. 2019; Ren et al.2021; Kim, Kong, and Son 2021; Liu et al. 2021a,b,c, 2022a),或者尝试从附加的参考语音中迁移风格信息(Wang et al. 2018; Li et al. 2022c; Huang et al. 2022),CSS方法通常根据两个对话者之间的对话交互历史来推断目标话语的说话风格。传统的 CSS 工作试图从各个方面获取说话风格信息,例如说话者之间和说话者内部(Li et al. 2022a)、多模态上下文依赖关系建模(Li et al. 2022a,b;Xue et al. 2023)等等。例如,Guo等人(2020)在句子级别构建粗粒度上下文编码器,并使用循环神经网络(RNN)进行对话历史编码。Li等人(2022a) 通过对话图卷积神经网络 (GCN)对对话中说话者间和说话者内的依赖关系进行建模,并使用注意力机制总结图神经网络的输出。在最近的研究中,Li 等人(2022b)提出了一种多尺度关系的图卷积网络(MRGCN)来学习对话中多模态信息之间全局和局部尺度的依赖关系。上述研究在理解对话上下文并确定合成语音中适当的说话风格做出了贡献。
然而,由于情感对话数据集的稀缺以及情感状态建模的困难性,情感理解和情感渲染在以前的CSS研究中很大程度上是缺失的。在人机对话中,建模对话语境中的情感表达,对于语音合成系统生成具有合适情感状态的语音以及改善基于语音交互中的用户体验都是至关重要的。如图1中的示例所示,图1(a)中当对话历史中的情感流为“Happy → Happy→ Surprise → Happy”时,当前话语的情感将是“Surprise”;而在图1(B)中:当情感流是“Angry → Happy →Angry → Angry”时,当前话语的情感则将是“Disgust”。
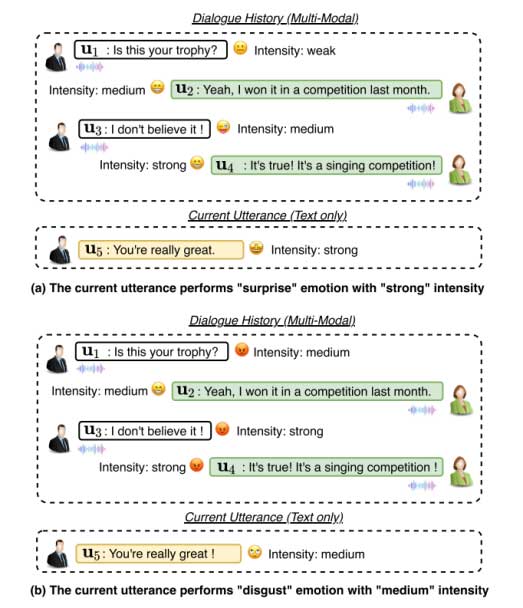
由此我们可以得出这样的结论:对话语境中的情感表达会直接影响目标话语的说话风格。此外,人类在表达自己的思想和感情时,往往会产生各种强度不同的情绪,如弱、中、强等 (Firdaus et al. 2020; Im et al. 2022; Liu et al. 2022b; Zhou et al.2023)。因此,情感强度也会对语音的表现力产生重要影响。总之,如何充分理解语境信息中的情感线索,并在此基础上在合成对话语音时进行充分的情感渲染将是本文研究的重点。最后,需要补充的是数据稀缺的问题,其主要原因是:现有的情感感知多模态数据主要针对情感识别场景,其中音频模态的语音保真度不够高,无法满足对话语音合成的数据要求。
为了解决上述挑战,我们提出了一种新颖的情感CSS模型,称为ECSS,它包括两种新颖的机制:1)为了增强对上下文话语的情感理解,提出了基于异构图的情感上下文建模模块来学习对话上下文中的情感线索。具体来说,给定对话中的多模态上下文:即被视为多源知识的文本、语音、说话者、情感和情感强度信息,用于构建异构情感对话图(ECG)的节点。然后,图编码模块采用异构图Transformer(HGT)(Hu et al. 2020)作为主干来学习上下文中复杂的情感依赖性,并学习这种复杂的依赖性对当前话语的情感表达的影响; 2)为了实现当前话语的情感渲染,我们采用基于对比学习的情感渲染模块来推断目标话语的准确情感风格。具体来说,情感渲染器将来自 ECG 的情感感知图增强节点特征作为输入,并预测适合当前话语的情感、情感强度和韵律特征。随后,这些信息与当前话语的内容和说话人表示聚合到声学解码器中,以合成最终的情感对话语音。需要注意的是,新的对比学习损失用于通过将相同类别的情感(或强度)拉得更近并将不同类别推得更远来增强各种情感和情感强度的表达。值得注意的是,为了成功实现ECSS模型,我们为最近的对话语音合成数据集DailyTalk (Lee, Park, and Kim 2023)设计了七种情感标签(快乐、悲伤、愤怒、厌恶、恐惧、惊讶、中性)和三种情感强度标签(弱、中、强),并邀请专业从业者对其进行了标注。所有带标注的数据都将开源。本文的主要贡献包括:
1. 我们提出了一种新颖的情感对话语音合成模型,称为 ECSS。据我们所知,这是第一个深入模拟情感表达的对话语音合成研究。
2. 所提出的基于异构图的情感上下文建模和情感渲染机制保证了在情感对话语音合成中准确地理解和表达情感。
3. 客观和主观实验表明,所提出的模型在情感表达方面优于所有最先进的基线模型。
2 Related works
自然语言处理(NLP)和语音处理领域都对对话的情感建模进行了研究。在 NLP 领域,Zhong、Wang 和 Miao(2019)使用上下文感知的情感图注意机制来动态利用外部常识知识进行情感识别。Goel等人(2021)提出了一种新颖的Transformer编码器,添加情感嵌入并规范化了词嵌入,从而整合了输入语句的语义和情感信息。然而,NLP 中很少考虑文本信息以外的多模态信息。
在语音处理领域,最新的对话语音合成方法使用图神经网络(GNN)模型(Li et al. 2022a,b)来理解多模态会话上下文并推断适合目标话语的说话风格。例如,对话中所有过去话语的多模态特征,包括文本信息和说话风格信息,都通过对话图卷积网络(DialogueGCN)(Ghosal et al. 2019)进行建模,以产生包含更丰富上下文知识的新表征。然而,其为CSS设计的图神经网络属于同质图,其中所有节点和边都属于相同类型(例如来自不同说话者的话语节点),这使得它们无法表示对话中自然的异构结构。尤其是对于对话中的情感表达,文本、语音、说话者、情感和情感强度等信息都可以看作异构图的节点。
我们注意到,有一些多模态对话情感识别(MMCER)工作采用了异构图网络来充分建模上下文的复杂依赖关系(Li et al. 2022d;Song et al. 2023)。与之前的研究相比,我们的异构图模块与这些作品有一些明显的区别:(1)我们将情感和情感强度节点添加到图结构中,以进行对话上下文中的动态情感线索的建模;(2)我们采用异构图Transformer作为主干来编码异构节点之间的关系,以学习构造图的高级特征表示。值得注意的是,我们的工作是首次尝试使用异构图网络对 CSS 对话中的情感理解和渲染进行建模。
3 Task Definition
一组对话可以定义为多个语句组成的序列(utt1, utt2, …, uttj, uttc),其中{utt1, utt2, …, uttj}是j轮之前的对话历史,uttc则是当前待合成的语句。情感对话语音合成任务的目标是给定uttc和对话历史{utt1, utt2, …, uttj},然后合成语音ac。对于多模态上下文,对话历史中的每个话语uttj(j∈[1, j])可以被五元组表示,简写为。注意uttc仅能被二元组表示,简写为,因为情感和情感强度需要ECSS生成。特别地,合成的语音的情感表达应该符合以多模态对话历史为特征的情感对话上下文。为此,情感CSS方法需要考虑:(1)如何挖掘对话历史中对情感表达重要的多源情感信息;(2)如何在建模对话上下文中动态情感线索的同时,对说话者内部、多模态上下文依赖性等进行建模;(3)如何在理解对话的情感线索的基础上,推断出当前话语合适的情感表达信息。
4 Methodology
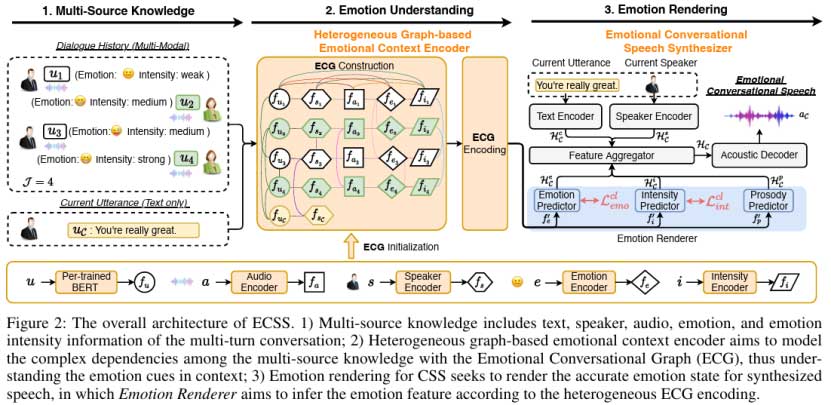
如图2所示,所提出的ECSS由三个部分组成:(1)多源知识;(2)基于异构图的情感上下文编码器;(3)情感对话语音合成器。如前面所述,多模态上下文,包括:文本、说话人、语音、情感和情感强度,包含自然的多源信息,因此可以被视为多源知识。为了增强情感理解,基于异构图的情感上下文编码器将多源知识中的每种信息视为一个节点,构建异构的情感对话图(ECG),并对所有异构节点之间的依赖关系进行建模,得到每个节点的图增强情感上下文表示。为了实现情感渲染,情感对话语音合成器利用ECG中的图增强上下文表示,对当前句子的情感表达信息进行合理预测,进而生成具有情感的对话语音。本文从三个方面对ECSS进行了详细的阐述:基于异构图的情感上下文编码器、情感对话语音合成器和对比学习训练标准。
4.1 Heterogeneous Graph-based Emotional Context Encoder
如图2的中间部分所示,基于异构图的情感上下文编码器由三部分组成:(1)ECG构造,构造具有多源上下文的异构图; (2)ECG初始化,通过不同源知识的特征表示初始化各异构节点; (3)ECG编码,感知情感线索并生成异构图节点的情感感知特征表示。
ECG构造:
与先前基于GNN的CSS方法不同,我们的目标是引入多源知识,即五种节点,包括文本fu,语音fa,说话人fs,情感fe和强度fi,并构建了一个情感对话图ECG G=(N, ε),其中N被定义为节点的集合,ε被定义为两个节点之间的边的集合。说话者、语音和文本节点试图引入基本的对话属性,而情感和强度节点可以引入动态情感特征并桥接远程话语之间的情感交互。如图2中部所示,不同形状的图代表不同种类的节点。如图2中间部分所示,不同形状的图形代表不同的节点。
的边都包括过去到未来和未来到过去的连接,以建模双向关系。
考虑到多源知识,我们创建了14种不同类型的边,如图2中间部分不同颜色的连接线所示。但是,由于空间限制,并未描绘出节点的所有边。但是,由于空间的限制,并不是所有节点的边都被描绘出来。简而言之,这14条边连接着(1)文本和其他每个节点,(2)音频和说话人节点,(3)情感和说话人,情感强度以及语音节点,(4)情感强度和说话人,语音节点。请注意,所有的边都包括过去到未来和未来到过去的连接,以建模双向关系。
ECG初始化:
为了实现有意义的异构图编码,我们需要用它们的特征表示初始化所有节点。如图2的中间和底部所示,以多轮对话为例,我们采用各种编码器来获得文本、说话者、语音、情感和情感强度节点的值fuj , fsj, faj, fej, fij(j∈[1,4])。
- 文本节点:我们采用了一个预训练的BERT模型提取语言学特征:fuj=BERT(uj)。
- 语音节点:我们采用了全局风格Token(GST)模块提取每个语句的声学特征,其包含一个参考编码器和风格Token层:faj=GST(aj)。
- 说话人,情感和情感强度节点:通过随机初始化的可训练参数矩阵faj, fej, fij 分别去学习两个说话者的身份特征,七种情感标签((快乐、悲伤、愤怒、厌恶、恐惧、惊讶、中性)特征,和三种情感强度标签(弱,中,强)特征。
需要注意,用与对话历史中的节点fuj和fsj相同的方式初始化当前话语的文本和说话人节点fuc和fsc。
ECG编码:
在初始化构建的图后,异构图编码模块用于对对话上下文中的情感线索进行编码,以获得每个节点的图增强表示。受鼓舞于异构图Transformer(HGT)((Hu et al. 2020)的前期成果,我们采用了三阶段情感HGT网络,包括:异构互注意(HMA),异构消息传递(HMP)和情感知识聚合(EKA)操作,去建模情感对话中的依赖。假设异构ECG中的一个节点是目标节点,则任何类型的任何节点都可以被视为源节点。HGT的目标是聚合来自源节点的信息,以获得目标节点的上下文表示。
首先给定一个目标节点和所有它的邻接源节点。HMA机制映射目标节点到一个查询向量,邻接源节点到一个键向量,并且计算它们的点积作为注意力(attention),其代表每个源节点对于目标节点的重要性。然后我们将h个注意力头连接在一起,得到每个节点对{目标节点, 邻接源节点}的注意力向量(即源节点和目标节点之间的边)。对于每个目标节点,我们从它的邻接节点收集所有注意力向量,并进行softmax以获得最终的注意力分数。
其次,并行计算HMP以将依赖信息从目标节点传递到邻接源节点。具体来说,对于一对节点{目标节点, 邻接源节点},HMP使用线性投影将目标节点的特征向量投影到消息向量中,其之后的一个矩阵用于合并边的依赖性。最后一步是连接所有h个消息头,以获得每个节点对的最终消息向量。
最后,EKA模块旨在聚合计算出的注意力分数和消息向量。我们使用注意力分数作为权重来平均来自所有邻接源节点的相应消息,并得到目标节点的情感增强向量。值得注意的是,所有ECG节点,包括情感和强度节点,都可以被视为源节点或目标节点,以学习其高级的上下文信息。因此,EKA操作最终将对话历史中的情感信息合并到所有ECG节点中。每个节点的图增强特征表示结合了上下文中的情感线索。
用这种方法,ECG编码模块可以获得最终的情感感知图增强特征表示。f’u, f’s, f’a, f’e, f’i分别是所有文本,说话人,语音,情感和强度节点,其可以被馈送到随后的模型中以提供情感信息。
4.2 Emotional Conversational Speech Synthesizer
如图2的右侧面板所示,情感对话语音合成器由以下四个组件组成:文本编码器,说话人编码器,情感渲染器以及声学解码器。文本和说话人编码器对当前话语的内容和说话者身份特征进行编码。情感渲染器尝试使用图增强的节点特征来预测当前话语的情感、情感强度和韵律特征。为了获得当前话语的鲁棒特征表示,特征聚合器模块为上述五个特征设置一组可训练的权重参数,然后输出最终的混淆特征。对于声学解码器,我们使用FastSpeech2(Ren et al. 2021)作为骨干,其包括差异适配器、mel解码器和声码器。差异适配器将作为输入来预测持续时间、能量和音调。mel解码器的目的是预测梅尔频谱特征。最后,使用经过良好训练的HiFi-GAN(Kong,Kim和Bae 2020)作为声码器来生成具有期望的情感风格的语音波形。
注意,为了实现情感渲染,我们的情感渲染器从ECG中提取编码的节点特征,并在执行韵律预测的同时预测当前话语的情感和情感强度特征表示。更重要的是,为了实现准确的情感类别和情感强度特征表示预测,我们提出了基于对比学习的情感和情感强度损失函数。
情感渲染器:
如图2的蓝色部分所示,情感渲染器由情感、强度和韵律预测器组成。韵律预测器采用多头注意层,从对话历史中文本节点的特征表示中推断当前话语的说话韵律信息。不使用语音节点的特征,因为我们认为语音和文本模态在ECG编码期间已经相互作用,因此文本节点已经包含音频信息。我们使用MSE损失来约束韵律预测器的训练,其中训练目标是从基于GST的韵律提取器中获得。接下来,我们将介绍情感和情感强度预测器。
情感预测器使用对话历史中的情感节点的编码特征来推断当前句子的情感表示。它包括两个卷积层,一个双向LSTM层和两个全连接层。
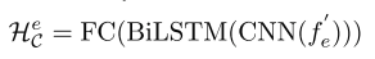
其中f’e表示ECG编码后对话历史中的所有情感类型节点。
情感强度预测器使用对话历史中的强度节点的编码特征来推断当前句子的情感强度表示。它由两个卷积层、一个双向LSTM层、两个全连接层和一个均值池层组成。
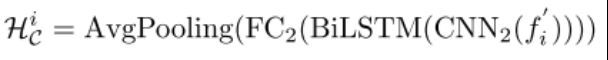
其中f’i是ECG编码后对话历史中所有情感强度节点的通用表示。
对比学习训练标准:
对于情感渲染器的情感和强度预测器,受(Khosla等人2020)的启发,我们设计了情感监督的对比学习损失,以激励情感渲染器更好地区分不同的情感类别和强度程度。具体地说,情感类别的对比学习损失和情感强度的对比学习损失具有相同的思想,即将一个批次中具有相同情感类别或强度标签的所有样例视为正样本,不同标签的样例视为负样本。对于情感特征,一个批次内有K个情感表征,被定义为:
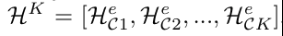
损失函数分别为:
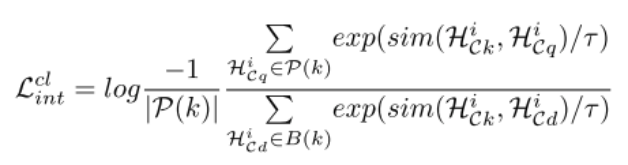
最后,总损失函数为:
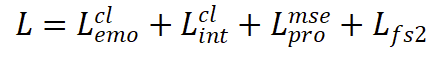
其中Lfs2是指传统FastSpeech2的声学特征损失,包括音调、能量、持续时间以及mel频谱。L^mse_pro表示韵律预测器的MSE损失。
5 Experiments and Results
数据集:
我们在最近公开的对话语音合成数据集DailyTalk(Lee,Park和Kim 2023)上验证了ECSS,该数据集由23773个音频片段组成,总共约20个小时,其中2541个对话被采样,修改和重录。所有对话都足够长,以表示每个对话的上下文。该数据集由一名男性和一名女性同时记录。所有语音样本以44.10 kHz采样,并以16位编码。我们以8:1:1的比例将数据划分为训练集、验证集和测试集。
为了获得多源知识,我们邀请了一位专业的从业者在听语音和理解话语语义的同时,对DailyTalk数据进行了细致的情感类别和强度标签标记。数据的最终分布如下,7个情感类别标签中每个的数量(快乐、悲伤、愤怒、厌恶、恐惧、惊讶、中性)分别为3871、722、226、186、74、497和18197,3种情绪强度标签中的每一种的数量(弱、中、强)分别为19,973、3,646和154。
实验设置:
在异构的基于图的情感上下文编码器中,文本节点表示fuj的维度被设置为512,并且其余类型节点表示fej, fij, fsj, faj的维度都被设置为256。对于基于多头注意力的方法,我们将头数设置为8。对于情感渲染器的情感预测器,卷积层的卷积核为3,LSTM输入维度为384,隐藏状态大小为2,核为3,LSTM输入维度为384,隐藏状态大小为256,并且在进入线性层之前使用concat拼接LSTM最后一个时间步的前向和后向输出。对于情感渲染器的强度预测器,平均池化层卷积核大小为2。对于情感渲染器的韵律预测器,查询、键、值以及输出特征的维度是512、384、384和256。声学解码器参考FastSpeech 2(Ren等人,2021)进行配置。我们使用Adam优化器,β1 = 0.9,β2 = 0.98。在文字输入方面,我们采用字形转音素(G2P)工具包,把所有文字转换成音素序列。所有语音样本都被重新采样到22.05 kHz。在25ms的窗长和10ms的移位下提取了梅尔频谱特征。该模型在Tesla V100 GPU上进行训练,批量大小为16,训练步数为600k步。在ECSS训练期间,上下文或对话历史长度被设置为10。更详细的实验设置见附录部分。
评估指标:
对于主观评价指标,我们组织了一个对话级别的平均意见分数(DMOS)(Streijl,Winkler和Hands 2016)听力测试,有30名硕士生,他们的第二语言是英语,并为我们为所有被试者提供了关于规则的专门培训。根据对话历史,他们被要求对当前话语的合成语音的自然度DMOS(N-DMOS)和情感DMOS(E-DMOS)进行评分,范围从1到5。每个被试者被分配到50个音频样本。注意,N-DMOS关注说话韵律,而E-DMOS关注当前话语的情感表达的丰富性以及它是否与上下文的情感表达相匹配。
对于客观的评价指标,我们计算预测和真实的声学特征之间的平均绝对误差(MAE),以评估合成音频的情感表现力。具体而言,我们评估的声学特征包括梅尔频谱,音调,能量,和持续时间,分别对应MAE-M,MAE-P,MAE-E和MAE-D。此外,我们进行了可视化实验,在第三方语音情感识别(SER)模型的帮助下,用来识别合成的情感会话语音的情感类别,并绘制混淆矩阵来验证ECSS。
对比研究:
为了证明我们的ECSS的有效性,我们采用了三种先进的方法,也采用了FastSpeech2作为基线系统。
1.没有情感上下文建模。第一种基线方法是没有上下文建模的普通FastSpeech 2(Ren et al. 2021),这也是最先进的非对话TTS系统的代表。
2. 基于GRU的上下文建模。这种方法只涉及文本模态,并使用基于RNN的单向GRU网络来依次对对话中的上下文依赖关系进行建模(Guo et al. 2020)。
3. 基于同构图的情感上下文建模。在基于同构图的方法(Li et al. 2022 b)中,对话中的每个过去的话语都表示为图中的一个节点。每个节点都使用相应的多模态特征进行初始化。该方法通过提取对话历史中所有节点的图增强特征来预测情感和强度信息,实现情感渲染。
主要结果:
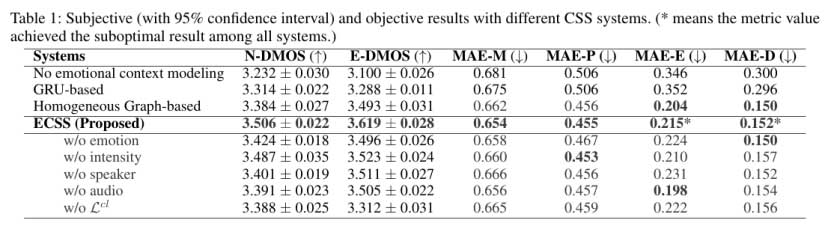
如表1的前5行所示,ECSS基本达到了最先进的性能,其在MAE-M(0.654)和MAE-P(0.455)中获得了最佳结果,在MAE-E(0.215)和MAE-D(0.152)中获得了次优结果。然而,客观的实验未必能完全反映人类的真实感受。通过观察主观结果,所提出的ECSS模型优于所有基线,N-DMOS得分为3.506,E-DMOS得分为3.619,这反映了我们的ECSS的优越性。ECSS基于异构图的上下文建模实现了情感理解,情感渲染器充分挖掘情感线索,推断出当前句子的情感表达状态,为对话语音合成提供了满意的情感渲染效果。
消融结果:
了评估ECG中的各种异构节点(包括情感、强度、说话人和音频)的个体影响以及情感渲染器的对比学习损失Lcl,我们移除这些组件以构建各种系统并进行一系列消融实验,并且主观和客观结果在表1的第6至10行中给出。我们可以发现,在异构ECG图中删除不同类型的节点带来了客观指标的性能下降,在绝大多数指标,主观DMOS分数也表现出下降。例如,去除情感节点后,MAE-M、MAE-P和MAE-E分别下降了0.004、0.012和0.009,而N-DMOS和E-DMOS分别下降了0.082和0.123。这表明我们的异构图节点可以学习对话历史中复杂的情感依赖关系,并实现完全的情感理解。此外,为了验证Lcl,我们将其替换为交叉熵损失。如表1的最后一行所示,在去除Lcl之后,所有主观和客观值都减小。这表明对比学习策略允许情感渲染器更好地区分不同的情感类别和强度。
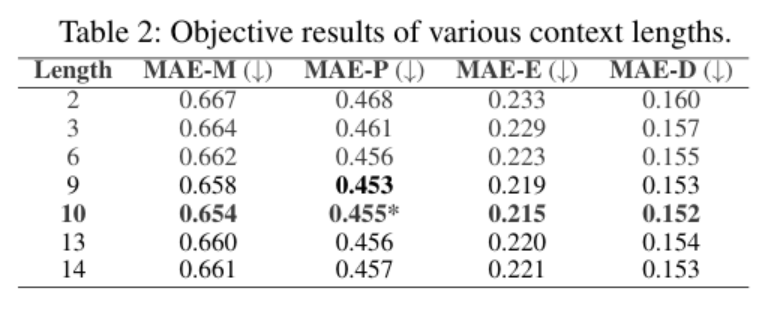
上下文长度分析:
我们还探究了不同上下文长度对于情感上下文建模的有效性。具体地,考虑到在DailyTalk中的平均对话轮数9.3,我们将对话历史的话语长度设置为从2到14,以比较客观性能。如表2所示,从总体上看,当将上下文长度从2扩大到10时,所有值都减小,并且从10到14是增大的。这表明,无论是不充分的或冗余的上下文信息都将干扰模型对上下文中情感线索的理解。
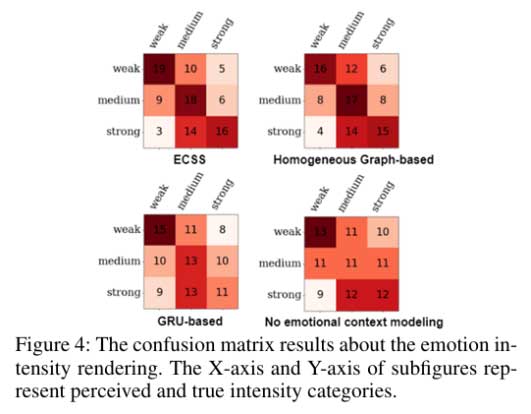
可视化研究:
为了更直观地展示合成语音的情感表达能力,我们采用了预训练的SER模型识别ECSS和所有基线合成的400个音频样本的情感类别。如图 3 所示,我们绘制了混淆矩阵来展示不同系统之间的差距。可以看出,我们的 ECSS 通过在混淆矩阵中呈现清晰的对角线而优于所有基线,证明了ECSS合成的情感会话语音具有清晰的情感表达能力。此外,我们进一步进行了可视化研究来验证情感强度渲染能力。具体来说,邀请了 5 名听众,并要求他们对 400 个音频的情绪强度标签进行评分。如图4所示,混淆矩阵表明ECSS合成的情感会话语音表现出清晰的情感强度。上述结果也进一步证明我们的ECSS因利用了异构图的上下文建模能力和对比学习的有效约束,从而在情感和情感强度渲染方面都取得了显着的性能。

6 Conclusion
为了提高 CSS 系统中的情感理解和渲染,我们提出了一种新颖的 ECSS 模型,使用具有上下文中多源知识的异构情感对话图(ECG)进行情感上下文建模,并使用具有对比学习约束的情感渲染器来进行情感上下文建模。实现准确的情感风格推断。实验结果证明了 ECSS 相对于最先进的 CSS 系统的优越性。消融研究进一步证明了异质节点在ECG图和情绪渲染器中的贡献。据我们所知,ECSS 是第一个深入模拟情感表达的对话语音合成研究。我们希望我们的工作能够成为未来情感 CSS 研究的基础。
论文翻译:内蒙古大学计算机学院2023级博士生胡一帆(导师:刘瑞研究员)
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
