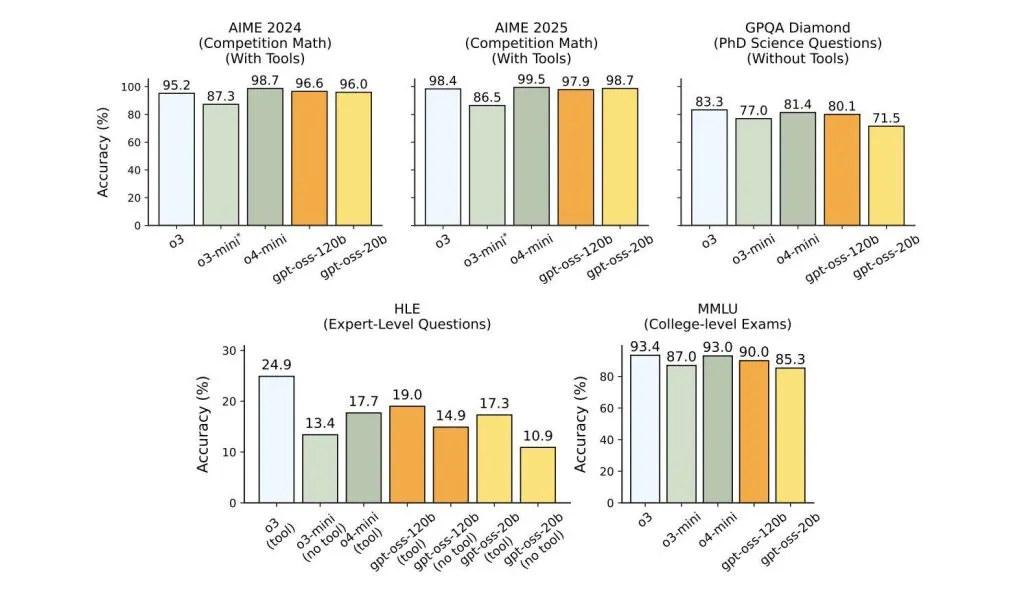
OpenAI新提出了一种功能强大的视频生成大模型,采用tansformer结构处理视频图像的时空块,支持不同长度、不同分辨率和不同长宽比的视频生成。其中最大的Sora模型支持长达一分钟的高保真视频生成。OpenAI称大规模视频生成模型是构建物理世界通用模拟器的有前景的途径。
来源:OpenAI
链接:https://openai.com/research/video-generation-models-as-world-simulators
内容整理:王寒
引言
OpenAI给出的技术报告主要包含如下两部分:
- 将所有视觉数据转变为统一表征进行大规模生成模型的训练
- 定性分析生成模型Sora的生成能力和缺陷
虽然没有介绍模型和实现细节,但该模型优越的生成能力使得这一报告值得关注。
相关工作
视频生成模型可以大致分为四种类别:
- recurrent network
- 生成对抗网络(GAN)
- 自回归Transfromer
- 扩散模型
这些已有的工作仅针对有限的视觉数据,并且生成的视频时间短、分辨率及长宽比固定。本工作验证了在原有的大小上训练模型有优势:
- 灵活的采样: Sora支持宽屏1920x1080p、竖屏1080x1920p以及在此范围内的任意长宽比的视频采样。这一特性可以让模型直接生成适配各尺寸设备的视频,同时也支持先生成小分辨率的预览结果。
- 改善构图取景:通过对比使用方形裁剪的数据和原比例数据训练得到的模型生成的视频,作者发现使用视频原长宽比可以改善构图取景。
关键技术
受到大语言模型(LLM)对大规模多模态数据的使用的启发,本文认为视觉模型也可以用相似的思路训练多模态的大模型。参考LLM的文字token,本文使用针对视觉数据的视觉patch实现大规模训练。之前的工作也佐证了patch在视觉数据表征方面的有效性。我们发现视觉patch在不同类型的视频图像数据上表现出了高扩展性和高效性。
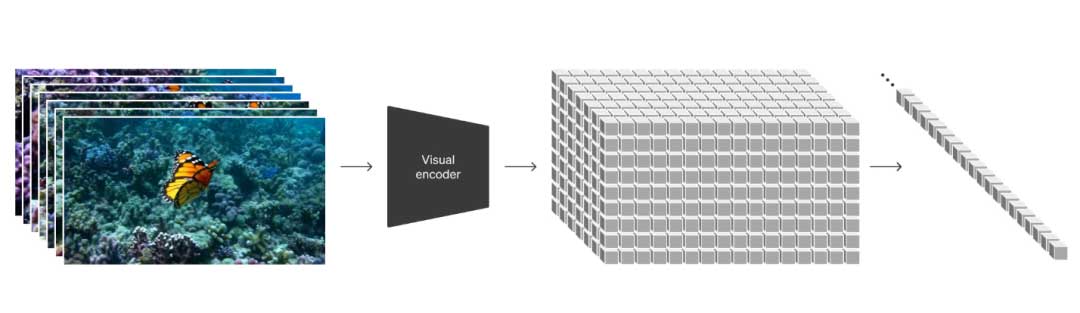
视觉数据转化为patch的整体流程如图1所示,首先通过一个编码器将视觉数据压缩到低维的隐藏空间,接下来将隐藏表征分解为时空patch。
视频压缩网络
训练了一个视觉编码器将输入的视频在时间和空间维度进行压缩,降低生成模型的复杂度,同时训练一个解码器用于将生成潜在编码对应到真实世界的视频。
时空潜在块
从压缩后的视频中提取时空块,这些块在模型中作为transformer的token。这一方法使模型可以使用视频和图像数据训练(图像可以看作单帧视频)。同时,这种基于块的表征方式支持不同时长、分辨率、长宽比的视频生成,只需在推理阶段修改分割始化块的网格大小即可。
视频生成Transformer
Sora是一个扩散模型,其原理是根据给定的有噪声的输入块和提示信息预测无噪的块。Transformer在多个领域(包括语言建模、计算机视觉和图像生成)都表现出了卓越的可扩展性,Sora模型是一个扩散transformer。作者发现扩散transformer可以高效扩展为视频模型。试验证明其计算量的提升显著提高采样质量。
语言理解
训练文本到视频模型需要大量配对的数据,本文采用了DALL·E 3技术为视频添加描述,训练一个高度描述性的字幕模型为训练集中的视频添加描述信息,高度描述性的提示提升了生成视频的文字忠实性和总体质量。
应用场景
视频编辑
Sora除了支持文生视频外还支持在已有的视频图像基础上的生成,这也使得Sora的应用场景可以扩展到视频图像编辑领域,例如生成完美循环的视频、让图片动起来、视频前后时间延伸等。
SDEdit等编辑方法也可以应用到Sora模型中实现视频编辑。此外Sora还支持将两个差别较大的视频无缝衔接。
图片生成
Sora支持最高分辨率2048×2048的图片生成(看作单帧视频)。

模拟能力
3D连续
在训练过程中作者发现,Sora习得了一些新的模拟功能,可以生成运动机位的视频,在镜头移动、旋转过程中物体保持3D特性的连续。
长短程依赖和物体保持
Sora经常(不是每次)能很好的处理长短程依赖问题,在一个视频中保持物体的连续性,即使是该物体曾经短暂离开画面的情况下也能保持前后一致,并且对一个物体的多个角度维持其外表不变。
与真实世界交互
Sora可以用简单的方式模拟动作对事物状态的影响,例如画家笔下的画面不会消失,人吃汉堡会在汉堡上留下咬痕。
模拟数字场景
Sora能模拟视频游戏中的画面,得到符合游戏场景的高保真画面。
多样化的应用场景表明,大视频模型可以通过大规模训练来实现物理世界和数字世界以及场景中的人、动物和物体实现模拟。
讨论
Sora对一些场景的物理交互模拟会出现失败现象,例如碎玻璃;此外还会出现一些不自然的状态,前面提到的食物咬痕问题并不是每次都能留下合理的痕迹;在长视频中不连续现象或物体自己出现也有发生。更多应用案例和失败案例在OpenAI网站上呈现:https://openai.com/research/video-generation-models-as-world-simulators
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。