
语音增强 (Speech Enhancement) 旨在从噪声和混响等多种干扰中恢复并提升语音的质量及可懂度,以提升人耳听感和语音识别率。在深度学习的推动下,基于神经网络的语音增强技术取得了巨大的进展,在诸多数据集上都取得了卓越的性能。近期以来,语言模型(Language Model, LM)以其强大的建模能力引来学界和工业界的高度关注,并在语音合成、语音识别等领域逐步应用。与此同时,如何将语言模型与语音增强任务结合起来,成为新的研究方向。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)和马上消费合作论文 “SELM: Speech Enhancement Using Discrete Tokens and Language Models” 被语音研究顶级会议 ICASSP 2024 接收。该论文提出了一种语音增强的新范式,不同于以往基于 STFT 谱等连续特征,该工作通过集成离散表征来利用语言模型进行语音增强。SELM 包含编码、建模和解码三个阶段。实验结果表明,SELM在客观指标上与当下最先进模型取得了可比性能,同时在主观听感上效果更佳。现对该论文进行简要解读和分享。
论文题目:SELM: Speech Enhancement Using Discrete Tokens and Language Models
合作单位:马上消费
作者列表:王子谦,朱新发,张子晗,吕元俊,蒋宁,赵国庆,谢磊
论文网址:https://arxiv.org/abs/2312.09747
样例网址:https://honee-w.github.io/SELM/


背景动机
近年来,基于深度学习的语音增强技术已经取得了巨大的成功。根据从带噪语音预测干净语音的范式,可以将这些方法简单分为判别式和生成式两大类。判别式模型旨在最小化带噪语音和干净语音之间的差距,生成式模型则通过学习干净语音的数据分布作为先验来进行语音增强。两种方式的共同点都是在基于 STFT 谱等连续特征的基础上进行处理。
近期,通过离散表征来利用语言模型的方法在多种语音生成式任务上都取得了巨大进步,包括语音合成、续写等。鉴于语音增强与语音生成任务之间内在的相似性,如何将语言模型应用于语音前端处理成为新的研究方向。此外,语言模型一般是基于离散表征进行建模的,如何在离散化时更好保留声学、语义和说话人信息等也需要深入探索。
针对以上问题,本文提出了 SELM — Speech Enhancement via Langauge Modeling,一种基于离散表征和语言模型的语音增强方案。在实验室近期多任务大模型Vec-Tok Speech[11] 的启发下,SELM的框架包括三个阶段:编码、建模和解码。我们使用预训练的自监督学习(SSL)模型和 K-Means 聚类将连续的波形信号转换为离散表征。在此之后,语言模型建模隐含在离散表征中的上下文信息。最后,通过将聚类中心簇的坐标应用于 HiFi-GAN 还原得到增强后的语音。实验结果表明,SELM在客观指标上与当下最先进模型取得了可比性能,同时在主观听感上取得了更好的效果。
提出的方案
如图1所示,SELM 基于 Encoder-Decoder 框架,包括一个编码器,一个瓶颈层和一个解码器。首先,预训练自监督学习(SSL)模型 WavLM 从输入带噪音频中提取连续特征,在此之后通过 K-Means 聚类将连续特征转化为离散表征。在此之后,语言模型建模隐藏在离散表征中的上下文信息。最后,通过获取聚类中心簇的坐标将预测的离散表征转换为连续特征,进一步通过 HiFi-GAN 将连续特征还原得到增强后的语音。
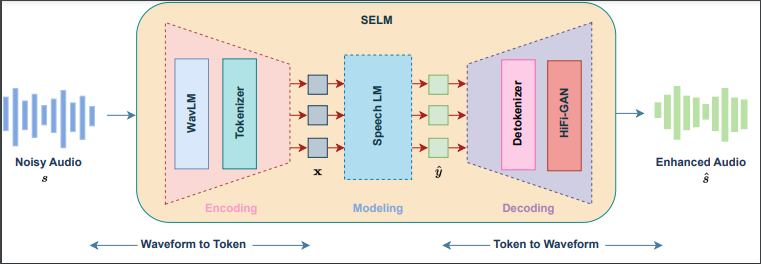
语音编码器
在本文提出的模型中,语音编码器由预训练自监督学习(SSL)模型 WavLM 和 K-Means 聚类模型组成。基于 CNN 编码器和 Transformer 的结构让 WavLM 拥有捕获上下文信息的能力,其输出的表征可以同时很好的保留声学和语义信息,进而适合应用在波形重建任务之中。在获得 WavLM 输出的连续特征之后,通过迭代计算和更新中心簇坐标,K-Means 聚类模型将连续特征转变成离散表征。
语言模型
在本文提出的模型中,语言模型参考了 GPT 系列的 decoder-only 模型结构,使用 Transformer 作为语言模型的骨架。我们从掩码预测的范式中得到灵感,并将其应用到了语音增强任务之中。我们在实验中发现,带噪音频的离散表征和其对应的干净语音的离散表征拥有着内在的相似性,进而可以将语音增强任务看作是一种特殊的掩码预测任务。通过非自回归的预测形式,语言模型可以充分捕捉上下文信息,进而实现更好的建模。
语音解码器
在本文提出的模型中,语音解码器由反序列化器(De-Tokenizer)和 Hi-Fi GAN 组成。具体来说,反序列化器由嵌入层和 Conformer Block 组成,通过获取聚类中心簇的坐标,预测的离散表征被转换为连续特征,连续特征进一步通过 Conformer 预测得到对应的 WavLM 表征。得到的连续特征再通过 HiFi-GAN 还原得到增强后的语音。
实验
数据集
使用 WeNetSpeech 和 GigaSpeech 的子集即2000小时的中英文数据来训练语音编码器和语音解码器。对于语言模型,训练数据来自于 LibriMix、VCTK与DNS2021竞赛数据集,噪声数据来自于 WHAM! 和 DEMAND数据集,房间冲激响应来自于 openSLR26 和 openSLR28。所用训练数据采用动态加噪方法,信噪比在 -5~20dB 间随机采样。测试集由 DNS2021 测试集和仿真测试集两部分组成。
结果
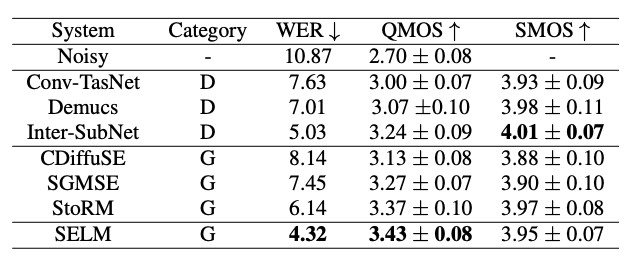
如表1所示,对比判别式和生成式方案可以发现,生成式方案在感知相关的指标如 DNSMOS 上表现更佳,展现了其有效解决噪声泄漏和过度抑制的能力。而由于生成式模型的输出在采样点级别上并不一定能够严格与标签保持一致,所以在 LLR 和 cosine 相似度上,判别式模型表现更好。与此同时,我们对比 SELM 的不同变种,可以发现聚类数目与指标变现之间存在权衡关系。与其他方法对比, SELM 表现出更好的效果,这也展示了使用离散表征来进行语音增强的良好前景。如表2所示,可以看到 SELM 在提升语音质量和听感的同时,还能够有效提升语音可懂度,在WER指标上取得了最佳结果。
实验结果表明,SELM 展现出了可以生成高质量音频,让语音拥有更好听感的同时,提高机器识别率的能力。
表1 不同系统在 DNS竞赛测试集上的表现,“G”和“D”分别代表生成式和判别式
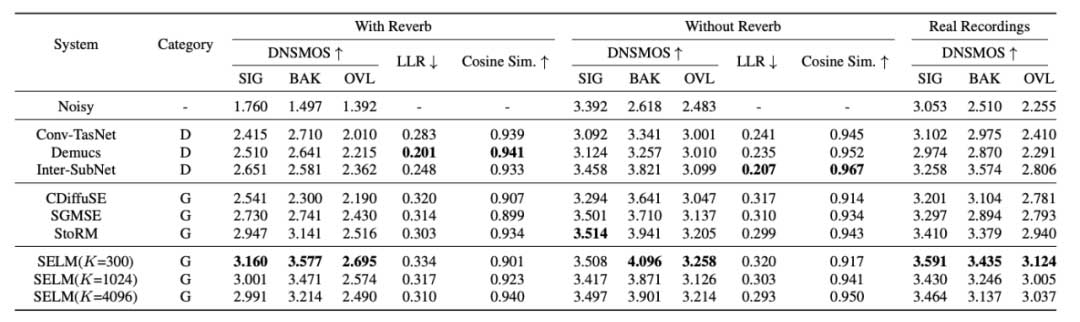
表2 不同系统在仿真测试集上的各项指标
参考文献
[1] Peidong Wang, Ke Tan, et al., “Bridging the gap between monaural speech enhancement and recognition with distortion-independent acoustic modeling,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 28, pp. 39–48, 2019.
[2] Santiago Pascual et al., “SEGAN: Speech Enhancement Generative Adversarial Network,” in Proc. Interspeech, 2017, pp. 3642–3646.
[3] Sanyuan Chen et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
[4] Chengyi Wang et al., “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023.
[5] Haibin Wu, Kai-Wei Chang, Yuan-Kuei Wu, and Hung-yi Lee, “Speechgen: Unlocking the generative power of speech language models with prompts,” arXiv preprint arXiv:2306.02207, 2023.
[6] Xiaofei Wang et al., “Speechx: Neural codec language model as a versatile speech transformer,” arXiv preprint arXiv:2308.06873, 2023.
[7] Hakan Erdogan et al., “Tokensplit: Using discrete speech representations for direct, refined, and transcript-conditioned speech separation and recognition,” arXiv preprint arXiv:2308.10415, 2023.
[8] Matthew Le et al., “Voicebox: Text-guided multilingual universal speech generation at scale,” arXiv preprint arXiv:2306.15687, 2023.
[9] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al., “Improving language understanding by generative pre-training,” 2018.
[10] Jun Chen et al., “Inter-subnet: Speech enhancement with subband interaction,” in Proc. ICASSP. IEEE, 2023, pp. 1–5.
[11] Xinfa Zhu, Yuanjun Lv, Yi Lei, Tao Li, Wendi He, Hongbin Zhou, and Lei Xie, “Vec-tok speech: Speech vectorization and tokenization for neural speech generation,” arXiv preprint arXiv:2310.07246, 2023.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
