
为解决基于体素的处理点云方法中收集的上下文较少的问题,作者提出了 OctAttention 的拓展上下文的深度学习框架。该框架采用八叉树结构,通过收集点云中兄弟节点和祖先节点的信息以无损方式编码八叉树符号序列,从而实现点云的压缩。该方法在 LiDAR 数据集(例如 SemanticKITTI)和物体点云数据集(例如 MPEG 8i、MVUB)上获得了 10%-35% 的 BD-Rate 增益,同时与基于体素的基线相比,节省了 95% 的编码时间百分比。
作者:Chunyang Fu, Ge Li, Rui Song, Wei Gao, Shan Liu
来源:AAAI 2022
论文题目:OctAttention: Octree-Based Large-Scale Contexts Model for Point Cloud Compression
论文链接:https://arxiv.org/abs/2202.06028
内容整理:梁焕雄
引言
基于八叉树的压缩点云的模型对分辨率具有鲁棒性,并且它还利用比基于体素的模型更广泛的上下文。然而,先前基于八叉树的方法忽略了兄弟节点(即同一八叉树级别中的节点)的特征信息。
为此,作者提出了新的基于八叉树的点云压缩方法 OctAttention。作者将点云编码为八叉树,并将当前节点的祖先节点、兄弟节点以及兄弟节点的祖先的特征纳入上下文。作者采用树结构的注意力机制,表达不同节点在预测中的贡献。作者还提出了一种掩码操作来并行编码多个节点。论文所提出的模型与 3D LiDAR 数据集 SemanticKITTI 、物体点云数据集 MVUB 和 MPEG 8i 上SOTA的方法进行了比较。实验表明,该方法获得了 10%-35% 的 BD-Rate 增益,同时与基于体素的方法相比,节省了 95% 的编码时间。
方法
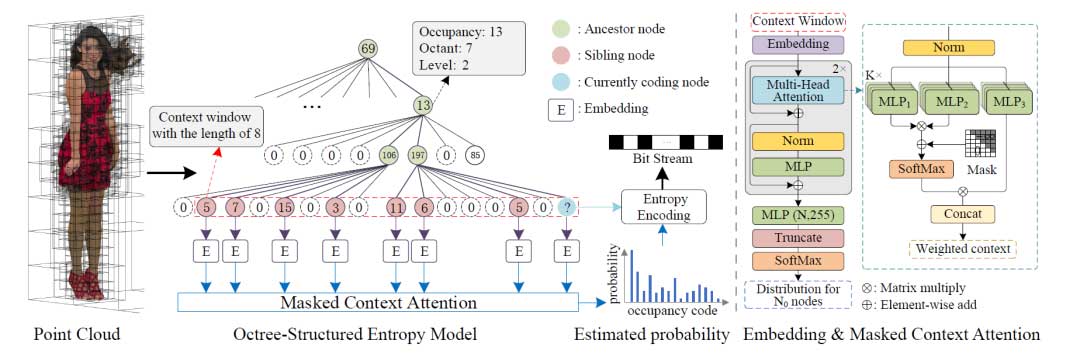
作者提出了一种扩展的上下文和树形结构的注意力机制。上下文利用了兄弟姐妹及其祖先的特征。为了在大规模上下文中实现准确灵活的预测,作者采用树结构的注意力机制来确定上下文中每个节点的重要性。最后,作者根据注意力上下文推断每个八叉树节点的占用率。作者还进一步提出了一种掩码操作来减少由于上下文的拓展而延长的编码时间。
八叉树结构

八叉树沿着 PQ 边界框的最大边长递归地将立方体空间划分为 8 个相等的八分圆。8 个子立方体的占用状态构成一个 8 位二进制占用代码。只有非空子立方体才会被标记为 1 并被进一步细分,其他未占用的立方体将被标记为 0。
上下文模型
作者提出了扩展的大规模上下文以预测更准确的上下文占用分布情况。首先以广度优先的顺序遍历八叉树。然后,对于序列中每个当前编码节点 ni,作者构造一个上下文窗口 {ni-N+1,···,nk,···,ni-1,ni},长度为 N。上下文窗口随着当前编码节点向前滑动。考虑到节点与其祖先节点之间的依赖关系,作者进一步引入上下文窗口中N 个节点的 K -1 个祖先。最后,Q(x)将窗口中的分布 xi 分解为每个占用符号 的条件概率的乘积,如下所示:

树结构的注意力机制
作者采用自注意力机制来发现节点之间的相似性和强依赖性,过滤掉不相关的节点,强调有用的节点。由于具有相似祖先和兄弟姐妹的节点往往遵循相似的分布,因此基于兄弟节点与估计节点 ni 之间的相似性来估计占用率是合理的。在头部 t(t = 0,1,…,K-1) 中,上下文中第 m 个和第 n 个兄弟节点之间的注意力图中的注意力分数标量窗口定义为:

掩码操作
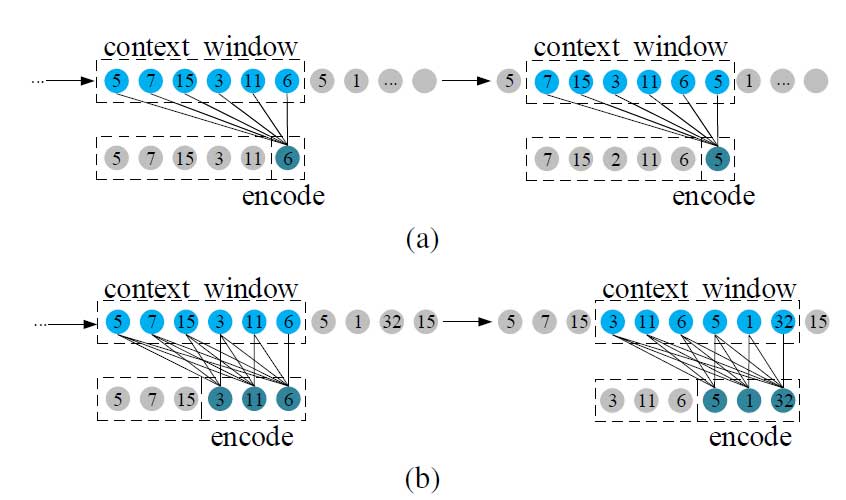
为了减少编码时间,作者引入了掩码操作。在训练和测试时,每个节点都只能访问上下文窗口中前面的节点。由此可以在一次传播中同时对它们进行编码。在对窗口中的第 j 个节点进行编码时,只有 j 个节点可用于推理。与图2(a)中最大感受野的方式相比,平均每个节点的感受野从N缩小到 (2N – N0 + 1)/2。尽管感受野缩小了,但训练期间掩模操作造成的性能损失可以忽略不计。
学习
学习过程中,损失函数为预测占用代码和实际之间的交叉熵,其定义为:
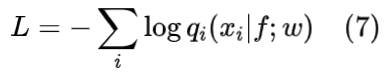
实验结果
对比实验
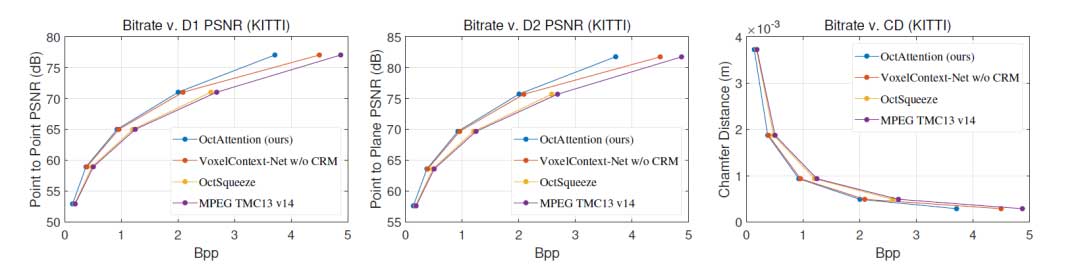
LiDAR数据集:如图 3所示,OctAttention在所有比特率下都优于其他方法。平均而言,与 G-PCC 相比,OctAttention 在 SemanticKITTI 上节省了 25.4% 的比特率,而 OctSqueeze 仅节省了不到 4% 的比特率。在高比特率下,与SOTA方法 VoxelContext-Net相比,OctAttention实现了超过 11% 的比特率相对降低。这可能是由于基于体素的方法在稀疏场景中缺少占用体素。实验结果证明了拓展上下文模型的有效性。
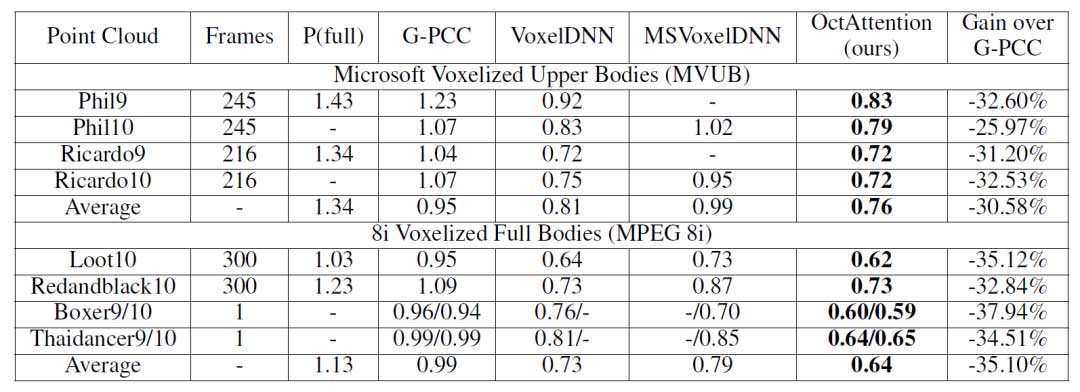
物体点云数据集:如表1所示,OctAttention优于VoxelDNN,并达到了相对于 G-PCC 32.8% 的平均增益。
消融实验
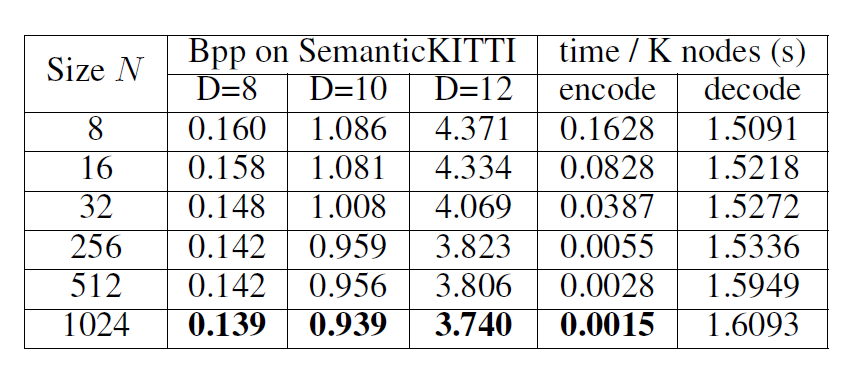
如表2所示,通过将上下文窗口大小从 8 扩大到 1024,可以节省 14% 的比特率。编码时间随着上下文窗口的增加而减少。
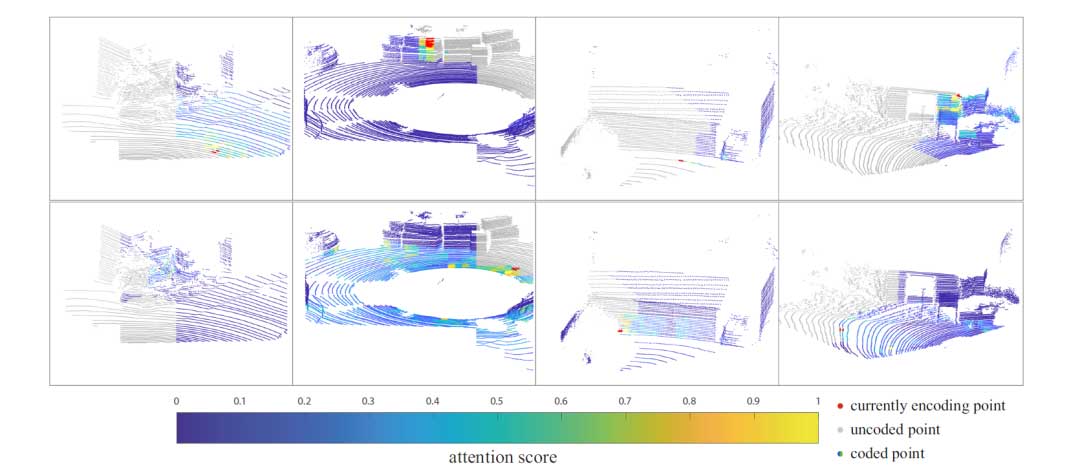
如图4所示,注意力机制根据线、平面、曲面和曲率等几何模式发现上下文窗口中点之间的相似性。对当前编码节点具有最高注意力得分的节点(红色点)用黄色表示。它证实了注意力机制可以利用大规模上下文中兄弟节点的相似特征来预测占用率。
结论
作者提出了新的基于八叉树的压缩模型 OctAttention,通过利用大规模上下文来进行稀疏和密集点云几何压缩。作者通过在八叉树中引入兄弟节点扩展上下文。同时采用注意力机制来强调重要节点以利用这些丰富的特征,并进一步提出了一种掩码操作,以在上下文中引入兄弟姐妹的情况下实现并行编码。作者在 LiDAR 数据集 SemanticKITTI 和物体点云数据集 MVUB、MPEG 8i上进行评估。结果表明,所提出的方法在两种类型的数据集上都达到了SOTA的效果。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
