
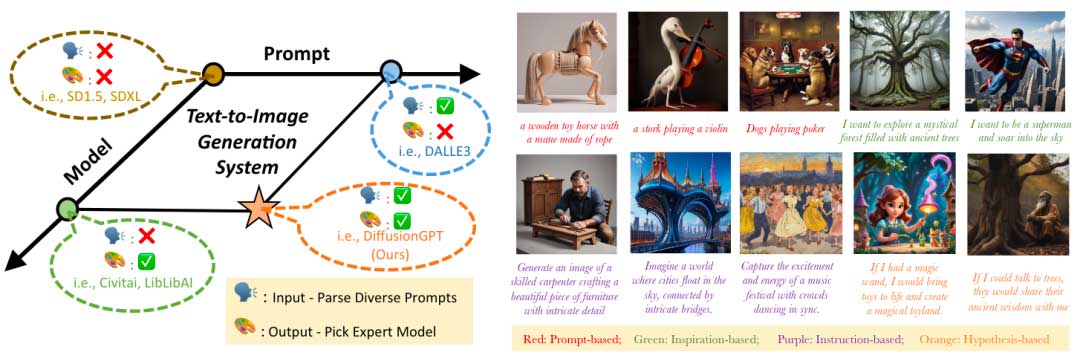
扩散模型为图像生成领域开辟了新途径,导致开源平台上共享的高质量模型激增。然而,当前的文本到图像系统仍然存在一个重大挑战,通常无法处理不同的输入,或者仅限于单一模型结果。目前的统一尝试往往分为两个方面:i)在输入阶段解析多样化的提示;ii) 激活专家模型进行输出。为了结合两个领域的优点,本文提出了 DiffusionGPT,它利用大型语言模型 (LLM) 提供一个统一的生成系统,能够无缝地容纳各种类型的提示并集成领域专家模型。DiffusionGPT 基于先验知识为各种生成模型构建特定领域的树。当提供输入时,大语言模型会解析提示并使用思想树来指导选择适当的模型,从而放宽输入约束并确保在不同领域的卓越性能。此外,本文还引入了先进的数据库,其中思想树富含人类反馈,使模型选择过程与人类偏好保持一致。通过大量的实验和比较,证明了 DiffusionGPT 的有效性,展示了其在不同领域突破图像合成界限的潜力。
来源:Arxiv
论文题目:DiffusionGPT: LLM-Driven Text-to-Image Generation System
论文链接:http://arxiv.org/abs/2401.10061
论文作者:Jie Qin, Jie Wu, Weifeng Chen, Yuxi Ren, Huixia Li, Hefeng Wu, Xuefeng Xiao, Rui Wang, Shilei Wen
内容整理:黄海涛
介绍
近年来,扩散模型在图像生成任务中盛行,彻底改变了图像编辑、风格化和其他相关任务。DALLE-2和Imagen都非常擅长根据文本提示生成图像。然而它们的非开源性质阻碍了广泛普及和相应的生态发展。第一个开源文本到图像扩散模型,称为稳定扩散模型(SD),它迅速流行并广泛使用。为SD量身定制的各种技术,例如Controlnet、Lora,进一步为SD的发展铺平了道路,并促进了其与各种应用的集成。SDXL是最新的图像生成模型,专为提供具有复杂细节和艺术构图的卓越照片级逼真输出而量身定制。尽管取得了显着的进步,当前的稳定扩散模型在应用于现实场景时仍面临两个关键挑战:
- 模型限制:虽然稳定扩散模型(例如 SD1.5)表现出对广泛提示的适应性,但它们在特定领域表现不佳。相反,特定领域模型(例如SD1.5+Lora)擅长在特定子领域内产生极端的生成性能,但缺乏通用性。
- 提示约束:在稳定扩散的训练过程中,文本信息通常由描述性语句组成,例如标题。然而,在使用这些模型时,会遇到各种各样的提示类型,包括说明和灵感。当前的生成模型很难为这些不同的提示类型实现最佳的生成性能。
为了解决上述问题,本文提出了DiffusionGPT,它利用大型语言模型(LLM)提供一种一一对应的生成系统,可以无缝集成高级生成模型并有效解析不同的提示。DiffusionGPT 构建了一个思想树(ToT)结构,其中包含基于先验知识和人类反馈的各种生成模型。当出现输入提示时,LLM 首先解析提示,然后引导 ToT 识别最合适的模型来生成所需的模型输出。
这项工作的贡献可以概括为:
- 新见解:DiffusionGPT 采用大型语言模型 (LLM) 来驱动整个文本到图像生成系统。大语言模型充当认知引擎,处理不同的输入并促进专家选择输出。
- 一体化系统:DiffusionGPT 通过与各种扩散模型兼容,提供了多功能且专业的解决方案。与仅限于描述性提示的现有方法不同,本文的框架可以处理各种提示类型,从而扩展了其适用性。
- 效率和开拓性:DiffusionGPT 以其免训练的特性而脱颖而出,可以作为即插即用的解决方案轻松集成。通过结合思想树(ToT)和人类反馈,系统实现了更高的准确性,并开创了聚合更多专家的灵活流程。
- 高效性:DiffusionGPT 优于传统的稳定扩散模型,展现出显着的进步。通过提供一体化系统,本文为图像生成领域的社区发展提供了一条更高效、更有效的途径。
方法
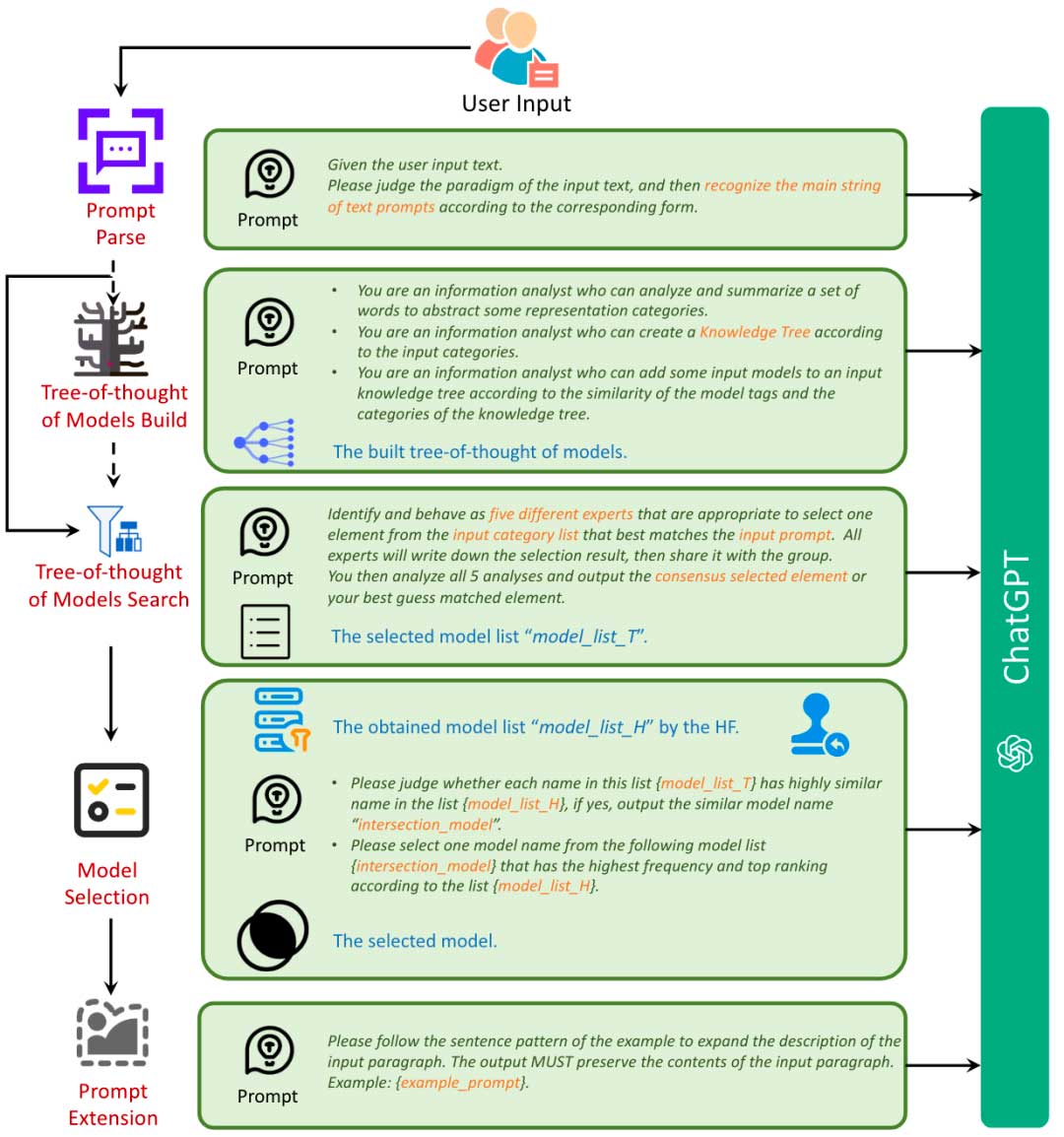
DiffusionGPT的组成包括大型语言模型和来自开源社区的各种领域专家生成模型(例如 Hugging Face、Civitai)。LLM承担核心控制器的角色,维护系统的整个工作流程,包括四个步骤:提示解析、构建和搜索模型的思想树、人工反馈的模型选择和生成的执行。DiffusionGPT的整体流程如下图所示:
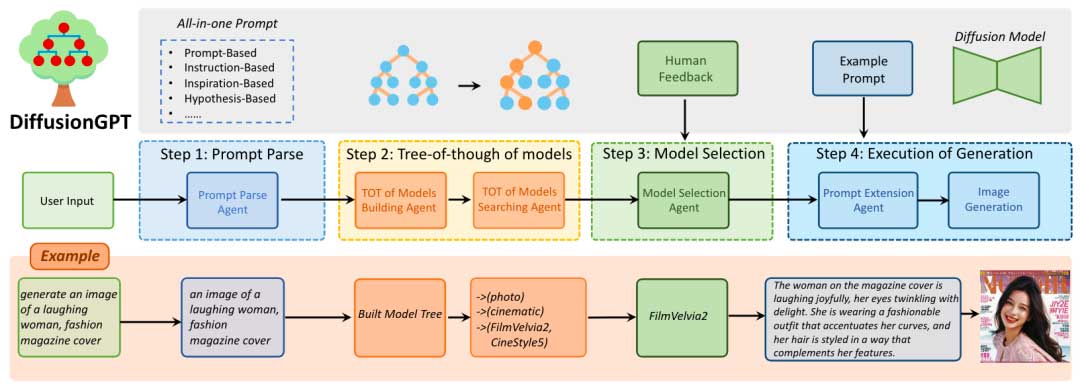
Prompt Parse
Prompt-based:将整个输入作为生成的提示。例如,如果输入是“一只狗”,则用于生成的提示将是“一只狗”。
Instruction-based:提取指令的核心部分作为生成提示。例如,如果输入是“生成狗的图像”,则识别的提示将是“狗的图像”。
Inspiration-based:提取期望的目标主题并用作生成的提示(例如,输入:“我想看海滩”;识别:“海滩”)。
Hypothesis-based:它涉及提取假设条件(“如果xxx,我会xxx”)和即将采取行动的对象作为生成提示。例如,如果输入是“如果你给我一个玩具,我会笑得很开心”,识别到的提示将是“一个玩具和一张笑脸”。通过识别这些形式的提示,Prompt Parse使 DiffusionGPT 能够准确识别用户想要生成的核心内容,同时减轻噪声文本的影响。这个过程对于选择合适的生成模型并获得高质量的生成结果至关重要。
Tree-of-thought of Models
使用 TOT 构建模型树
模型构建代理的思想树(TOT)用于根据所有模型的标签属性自动构建模型树。通过输入所有模型的标签属性进入代理后,它分析并总结从主题域和风格域派生的潜在类别。然后,风格类别作为子类别合并到主题类别中,建立两层分层树结构。随后,所有模型根据其属性被分配到合适的叶节点,从而完成综合模型树结构。下图展示了模型树的直观表示。由于模型树是由代理自动构建的,因此这种方法确保了合并新模型的方便可扩展性。每当添加新模型时,代理都会根据其属性将它们无缝地放置在模型树中的适当位置。
使用 TOT 搜索模型树
模型树中的搜索过程基于模型搜索代理的思想树 (TOT),旨在识别与给定提示密切相关的候选模型集。这种搜索方法采用广度优先的方法,系统地评估每个叶节点的最佳子类别。在每个级别,都会将类别与输入提示进行比较,以确定最匹配的类别。这个迭代过程继续推导后续叶节点的候选集,并且搜索一直进行到到达最终节点,在此处获得模型的候选集。该候选模型集作为后续阶段模型选择的基础。
Model Selection
模型选择阶段的目的是从上一阶段获得的候选集中识别出最适合生成所需图像的模型。该候选集代表整个模型库的子集,由与输入提示表现出较高匹配度的模型组成。然而,开源社区提供的属性信息有限,在向大语言模型(LLM)提供详细模型信息的同时精确确定最佳模型带来了挑战。为了解决这个问题,我们提出了一种模型选择代理,它利用人类反馈并利用优势数据库技术使模型选择过程与人类偏好保持一致。
对于数据库,我们采用奖励模型来计算基于 10,000 个提示的语料库的所有模型生成结果的分数,并存储分数信息。收到输入提示后,我们计算输入提示与 10,000 个提示之间的语义相似度,识别出相似度最高的前 5 个提示。随后,模型选择代理从离线数据库中检索这些提示的每个模型的预先计算性能,并为每个选定的提示选择前 5 个模型。此过程会生成 5×5 模型的候选集。
然后代理将模型集与TOT阶段获得的候选集相交,重点关注出现概率较高、排名相对较高的模型,这些模型将成为图像生成的最终选择。
Execution of Generation
一旦选择了最合适的模型,所选择的生成模型就可以利用获得的核心提示来生成所需的图像。
提示扩展。为了提高生成过程中提示的质量,采用了提示扩展代理来增强提示。该代理利用所选模型中的提示示例来自动丰富输入提示,示例提示和输入提示均发送至情境学习范式中的大语言模型。特别地,该代理按照示例提示的句型将丰富的描述和详细的词汇融入到输入提示中。
实验
实验设置
在实验设置中,采用的主要大语言模型 (LLM) 控制器是 ChatGPT,特别利用 text-davinci-003 版本,可通过 OpenAI API 访问。为了方便指导LLM的回答,采用了LangChain框架,该框架有效地控制和指导了生成的输出。对于实验中使用的生成模型,选择了来自 Civitai 和 Hugging Face 社区的各种模型,选择过程涉及在这些平台上提供的不同类型或风格中选择最受欢迎的模型。
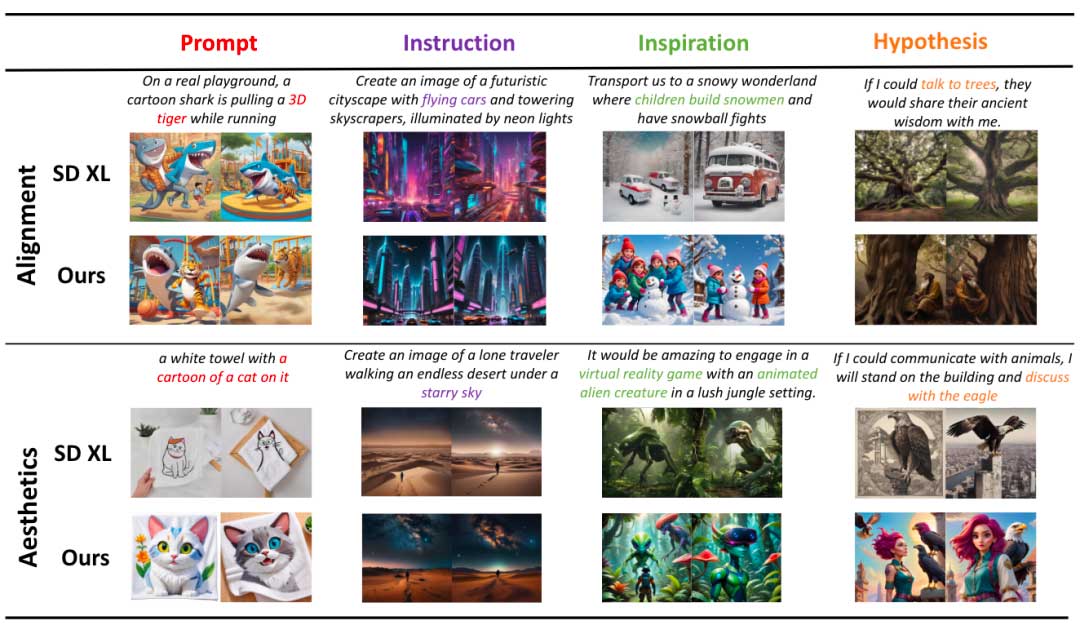
定性结果
通过实验发现发现基本模型有两个值得注意的问题:i) 语义缺乏:基本模型生成的图像对从输入提示派生的特定语义类的关注有限,导致整体捕获不完整。这种限制在各种提示类型中尤其明显,其中基本模型很难有效地生成与“男人、厨师、孩子和玩具乐园”相关的对象。ii)在人类相关目标上表现不佳:基础模型在为人类相关对象生成准确的面部和身体细节方面面临挑战,导致图像质量不佳。当比较描绘“女孩和情侣”的图像的美学品质时,这种缺陷就变得显而易见。
相比之下,DiffusionGPT 有效地解决了这些限制。系统生成的图像展示了目标区域相对完整的表示,成功捕获了包含整个输入提示的语义信息。诸如“吹口哨的人弹钢琴”和“孩子们堆雪人和打雪仗的雪域仙境”等例子展示了本文的系统涵盖更广泛背景的能力。此外,本文的系统擅长为与人类相关的物体生成更详细和准确的图像,例如“星空下的浪漫情侣”的提示。

随着公开通用生成模型的进步,新改进的方法 SDXL 已成为一种有前途的方法,展示了卓越的生成结果。但是值得注意的是 SDXL 在特定情况下偶尔会出现部分语义信息丢失的情况。例如,涉及基于提示的类别中的“3D老虎”或基于指令的类别中的“飞行汽车”的提示的生成结果可能缺乏准确的表示。相比之下,本文的系统擅长生成更精确且更具视觉吸引力的表示。
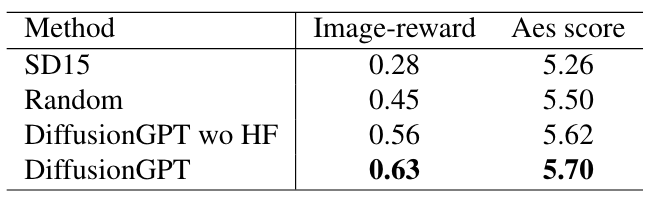
定量结果
用户偏好与下表中呈现的定量结果之间的一致性体现了DiffusionGPT 的稳健性和有效性。为了进一步评估不同的生成结果,采用了美学分数和人类反馈相关的奖励模型。通过将基本版本与基线模型 SD1.5 的效果进行比较,下表中的结果表明,本文的整体框架在图像质量和审美得分方面优于 SD15,分别实现了 0.35% 和 0.44% 的改进。
局限性和未来工作
尽管DiffusionGPT已经展示了生成高质量图像的能力,但仍然存在一些局限性,未来的计划如下:
- 反馈驱动的优化。目标是将反馈直接纳入LLM的优化过程中,从而实现更精细的解析和模型选择。
- 候选模型的扩展。为了进一步丰富模型生成空间并取得更令人印象深刻的结果,将扩展可用模型的库。
- 超越文本到图像任务。将见解应用到更广泛的任务中,包括可控生成、样式迁移、属性编辑等。
总结
本文提出了 Diffusion-GPT,这是一种一站式框架,可以无缝集成卓越的生成模型并有效解析不同的提示。通过利用大语言模型 (LLM),Diffusion-GPT 深入了解输入提示的意图,并从思想树 (ToT) 结构中选择最合适的模型。该框架提供了跨不同提示和领域的多功能性和卓越性能,同时还通过优势数据库纳入了人类反馈。综上所述,Diffusion-GPT无需专门训练,可以轻松集成为即插即用的解决方案,为该领域的社区发展提供了一条高效且有效的途径。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
