
本文提出了一种名为 HiNeRV 的神经表示模型用于视频压缩。HiNeRV 将轻量级层与新颖的分层位置编码相结合,采用深度卷积、MLP 和插值层来构建具有高容量的深而宽的网络架构。HiNeRV 也是一种同时对视频中的帧和块进行统一表示编码的方法,它比现有方法提供了更高的性能和灵活性。此外,本文进一步构建了一个基于 HiNeRV 的视频编解码器以及用于训练、剪枝和量化的精细管道,可以在有损模型压缩期间更好地保持 HiNeRV 的性能。
题目:HiNeRV: Video Compression with Hierarchical Encoding-based Neural Representation
作者:Ho Man Kwan, Ge Gao, Fan Zhang et al.
来源:NeurIPS 2023
文章地址:https://openreview.net/forum?id=CpoS56pYnU
内容整理:令潇越
引言
INR(Implicit Neural Representation,隐式神经表示) 通常学习坐标到值的映射以支持原始信号的隐式重建。当使用 INR 编码视频时,可以通过对各个输入视频执行模型压缩来实现视频压缩。与其他方法相比,INR 方法表现出相对较高的解码速度,但未能提供与视频压缩领域的最新技术相当的速率质量性能。这主要是由于所采用的网络架构的简单性,限制了它们的表示能力。现有的一些 INR 方法使用的卷积层或子像素卷积层在参数效率上存在问题,而基于傅立叶的位置编码在训练时间上较长且只能达到次优的重建质量。
在本文中,作者提出了一种名为 HiNeRV 的全新隐式神经表示模型,用于视频压缩。相较于现有 INR 方法,本文采用了一种新的上采样层,融合了双线性插值和来自多分辨率局部特征网格的分层编码。这不仅提高了参数效率,还在给定存储预算下最大限度地增强了表示能力。网络主要基于 MLPs 和深度卷积层,从而实现更深、更宽的网络架构。与此同时,通过使用重叠块进行训练,HiNeRV 可以在帧和块表示之间无缝切换,实现了在帧和块表示方面的统一性能改进。这种设计也为硬件实现提供了灵活性,使编码和解码过程可以根据需要在帧和块之间切换。文章还对模型压缩流程进行了优化,采用自适应剪枝技术来减轻剪枝对模型的负面影响,并通过量化感知训练来微调模型性能,以实现更低位深度的量化,达到更好的速率-失真权衡。
本文的主要贡献如下:
- 提出了一种名为 HiNeRV 的新 INR模型,采用基于分层编码的神经表示。
- 通过添加填充来采用统一的表示,以少量的计算开销换取了额外的灵活性和性能增益。
- 构建了一个基于 HiNeRV 的视频编解码器,并通过使用自适应剪枝和量化感知训练来细化模型压缩管道,以更好地保持 INR 的重建质量。
- 所提出方法的压缩性能优于现有的 INR 模型,并且与许多传统/基于学习的视频编码算法相当。
模型
整体架构
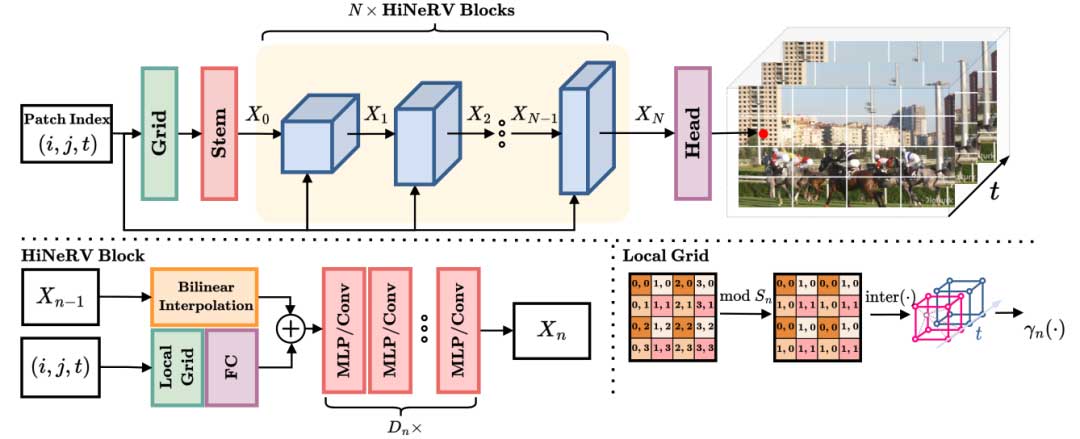
图 1 (上)展示了HiNeRV 的整体架构,包含一个基础编码层、一个 stem 层、N 个 HiNeRV 块和一个 head 层。在 HiNeRV 中,每个 RGB 视频帧首先被空间分割成大小为 M x M 的块,每个块通过一次前向传递进行重建。模型首先采用块坐标 (i,j,t) 计算大小为 M0 x M0 x C0 的基础特征图 X0。之后,N 个 HiNeRV 块逐步上采样和处理特征图,生成中间特征图 Xn ,最终通过 head 层将特征图投影到输出 Y,目标大小为 M x M x C。
基础编码层和 stem 层
HiNeRV 首先通过公式 (1) 将输入块的坐标映射到基础特征图 X0:
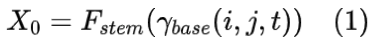
其中γbase(i,j,t), 是从学习的特征网格中插值得到的位置编码。然后,采用卷积层 Fsterm 将特征图投影到所需通道数量 C0 。与大多数现有的视频 INR 方法不同,HiNeRV 采用了基于网格的编码而非傅立叶编码。作者使用了 FFNeRV( FFNeRV: Flow-Guided Frame-Wise Neural Representations for Videos)中引入的多分辨率时间网格,利用帧索引和基于帧的坐标来插值特征块。为了增强特征网格的表达力并保持紧凑的多分辨率网格,文章在每个网格级别降低时间分辨率的同时增加通道的数量。
HiNeRV 块
图 2(左下)显示了 HiNeRV 块的结构。本文采用 ConvNeXt 作为 中的网络块, 是 MLP 层与深度卷积的组合。

Head 层
最终输出 F 通过在第 N 个 HiNeRV 块的输出上应用带有 Sigmoid 激活函数的线性层 Fhead得到。
带有分层编码的上采样
现有的基于 NeRV 的方法通常使用子像素卷积层进行特征图上采样,但这具有较高的参数复杂性。作者提出了一种新的网格编码方法,称为分层编码,用于增强双线性插值的上采样能力,而不显著增加存储成本。
与使用全局坐标计算编码的普通基于网格的编码不同,分层编码采用局部坐标来编码相对位置信息,局部坐标是上采样特征图中的像素与其在原始特征图中最近的像素的相对位置,使用局部坐标可显著减小特征网格的大小。在上采样过程中,首先通过双线性插值生成上采样的特征图;然后,对上采样特征图中的所有帧像素坐标进行计算,得到相应的局部坐标,这些局部坐标用于计算分层编码;为了获得分层编码,文章利用帧索引和局部坐标执行三线性插值,从所有局部网格提取编码,然后连接编码并应用线性层 Fenc 将编码通道与特征图匹配。
统一基于帧和基于块的表示
最近的 INR 视频方法可以划分为基于帧或基于块表示,然而由于边界效应,这两种表示方法通常不可切换。为了解决这个问题,HiNeRV 通过在基于块的表示中进行计算,并使用适当的填充,使其能够灵活地配置为基于块或基于帧表示,而无需重新训练。具体地说,在将 HiNeRV 配置为基于块的表示时,网络在重叠的块中执行计算,称之为填充,填充的像素数量取决于网络配置。在没有适当填充的情况下,块边界处可能会出现缺失值,导致不连续性。在实现中,对填充的块进行中间计算,然后裁剪非重叠的部分作为输出块,而在帧配置中则不需要填充。
模型压缩流程
为了进一步增强视频压缩性能,作者对 NeRV 中的原始模型压缩流程进行了优化。主要变化包括:1)对参数进行自适应权重剪枝;2)使用 Quant-Noise 进行量化感知训练。剪枝操作中,作者考虑了每层的 L1 范数和相应层的大小。对于量化,作者采用 6 位量化,并使用 Quant-Noise 进行短暂的微调,有效减小了量化误差。
实验
视频表示
文章使用 Bunny 序列 (132 帧,1280×720 分辨率)和 UVG 数据集进行实验,UVG 共有 7 个视频,3900 帧,分辨率为 1920×1080。针对 UVG 数据集,设置了三种尺度以针对 NeRV 中的 S/M/L尺度,而为 Bunny 数据集配置了两种不同的尺度 XXS/XS 以及尺度 S。表 1 和表 2 列出了每个尺度对应的参数数量。

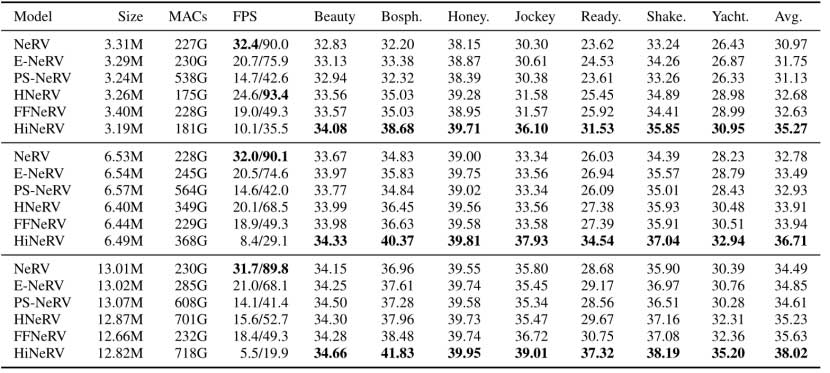
可以观察到, HiNeRV 在 Bunny 和 UVG 数据集上的每个尺度的重建质量方面都优于所有基准模型,并且在 UVG 数据集中的所有测试序列上表现优于所有其他方法。虽然 HiNeRV 的编码和解码速度比其他方法慢,但 HiNeRV 用更少的 MAC 实现了更高的整体 PSNR 值,进一步优化可能有助于减少其延迟。
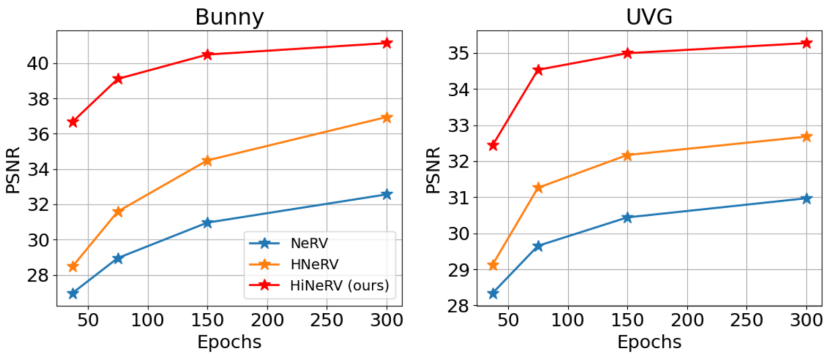
图 2 显示了不同方法在不同训练时期的重建质量方面的性能。HiNeRV 的 37 epoch 模型在两个数据集上实现了与 300 epoch 的 HNeRV ( HNeRV: A Hybrid Neural Representation for Videos ) 相似的重建质量。
视频压缩
文章使用两个测试数据集进行比较:UVG 和 MCL-JCV 。作者对三个 INR 模型进行了剪枝,去除了 15% 的权重,并对模型进行了另外 60 个 epoch 的微调,这些模型使用 Quant-Noise 进一步优化,噪声比为 90%,持续 30 个 epoch。为了获得实际速率,接着执行算术熵编码并将包括剪枝掩码和量化参数在内的所有基本信息组合到比特流中。

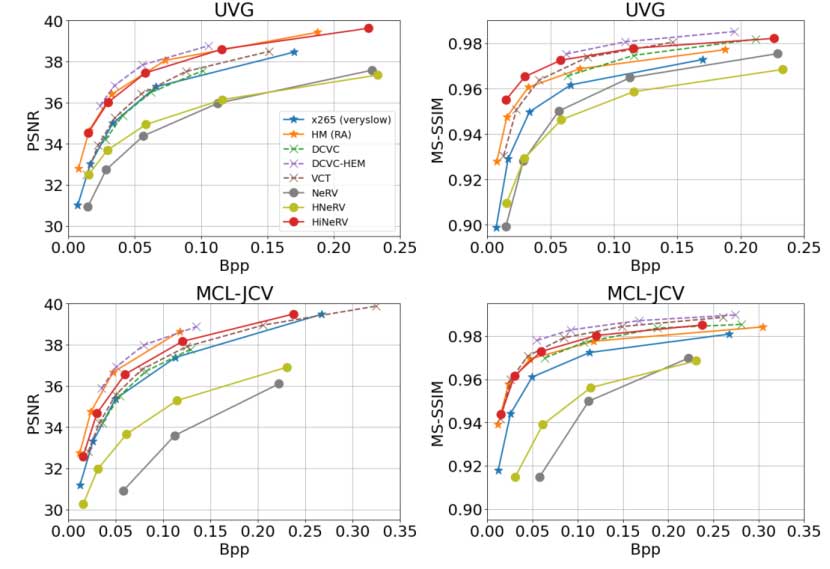
表 3 总结了两个数据集的平均 BD rate结果,图 3 展示了 UVG 和 MCL-JCV 数据集的总体速率质量性能。所有结果表明,与大多数传统编解码器和基于学习的编解码器相比,HiNeRV 提供了有竞争力的编码效率。尽管 HiNeRV 尚未完全优化端到端(熵编码和量化未在循环中优化),但它仍然优于许多最先进的端到端优化的基于学习的方法。
消融实验
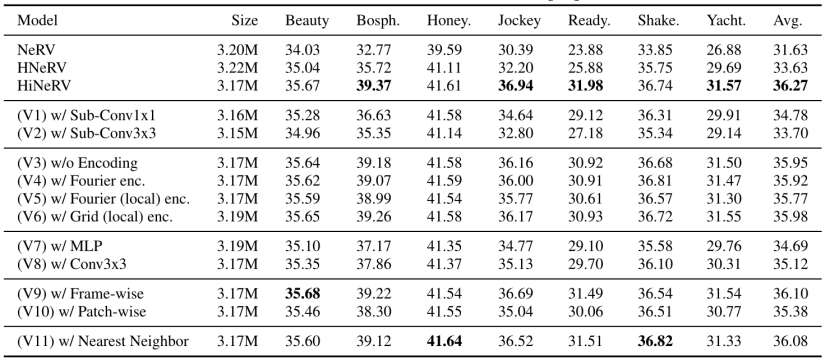
首先,通过与替代的上采样层(例如子像素卷积层)进行比较,确认了使用带有分层编码的双线性插值在提高模型性能方面的有效性。其次,通过验证四个上采样编码的变体,包括不同的傅立叶编码和基于网格的编码,进一步确认了上采样编码对模型性能的贡献。此外,对 ConvNeXt 块进行与其他替代方案的比较,包括 MLP 块和包含两个卷积层的块,验证了 ConvNeXt 块的性能。第四,生成用于帧和块输入配置的两个变体,以研究模型在不同输入表示下的性能表现。最后,通过用最近邻插值代替双线性插值,探究了不同插值方法对模型性能的影响。消融研究结果如图 4 所示,完整的 HiNeRV 模型优于 UVG 数据集上的所有替代模型 ( V1-V11 ) 。
结论
文章提出了一种新的神经表示模型 HiNeRV 用于视频压缩,它比许多传统的和基于学习的视频编解码器(包括基于 INR 的视频编解码器)表现出优越的编码性能。所展示的改进与新的创新相关,包括基于双线性插值的分层编码、统一表示和改进的模型压缩管道。尽管 HiNeRV 尚未完全优化端到端,但它仍然实现了与最先进的基于端到端优化学习的性能相当的性能,与现有基于 NeRV 的算法相比有显着改进。这证明了利用 INR 进行视频压缩应用的巨大潜力。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
