

研究意义
近些年来,深度强化学习在许多应用领域当中展现出了巨大的发展潜力,例如在围棋和电子游戏当中取得了巨大成就,它已然是人工智能研究领域用于建模人类决策智能的重要方法。除了单个个体的决策智能之外,群体协作智能也是人类智能的重要组成部分,在人类历史进程当中发挥着不可替代的作用,而多智能体强化学习便是模拟人类群体协作智能的重要手段,能够帮助处理协作型的多智能体决策问题。
在现实世界当中,人类群体往往能够比较好地处理协作过程中发生的意外情况,或者有意识地将过往的协作经验迁移到一个新的合作任务当中,这种群体协作的灵活性和可迁移性是人类协作智能的重要表现之一。尽管目前多智能体强化学习被越来越多的研究者所关注,针对合作型多智能体任务的相关研究也取得了突出的进展,但是如何让多智能体群体具备知识迁移的能力仍然是一个开放的问题。
本文工作
现有的多智能体策略迁移算法大多依赖神经网络的内在泛化能力,没有充分利用任务之间的关系来实现更高效的迁移。为了弥补这一不足,我们研究了不同多智能体任务之间相似结构的发现与利用,并提出了基于任务关系建模的多智能体迁移强化学习方法(MATTAR)。在这个学习框架中,我们通过建模不同任务之间转移和奖励函数的相似性来捕获任务的相似结构,如图1所示。具体而言,我们为所有源任务训练一个前向模型,用于预测给定当前观测、状态和动作时下一个时间步的观测、状态和奖励。工作的研究难点在于如何在这个前向模型中刻画不同任务的相似性和差异性,我们通过为每个源任务都提供一个独特的表征来引入差异,并通过一个共享的超网络(称为表征解释器)生成前向模型的参数,从而建模相似性。为了学习一个良好的表征空间来编码任务关系,我们提出了交替固定的训练方法,用于学习任务表征和表征解释器网络。在训练过程中,源任务表征被预定义并固定为相互正交的单位向量,通过优化所有源任务上的前向模型预测损失来学习表征解释器网络。当面对一个未见任务时,我们固定得到的表征解释器网络,优化新任务的前向模型损失并基于返回的梯度更新新任务表征。
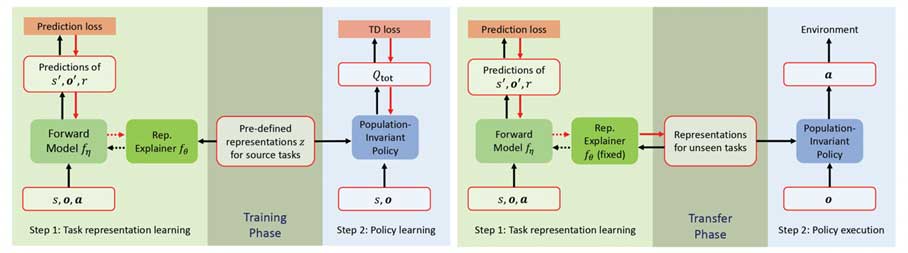
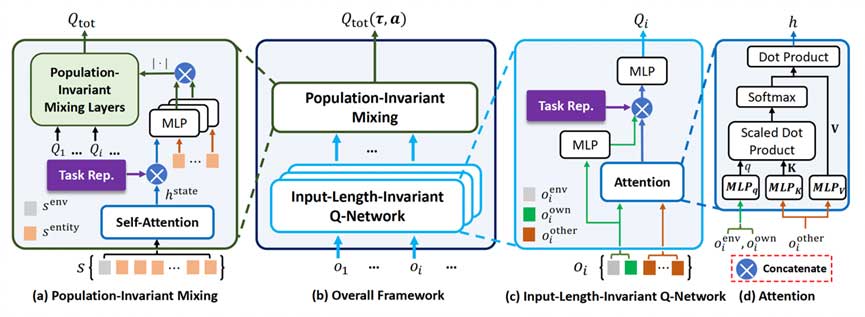
此外,我们设计了如图2的种群数量不变网络来处理不同多智能体任务之间观测、动作维度变化的问题。在策略训练过程中,我们固定所有源任务的任务表征,通过最大化所有源任务的预期回报来更新种群数量不变网络。到要迁移到未见任务时,我们将新的任务表征插入到已经训练好的种群数量不变网络来获得迁移策略。
本文的创新点如下:
(1)设计了一种智能体数量无关的值函数网络结构,其中包括个体值函数网络和混合网络模块,能够支持不同规模任务下的策略训练与部署。
(2)设计了一种有效的任务表征学习算法,该算法通过学习一个“表征解释器”网络构造表征向量与任务的环境转移模型以及奖赏函数之间的映射关系,并借助对环境前向模型(转移模型和奖赏函数)的学习实现对任务表征的学习过程。
(3)基于算法设计当中的智能体数量无关值函数网络以及任务表征学习算法,提出了一种从多个源任务到目标任务的多智能体迁移强化学习算法。该算法在面对目标任务时借助任务表征针对性地重用源任务的策略经验,从而实现新任务上高效的策略泛化或迁移。
实验结果
本文主要在如图3所示的星际争霸多智能体挑战测试环境中对本文设计的算法进行了实验验证,相关实验结果表明我们的算法在一系列测试任务中能够取得优于其他基线算法的策略泛化和策略迁移性能。

为了验证MATTAR算法对于辅助智能体群体在不同多智能体任务之间进行知识迁移的能力,我们在设计的三个系列的星际任务,包括Marine系列、sz系列和MMM系列任务上对算法的泛化性能进行了测试实验。具体而言,对于每个系列的星际任务,我们将其包含的若干具体任务划分为源任务集合和目标任务集合,对于不同的对比算法,我们首先让智能体策略在源任务集合上进行训练,训练完毕后我们固定训练阶段得到的智能体策略在目标任务上进行泛化测试,记录并比较不同算法的泛化性能结果,最终实验对比结果如表1,表2和表3所示。
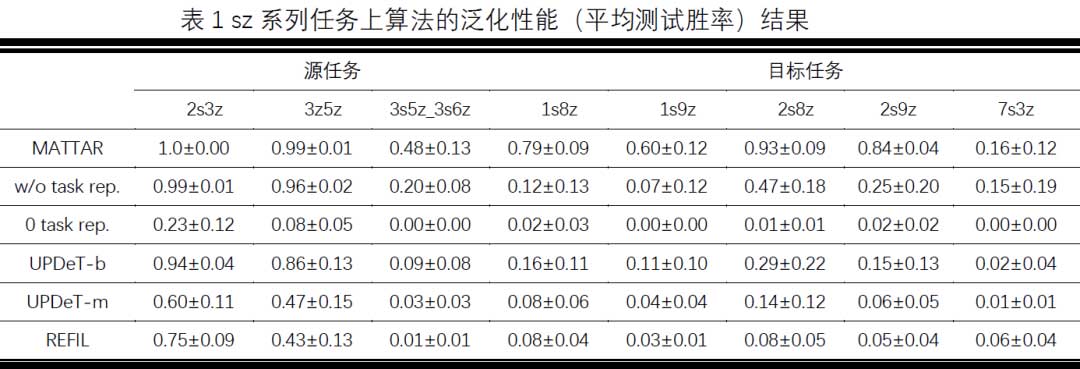
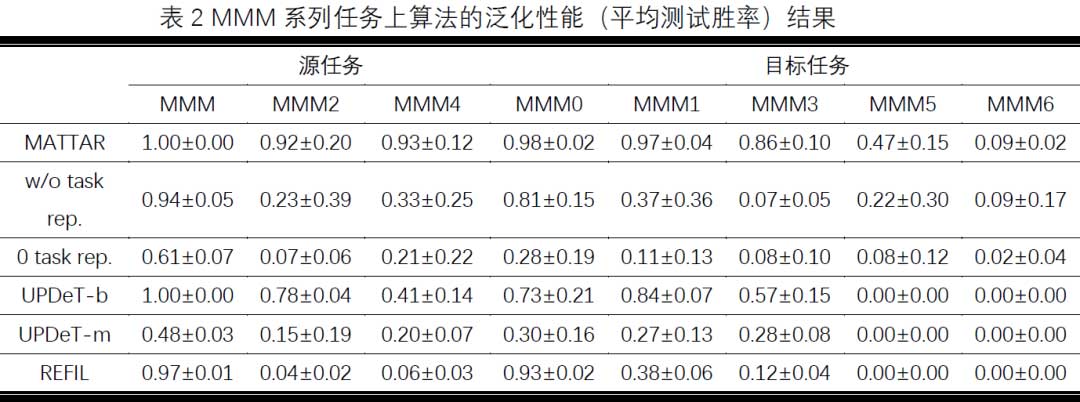
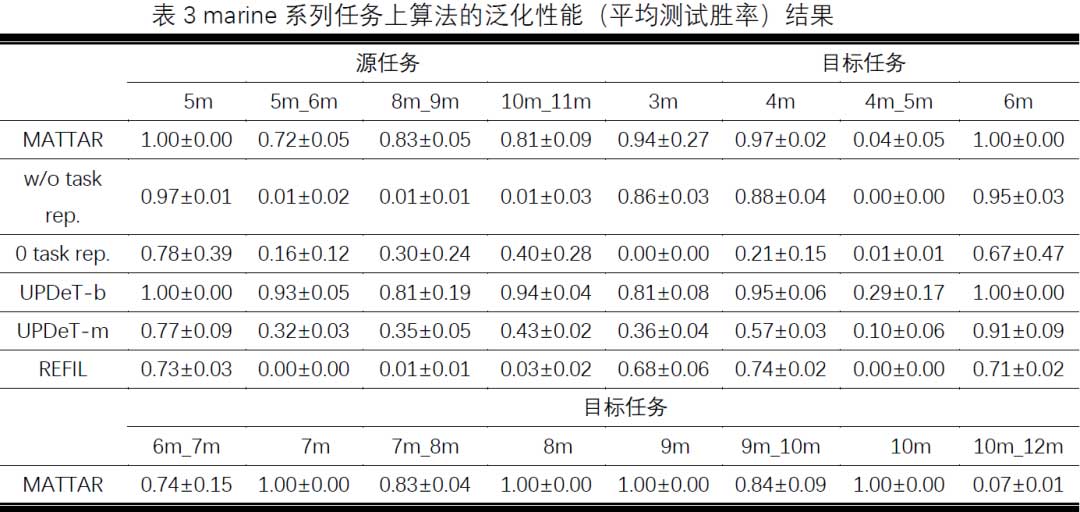
从目标任务上的泛化测试结果可以看到,MATTAR 算法在大部分任务当中取得了优于基线算法UPDeT-b、UPDeT-m和REFIL的泛化性能。尤其是在场景相对复杂、协作要求相对较高的sz系列和MMM系列任务当中,MATTAR算法表现出了更加显著的泛化性能优势。此外,额外对比了直接插入零向量作为任务表征的“0 task rep.”和完全去除任务表征模块的“w/o task rep.”来进行消融实验。从实验结果可以看出,MATTAR算法在几乎大部分任务场景当中都取得了优于两种消融算法的泛化性能,由此可以知道算法当中的任务表征学习模块能够有效地帮助算法捕捉任务之间的相关性,辅助智能体策略取得更好的泛化性能。
为进一步研究MATTAR算法是否能够为智能体策略在目标任务上的迁移学习带来额外的收益,我们让源任务上训练得到的智能体策略在目标任务上进行进一步的训练更新,将目标任务上策略迁移训练的结果与算法完全从零开始进行学习的结果进行对比,以此验证MATTAR算法是否能够为智能体策略在新任务上的迁移学习带来收益。为了体现实验结果的一般性,我们分别在Marine系列, sz系列和MMM系列的星际任务当中进行了策略迁移训练,相关实验结果如图4所示。
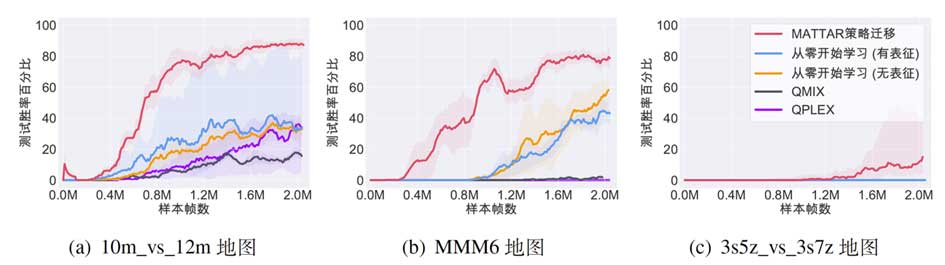
结果表明,相比于两种从零开始学习的对比算法,利用MATTAR算法进行策略迁移学习能够明显地加速智能体策略在新任务上的学习过程,并且帮助智能体策略在新任务上取得了更好的渐近性能。
出版信息
Rongjun QIN, Feng CHEN, Tonghan WANG, Lei YUAN, Xiaoran WU, Yipeng KANG, Zongzhang ZHANG, Chongjie ZHANG & Yang YU. Multi-Agent Policy Transfer via Task Relationship Modeling. Sci China Inf Sci, doi:10.1007/s11432-023-3862-1
原文:https://www.sciengine.com/SCIS/doi/10.1007/s11432-023-3862-1;JSESSIONID=173d3b0c-1ca2-4c31-a4f2-67c52de9456e
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
