
目前的工作主要基于话语的音频和文本生成共语手势,却忽略了说话者的非语言动作。为了解决这一问题,我们提出了FreeTalker框架,这是目前首个能生成自发(如共语手势)和非自发(如在讲台周围移动)说话者动作的系统。我们使用基于扩散的模型训练说话者动作生成,统一表示语音驱动手势和文本驱动运动,利用来自各种运动数据集的异构数据。实验证明我们的方法生成了自然且可控的说话者动作。
作者:Sicheng Yang 等
论文题目:Freetalker: Controllable Speech and Text-Driven Gesture Generation Based on Diffusion Models for Enhanced Speaker Naturalness
来源:ICASSP 2024
论文链接:https://arxiv.org/abs/2401.03476
内容整理:王怡闻
引言
在诸如虚拟代理、动画和人机交互等各种应用中,说话者的动作至关重要。这些动作主要可以分为两个部分:与口头内容紧密相连的共语手势,以及在演讲过程中展示的非自发动作。
然而,现有作品主要集中在共语手势的全局风格控制上,并未促进说话者的自由移动,例如在舞台上四处走动、指点或朝特定方向看,或者与观众互动。在演示和演讲中,这些方面是至关重要的。据我们所知,还没有一个旨在一体化这两个动作类别的努力。挑战来自不同的运动表示和多模态学习的复杂性。
在本文中,我们提出了一个新颖的框架,用于生成既自发又非自发的说话者动作。具体而言,我们首先开发了一个基于扩散的模型,用于说话者动作生成,利用了来自各种运动数据集的异构数据。然后,在推理过程中,我们采用了无分类器的引导,以实现在生成的片段中高度可控的风格。此外,我们采用了DoubleTake,用于在片段之间创建平滑的过渡并确保无缝的动作混合。我们工作的主要贡献包括:
- 提出了FreeTalker,据我们所知,这是第一个在多个数据集上训练的,用于生成既自发又非自发的说话者动作的框架。
- 在我们基于扩散的模型中引入了无分类器的引导和DoubleTake,以增强手势生成的灵活性和控制性。
- 通过大量实验证明,我们的方法在生成的说话者动作方面具有更高的自然度,超过了现有方法在动作质量方面的表现。
方法
数据处理
我们期望不同运动数据集的特征能够被正确保留。与 Ude 和 Unifiedgesture 不同,其中Ude用离散编码表示人体动作,而 Unifiedgesture 将人体运动重定向到由五个终端关节(头部、手和脚)组成的同态图,有可能丢失重要的详细信息,如肩膀和手指。我们的方法解决了这个问题并保留了运动的详细信息。我们首先将运动捕捉(BVH格式)数据的旋转矩阵转换为SMPL-X 的轴角表示。对于3D位置数据,我们使用 VPoser 将其拟合到 SMPL-X 表示。然后适当地缩放根关节的3D平移,并调整初始方向以在不同数据集之间保持一致,就像 Unifiedgesture 一样。通过 SMPL-X 模型的前向计算,我们可以获得 SMPL-X 表示的3D位置。我们使用根高度、根线性和旋转速度、关节旋转、关节位置、关节速度以及脚触地情况作为运动特征表示。
用于运动生成的扩散方法
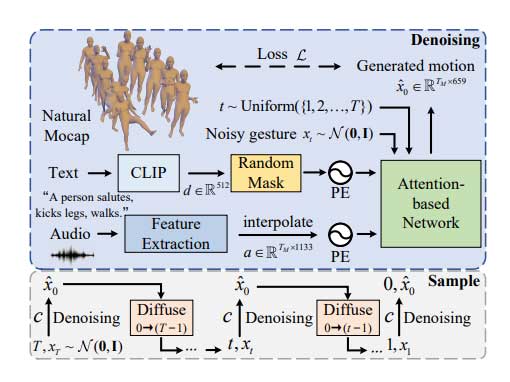
我们从原始音频中提取梅尔频谱、音调、能量、WavLM 、Onsets信息,同时将文本编码至 CLIP 空间。我们选择 self-attention 层作为去噪网络,在训练时使用HuberLoss:
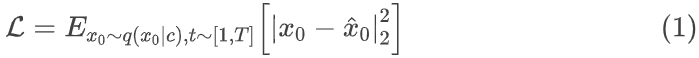
长动作生成
在生成非时间感知序列(例如文本到运动)的任务中,传统方法利用种子姿势效果不佳,因此我们借鉴了DoubleTake方法生成长距离运动。
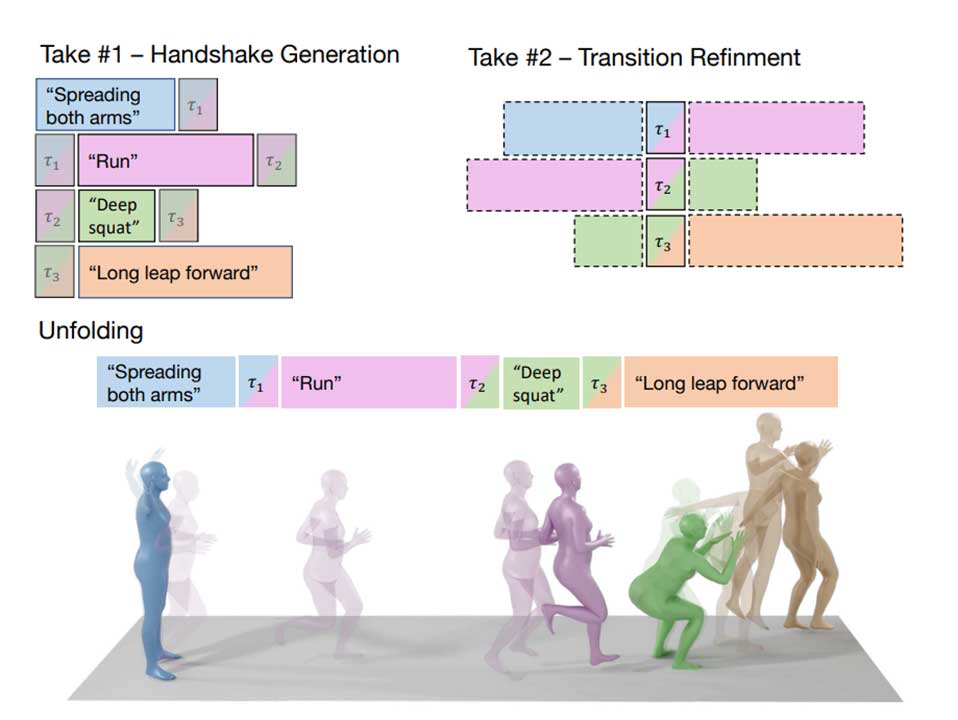
一个很直观的想法是:一个长序列动作的生成可以拆分为多个简短动作,然后将其融合,所以要在多段motion之间生成过渡,它分为两个阶段:首先在 mi-1 的后缀和 mi 的前缀逐帧加权平均,初步生成一个过渡的雏形。
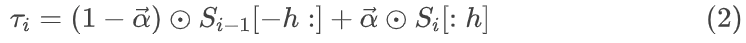

实验
数据集
HumanML3D : 用于基于文本的运动生成。
BEAT : 用于基于语音的手势生成。
实验结果
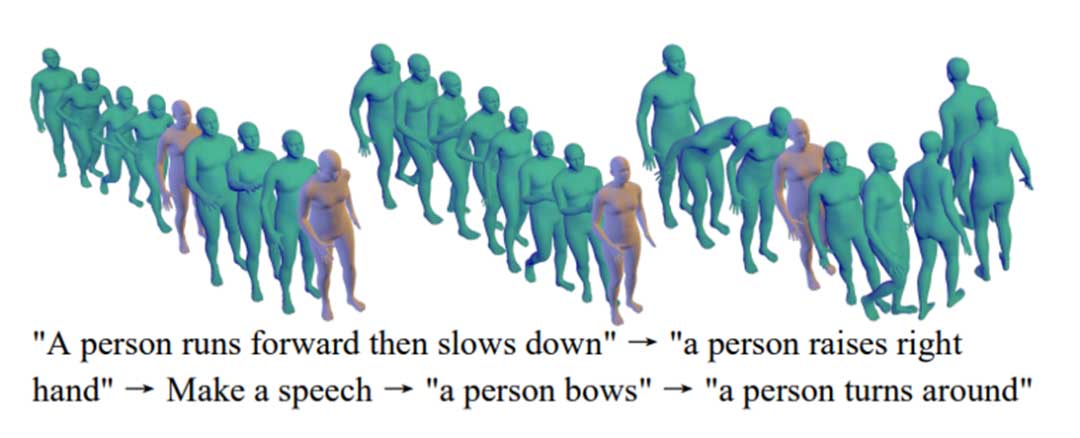
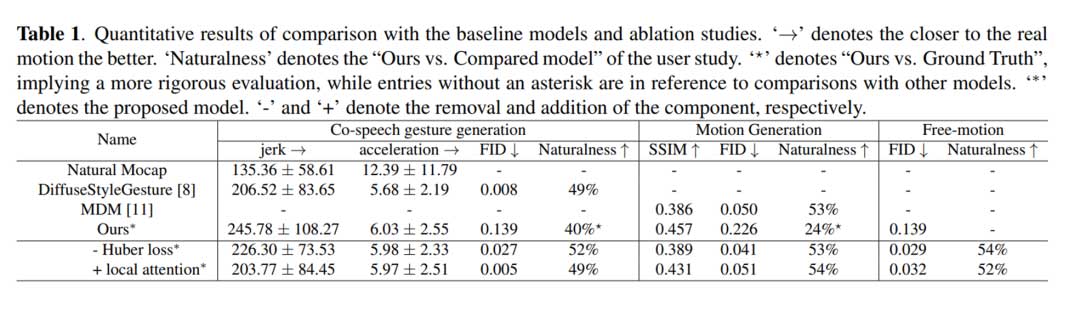
结论
在本文中,我们提出了FreeTalker,这是一个简单而有效的框架,用于生成既自发又非自发的说话者动作。利用基于扩散的模型,我们的方法在来自各种运动数据集的异构数据上进行训练。在推理阶段引入了无分类器引导和DoubleTake,确保了自然、高度可控和长程的运动生成。此外,我们的方法为未来在大规模运动数据集和更复杂模型上的工作奠定了基础,为说话者运动生成的进一步发展以及在各种应用中提升语音化身自然度铺平了道路。
我们打算进一步深入研究将我们的工作扩展到完全数字化人类的生成,包括运动、面部表情和嘴唇运动。我们还计划探索更统一的数字化人类生成方法。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
