
在本文中,作者主要研究可泛化的神经渲染任务,该任务从不同人物的多视图视频中训练条件神经辐射场 (NeRF)。为了处理动态人体运动,以往的方法主要采用基于SparseConvNet (SPC)的人体表示来处理绘制的SMPL。然而,这种基于SPC 的表示在挥发性观察空间下进行优化,这导致训练和推理阶段之间的姿势错位,以及 而且缺乏处理不完整绘制的 SMPL 至关重要的人类部分之间的全局关系。为了解决这些问题,作者提出了一个名为 TransHuman 的全新的框架,该框架在规范空间中学习绘制的 SMPL,并用 Transformer 捕获人体部位之间的全局关系。具体来说,TransHuman主要由基于Transformer的人体编码(TransHE)、可变形部分辐射场(DPaRF)和细粒度细节集成(FDI)组成。TransHE首先通过Transformer在规范空间下处理绘制的SMPL,以捕获人体部位之间的全局关系。然后,DPARF将每个输出token与可变形辐射场相结合,用于对观察空间下的查询点进行编码。最后,利用FDI进一步整合参考图像的细粒度信息。
来源:Arxiv
题目:TransHuman: A Transformer-based Human Representation for Generalizable Neural Human Rendering
作者:Xiao Pan,Zongxin Yang,Jianxin Ma,Chang Zhou,Yi Yang
论文链接:https://arxiv.org/abs/2307.12291
内容整理:桂文煊
介绍
高保真地渲染动态人类表演者的自由视点视频对于许多混合现实、游戏等应用至关重要。
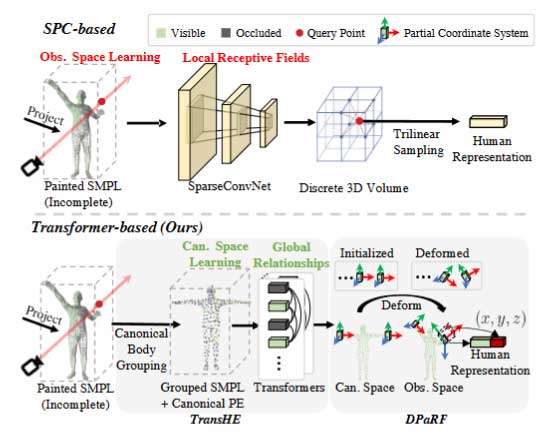
如图1所示,之前对于解决该问题的方法主要利用稀疏卷积(SparseConvNet,SPC)来得到人体表征。该方法主要有两个问题:
- 多变的输入姿势问题。基于 SPC 的方法在包含不同姿势的观察空间下进行了优化,也就是说其输入的姿势会随着帧数的变化而变化,这导致训练和推理阶段的姿势错位,从而限制了泛化能力。
- 有限的局部感受野。如图1所示,由于动态人体的自遮挡较大,绘制的SMPL模板通常不完整。虽然作为 3D 卷积网络,但 SPC 的有限局部感受野使其对不完整的输入敏感,尤其是当遮挡区域很大时。
受此启发,作者提出了 TransHuman,TransHuman主要由基于Transformer的人体编码(TransHE)、可变形部分辐射场(DPaRF)和细粒度细节集成(FDI)组成。(i) TransHE。TransHE使用Transformer在规范空间下处理绘制的SMPL。该pipeline的核心包括一个用于避免语义歧义的规范体分组策略,以及一个规范学习方案来简化全局关系的学习。(ii) DPaRF。DPaRF 将 TransHE 的输出标记从规范空间变形到观察空间,并从行进光线中获得查询点的确定人类表示。如图1所示,主要思想是将每个token(代表某一人体部位)与部分坐标系变形为位姿变化的辐射场绑定,查询点通过变形部分坐标系下的坐标进行编码。(iii) FDI。使用 TransHE 和 DPaRF,人类表示包含具有人类先验的粗略信息,但直接从观察空间中捕获的细粒度细节有限。在人体表示的指导下进一步整合像素对齐特征的详细信息。
方法
pipeline
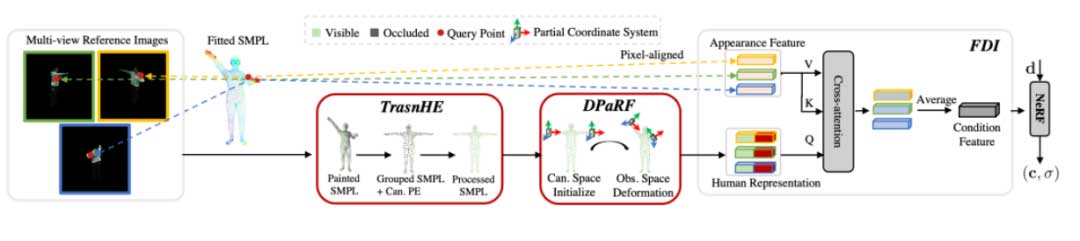
TransHuman的pipeline如下图所示。整个pipeline可以为:TransHE首先用于在规范空间下通过Transformer捕获人体部位之间的全局关系。然后,DPARF将坐标系从规范变形回观察空间,并将查询点编码为坐标和条件特征的聚合。最后,FDI在人体表示的指导下,进一步从像素对齐的外观特征中收集观测空间的细粒度信息。
Transformer-based Human Encoding(TransHE)
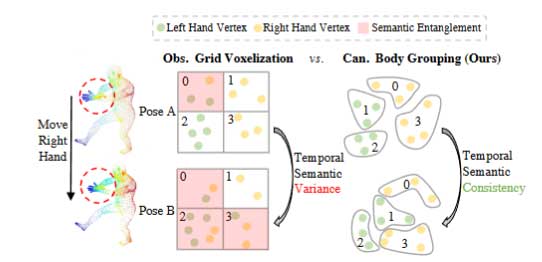
TransHE模块的输入是Painted SMPL。一种直接的做法是将6890个Token输入Transformer(本文使用ViT-Tiny),然而这种做法会带来巨大的计算开销,而且会引入细粒度误差(Fitted SMPL只是人体的粗略模版而不包含衣物等细节,因此其着色本身也存在一定的误差)。解决这两个问题只需要降低输入Transformer的Token数量。一种非常直接的想法是对Painted SMPL进行体素化,即将空间均匀划分为一个个小方块,在同一个方块内的顶点取平均算做一个Token,同时把方块中心作为Token对应的PE。但由于Painted SMPL是在观察姿势下的,观察空间下的朴素网格体素化会导致空间语义纠缠和时间语义方差问题。为了进一步解决这个问题,作者提出先对标准姿势SMPL(本文使用T-pose)进行K-Means聚类(本文默认聚300类)得到一个分组的字典。然后用该字典对Painted SMPL进行划分,同一类的特征取均值作为Token,同时将标准姿势SMPL下的聚类中心作为 PE 输入 ViT。这样在训练时在同一聚类中的特征可以通过平均池化聚合。
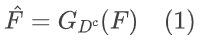
Deformable Partial Radiance Fields(DPaRF)

Fine-grained Detail Integration(FDI)与渲染
通过TransHE和DPaRF两个模块, 已经得到了给定查询点的人体表征,该表征包含了粗粒度的人体几何先验信息。接下来,使用一个Cross-attention模块,将粗粒度的人体表征视作Q,细粒度的表面特征视为K和V,得到最终的条件特征送入最后的NeRF中。
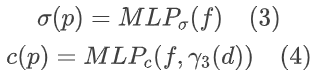
实验及结果
作者实验采用了ZJU-MoCap和H36M两个数据集,结果如图4所示。
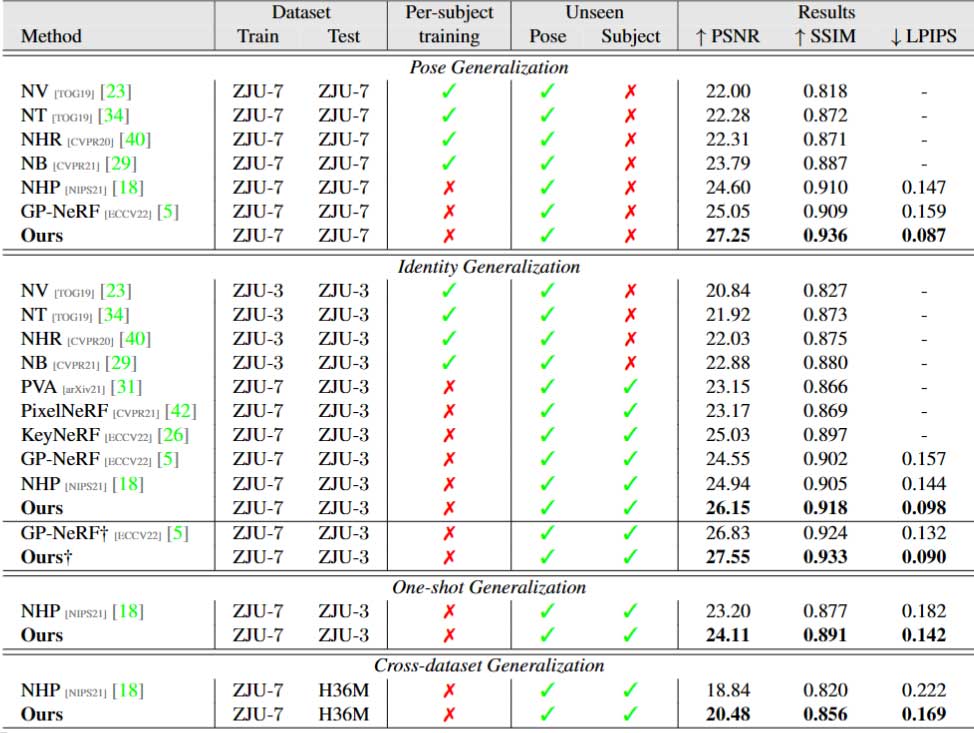
结果证明在Pose的泛化、Identity的泛化、单张参考图的泛化以及跨数据集的泛化上作者的方法表现均是最好的。除此之外,作者对该方法的推理效率进行了测试,结果如图5所示。
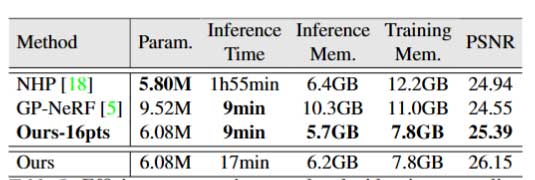
结果证明该方法能利用更小的内存实现更快的推理速度,证明本文的方法效率要优于其他方法。
小结
本文为可泛化人体重建领域引入了一种新的基于Transformer的人体表征。该表征在人体部件之间构建了全局关系,并将优化统一在了标准姿势下。其泛化性能明显优于先前的基于稀疏卷积的表征,而且具有比较高的推理效率,为后续可泛化人体重建的研究提供了一个新的更高效的模块。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
