
简介:准确感知现实世界中的三维物体的几何和语义属性对于增强现实和机器人应用的持续发展至关重要。为此,本方法提出了嵌入基础模型的高斯溅射(Foundation Model Embedded Gaussian Splatting,简称FMGS),将基础模型的视觉-语言嵌入引入到高斯溅射(Gaussian Splatting,简称GS)中。这项工作的关键贡献在于提出了一种高效的方法来重建和表示三维视觉-语言模型。这是通过将基于图像的基础模型生成的特征图潜入三维特征实现的。为了确保高质量的渲染和快速的训练,本文作者引入了一种全新的场景表示方法,将GS和多分辨率哈希编码(MHE)的优势结合在一起。为了让训练过程更有效还引入了像素对齐损失,使相同语义实体的渲染特征距离接近,遵循像素级语义边界。本方法结果展示了出色的多视图语义一致性,有助于各种下游任务,并在开放词汇语言对象检测达到SOTA,推理速度快了85.1%。
来源:Arxiv
论文题目:Foundation Model Embedded Gaussian Splatting
论文地址:https://arxiv.org/abs/2401.01970
作者:Xingxing Zuo, Pouya Samangouei, Yunwen Zhou, Yan Di, Mingyang Li
内容整理:陈梓煜
介绍
3D场景理解是计算机视觉和机器人应用中的重要任务。然而,大多数现有方法主要集中在3D几何和外观估计或基于封闭类别数据集的3D对象检测和场景分割上。然而,为了使智能代理能够与物理世界平稳互动,仅仅理解由预先识别的标签特征化的空间子集是不足够的。受最新的基础模型在语言和视觉语义方面取得的进展所启发,本方法旨在开发更自然的3D场景表示。它整合了几何和开放词汇语义信息,便于后续任务中用语言查询。
在本文中,我们使用高斯溅射作为重建3D几何和外观的表征,它在新视角图像合成和训练效率方面表现出色。为了帮助开放词汇的3D场景理解,我们依赖于预训练的2D视觉语言CLIP,并通过全新的多视图训练过程将相应信息提升到3D。与本工作接近的是LERF,它整合了基于隐式NERF的场景表示和CLIP嵌入。与LERF相比,我们的系统采用了不同的架构,提供了各种技术贡献,从高效性到3D一致查询,取得了更好的结果(在关键性能指标上约为10.2%)。
提升3D高斯与视觉语言FM嵌入的直接方法是将每个高斯与一个可学习的特征向量相连,可以通过图像光栅化训练以制定损失函数。然而,通常情况下,要在标准尺度的环境中保持高质量的渲染,通常需要数百万个高斯。每个高斯都具有特征向量将导致过多的内存消耗,并且显著减慢训练速度,限制了该系统的实际应用。受iNGP的启发,我们使用3D高斯溅射与多分辨率哈希编码(MHE)来提炼基础模型嵌入。具体来说,为了从高斯中获取语言嵌入,我们利用它们的均值来查询相应位置的MHE字段。随后,通过多层感知器(MLP)处理这个查询的MHE以生成输出的语言嵌入。
这项研究为增强现实体验和基于语言命令导航和操作环境的机器人系统等现实世界应用铺平了道路。通过缩小语言和3D表示之间的差距,FMGS为我们理解和与周围环境互动的新可能性打开了大门。
我们的贡献可以总结如下:
- 全新的语义场景表示:我们引入了一种全新的方法,将3D高斯溅射用于几何和外观表示,同时使用MHE进行高效的语言嵌入。这种方法解决了包括数百万3D高斯在内的标准尺度场景中的内存约束问题。
- 多视一致的语言嵌入:我们的训练过程利用了基于高斯溅射的多视角渲染,确保在时间和空间上的一致性。语言嵌入对视点保持不变,强制在高斯内保持局部一致性。
- 解决像素错位问题:我们通过提取和聚合多分辨率的CLIP特征来解决CLIP特征的像素对齐问题,用于监督训练。使用像素对齐的DINO特征和点积相似性损失来增强空间精度和对象区分度。
- 性能优势:尽管速度快了数百倍,我们的方法在开放词汇语义对象定位方面表现SOTA的性能。
方法
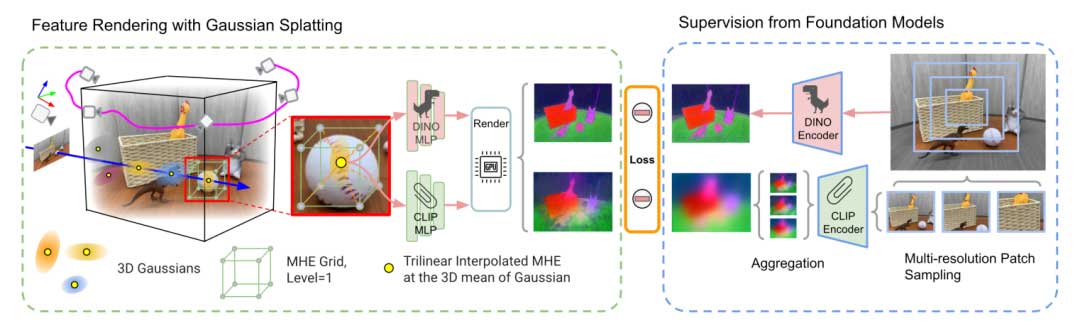
本节简要介绍FMGS的相关方法,充分发挥了GS和MHE的优势。我们依赖GS来进行高效且准确的场景几何表示,同时依赖MHE以轻量级的方式表示场景的语言内容。给定一组输入图像,我们使用COLMAP计算它们的相机姿态和3D稀疏视觉点。然后,我们训练GS并获取3D高斯表征。
随后,我们通过基于2D CLIP嵌入的方法来训练3D中的特征嵌入场(MHE)。这要求我们在一组校准的输入图像上生成像素对齐的特征。然而,CLIP嵌入是全局性质的,不适合像素对齐的特征提取。为了克服这一挑战,我们引入了一个框架,学习一个嵌入到3D高斯上的体积语言嵌入场。该场有效的生成特征,即包括该3D高斯的所有视图的平均CLIP特征。为了监督我们的密集特征场,我们创建了一个基于多尺度裁剪训练视图的CLIP嵌入的混合特征图。图1展示了整个训练管线。
特征场架构
3D高斯产生了数百万个高斯,以实现对房间尺度场景的高质量渲染。这使得每个高斯都有一个CLIP特征非常低效,因为这些特征具有高维度,将所有这些特征保留在GPU内存中是不可行的。
因此,我们使用MHE有效地对特征场进行参数化。对于给定的具有均值位置 𝐱 的 3D 高斯,我们首先将 𝐱 编码为特征向量 𝐪=𝐞(𝐱),其中 𝐞 是我们的多分辨率哈希表参数。然后,我们将这个输出馈送到一个 MLP,生成我们的语言嵌入𝐟 = Φ(q),其中 𝐟 属于 Rd。我们还对 𝐟 进行归一化,使其成为一个单位向量。
嵌入基础模型

混合CLIP特征用于监督
为了监督我们的特征场输出,在给定校准的输入图像时,我们首先将特征栅格化成一个2D特征图,其中第(i,j)个特征是通过基于点的α-混合获得的。
为了生成我们的目标 CLIP 特征图,记为 𝐅,我们首先预先计算 CLIP 嵌入的多尺度特征金字塔,类似于 LERF 中使用的方法。这涉及将各种尺寸的图像块输入到 CLIP 基础模型中。然而,与 LERF 不同,它通过随机尺度插值来训练其场景表示的预计算 CLIP 特征金字塔中的嵌入,我们只依赖一个用于训练我们场景表示的单一混合 CLIP 特征图。我们将较小尺度的预先计算的 CLIP 特征金字塔中的嵌入通过双线性插值缩放到最大尺度的特征图,并通过对它们进行平均来生成混合特征图。
正如在图 2 中使用 PCA 可视化特征图所示,当考虑到相邻像素的嵌入相似性时,目标 CLIP 特征图不足够精细。这导致在不相关语义上的高斯上出现了较差的像素对齐梯度信号。另一方面,DINO 特征在嵌入相似性方面在对象之间产生了清晰的边界,可以用于额外的正则化。

使用DINO特征进行正则化
为了在保持 CLIP 嵌入语义的特性的同时传输DINO特征的特点,我们:(a)添加了一个 DINO 特征场损失;(b)定义了 DINO 和 CLIP 特征场之间的像素对齐损失。DINO 特征场使用与 CLIP 相同的哈希网格参数,并为给定 𝐱 输出 𝐪。然后 DINO 特征场输出 𝐝=Φ(𝐪),其中 Φ 表示 MLP 的参数,它与 𝐞 不共享。通过将 𝐝 一次传递给预训练的 DINO 模型,但不进行缩放,得到 𝐃 ϵ Rw x h x d,其中 w 是 DINO 特征的维度。然后,我们使用与渲染 𝐅 相同的方法来渲染 𝐃。
基于点积相似性的像素对齐
我们通过在每个像素周围定义一个核心,强制在规范化嵌入空间中(DINO 和 CLIP 之间)的点积相似性在中心像素和周围像素之间保持一致来定义像素对齐损失。我们将渲染的特征都归一化为单位范数,然后计算损失。
实验
FMGS 无缝地集成了3D 高斯和多分辨率哈希编码,支持逼真的渲染和开放式词汇的物体检测。本文提供了FMGS 在不受控制的现实世界场景中的开放式词汇物体检测(或定位)性能,如表 1 所示。
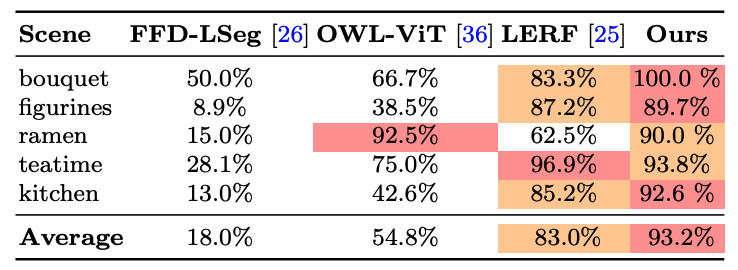
图 3 展示了其可视化结果。

为了展示 FMGS 的嵌入质量,本文作者还在开放式词汇语义分割任务上对其进行了即时评估。将 FMGS 与其他最先进的方法进行了比较,并展示了相对于它们的显著改进结果,如表 2 所示。

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
