
研究问题:系统和网络社区的传统观点是拥塞主要发生在网络结构内。然而,高带宽访问链路的采用和主机内资源相对停滞的技术趋势导致了主机拥塞的出现,即支持 NIC 和 CPU/内存之间数据交换的主机网络内的拥塞。这种主机拥塞改变了数十年来拥塞控制研究和实践中根深蒂固的许多假设。
题目:Host Congestion Control
来源:SIGCOMM2023
链接:https://dl.acm.org/doi/abs/10.1145/3603269.3604878
作者:Saksham Agarwal, Arvind Krishnamurthy, Rachit Agarwal Authors Info & Claims等人
github:https://github.com/Terabit-Ethernet/hostCC
内容整理:胡玥麟
任务
提出了 hostCC,一种拥塞控制架构,用于处理主机和网络结构拥塞。HostCC 体现了三个关键思想。首先,除了源自网络结构的拥塞信号之外,hostCC 还收集主机拥塞信号,以捕获主机拥塞的精确时间、位置和原因。其次,hostCC 引入了亚 RTT 粒度主机本地拥塞响应,该响应使用拥塞信号在网络流量和主机本地流量之间分配主机资源。最后,hostCC 使用主机和网络拥塞信号以 RTT 粒度分配网络资源。
动机
数据中心拥塞控制的经典文献采用狭隘的“端到端”观点,通常将末端解释为以太网(网络接口卡或 NIC)的存在点。这种观点排除了每个数据中心服务器都拥有的网络——主机网络,即由处理器、内存和外围互连组成的网络,使得CPU、内存和外围设备之间能够交换数据。主机网络提供了许多理想的特性——极小的故障和数据包损坏概率、充足的带宽和无损保证;因此,系统和网络社区的传统观点是拥塞主要发生在网络结构内(即网络交换机处)。
最近对大规模生产集群的几项研究表明,上述传统观点仅仅是对传统谬误的诉求:采用高带宽接入链路,加上主机内资源相对停滞的技术趋势—— CPU 速度、缓存大小、内存访问延迟、每个核心的内存带宽、NIC 缓冲区大小等导致了主机拥塞的出现,即主机网络的处理器、内存和外设互连内的拥塞。
贡献
在 Linux 网络堆栈中实现了 hostCC。hostCC 实施不需要对应用程序、主机硬件和/或网络硬件进行修改;此外,它可以与现有的拥塞控制协议集成,以处理主机和网络结构拥塞。对使用和不使用 hostCC 的 Linux DCTCP 的评估表明,在存在主机拥塞的情况下,hostCC 显着减少了主机上的排队和数据包丢失,从而提高了网络应用程序在吞吐量和尾部延迟方面的性能。
挑战
主机拥塞状况迫使我们重新审视几十年来拥塞控制研究和实践中根深蒂固的许多基本假设。
论文方法
提出了 hostCC,这是一种采用最终端到端视图的拥塞控制架构:它通过在竞争流量之间分配主机和网络资源来处理主机拥塞和网络结构拥塞。主机和网络资源分配的精神是驱动hostCC 中体现的三个关键技术思想的核心。首先,除了来自网络结构内部的拥塞信号之外,hostCC 还在处理器、内存和外设互连处以亚微秒的时间尺度生成主机本地拥塞信号。这些主机拥塞信号使hostCC能够精确捕获主机拥塞的时间、位置和原因。HostCC 中的第二个关键技术思想是亚 RTT 粒度主机本地拥塞响应:在发送方和接收方,hostCC 使用主机本地拥塞信号在网络流量和主机本地流量之间分配主机资源。在发送方,hostCC 使用主机本地拥塞响应来确保网络流量不会匮乏,即使是在亚 RTT 粒度下;在接收器处,hostCC 使用主机本地拥塞响应来最大程度地减少主机上的排队和数据包丢失:它以亚 RTT 粒度调节分配给网络流量的主机资源,以确保 NIC 队列以与网络流量相同的速率耗尽到达网卡。最后,hostCC 的第三个关键技术思想是使用主机和网络拥塞信号在 RTT 时间尺度上执行高效的网络资源分配。
hostCC 允许在现有主机网络堆栈中高效实现,无需对应用程序、主机硬件或网络硬件进行任何修改;此外,hostCC可以与现有的拥塞控制协议集成,以有效地处理主机和网络结构拥塞。为了证明这一点,我们使用 ~800LOC 在 Linux 内核中执行 hostCC 的端到端实现,并与未经修改的 Linux DCTCP 一起对其进行评估。我们的评估表明,在存在主机拥塞的情况下,hostCC 将主机上的排队和数据包丢失减少到最低限度,从而网络应用程序带来近乎最佳的网络利用率和尾部延迟。
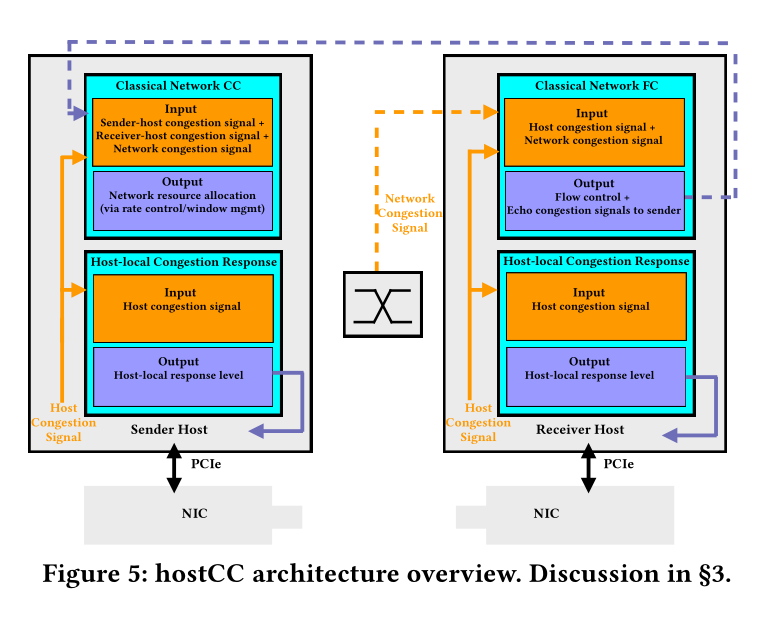
上图说明了端到端 HostCC 架构。该架构中体现三个关键技术思想——主机拥塞信号、主机本地拥塞响应和网络资源分配。
主机拥塞信号
hostCC 使用 IIO 缓冲区占用率作为拥塞信号。使用 IIO 占用作为主机拥塞信号的好处如下所示。
- 首先,IIO 占用率提供有关主机拥塞的时间、位置和原因的准确信息:IIO 占用率在内存控制器变得拥塞时立即增加(时间和位置的准确性),并且仅在内存控制器拥塞时才会增加(原因的准确性)。
- 其次,IIO 占用率可以与另一个统计数据(IIO 插入率,定义为 PCIe 将数据插入 IIO 缓冲区的速率)相结合,以测量各种其他有用的指标;例如,瞬时 PCIe 吞吐量(捕获 NIC 缓冲区耗尽的速率)等于瞬时 IIO 插入速率乘以缓存行大小,IIO 占用率和 IIO 插入率可以使用通常可用的两个寄存器来测量商用硬件,允许 hostCC 无需任何硬件修改/支持即可工作。
- 最后,IIO 测量是在 NIC 到内存数据路径之外的处理器互连处完成的;
- 因此,IIO 占用测量不受主机拥塞的影响。
亚 RTT 粒度的主机本地拥塞响应
经典拥塞控制协议的概念解释是,为了处理网络内的拥塞,这些协议(以及网络交换机)在拥塞点竞争的实体之间分配网络资源。HostCC 架构中的第二个关键技术思想是受此概念观点启发的:为了处理主机和网络拥塞,hostCC 在拥塞点竞争的实体之间分配主机和网络资源。为了实现这一点,hostCC 在发送方和接收方主机上引入了主机本地拥塞响应,该响应使用上一小节中讨论的主机拥塞信号来跨网络流量和主机本地流量分配主机资源。
资源分配取决于底层政策;hostCC架构并不规定精确的资源分配策略——就像不同的网络资源分配机制使用不同的网络分配策略(最大-最小公平性、加权最大-最小公平性、优先级等),我们设想hostCC体现各种主机资源分配政策和各自的实施。拥塞响应机制以每个数据包为基础进行操作,并决定是否增加或减少对网络流量和主机本地流量的资源分配。
如下图所示,hostCC 的主机本地拥塞响应机制最好用四种可能的操作机制来描述。
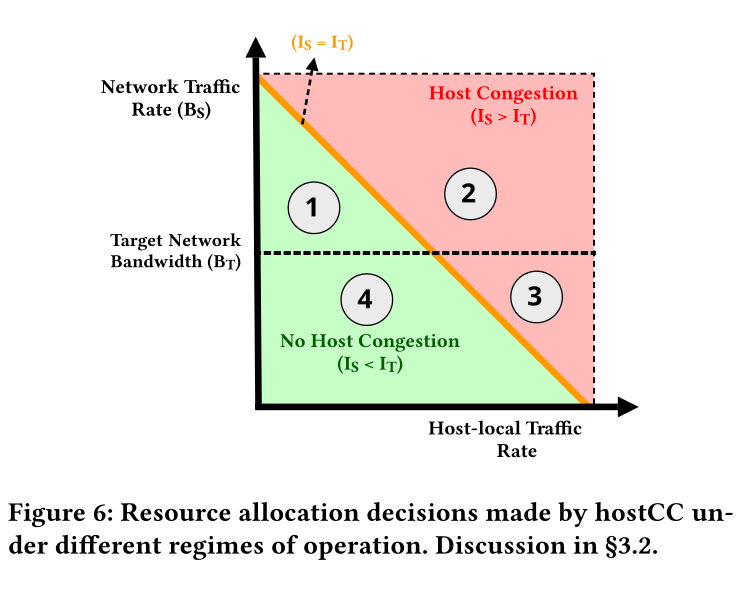
主机无拥塞,网络流量已满足目标网络带宽
在此状态下,主机不拥塞,并且网络流量使用的资源多于满足目标带宽所需的资源。因此,主机本地拥塞响应机制增加了分配给主机本地流量的资源。这是正确的,因为在没有主机拥塞的情况下,可以将更多主机资源分配给网络流量或主机本地流量;此外,由于网络流量已经满足目标网络带宽,我们希望确保主机本地流量不会出现不必要的背压。因此,主机本地拥塞响应机制增加了分配给主机本地流量的资源。主机本地流量可能不需要额外的资源;hostCC 通过依赖网络拥塞控制协议中使用的 AIMD 式机制来处理这种情况 – 由于主机不拥塞,因此网络流量不会在主机处标记拥塞信号,从而允许网络流量提高其速率并获取未使用的主机资源(如果网络结构不拥塞)。
主机拥塞,网络流量已达到目标网络带宽
在这种情况下,主机拥塞,网络流量使用的资源多于满足目标带宽所需的资源。因此,在这种情况下,正确的操作是减少分配给网络流量的资源,而不减少分配给主机本地流量的资源。为了实现这一点,hostCC 再次依赖于网络拥塞控制协议中使用的 AIMD 式机制:它将主机拥塞信号回显给网络拥塞控制协议,从而降低网络流量速率。
主机拥塞,网络流量未达到目标网络带宽
在这种情况下,主机拥塞,但分配给网络流量的资源少于满足目标带宽所需的资源。由于存在主机拥塞,我们必须减少分配的资源;由于网络流量未达到目标带宽,hostCC 首先减少分配给主机本地流量的资源。
如果没有任何明确的拥塞信号,网络流量将没有理由减少 R,从而导致 NIC 处的排队情况越来越多,并最终导致数据包丢失。为了避免这种情况,主机本地拥塞响应还将主机拥塞信号回显给网络拥塞控制协议,从而导致网络流量速率降低。我们注意到,如果 R < 퐵푇 ,则主机本地拥塞响应可能会导致资源分配效率低下,因为减少了分配给网络和主机本地流量的资源;然而,hostCC 暂时采取上述保护决策,以最大程度地减少 NIC 缓冲区堆积和数据包丢失。
无主机拥塞,网络流量未达到目标网络带宽
在这种情况下,主机不会拥塞,并且网络流量的资源少于满足目标带宽所需的资源。因此,主机本地拥塞响应为网络流量分配更多资源;这种分配再次是隐式的,因为它再次依赖于 AIMD 风格的机制 – 由于主机不拥塞,网络流量不会在主机上被标记为拥塞信号,从而允许网络流量提高其速率并获取未使用的主机资源(如果网络结构不拥塞)。隐式增加分配给网络流量的资源可能需要多个 RTT,或者甚至可能不可行(例如,由于网络拥塞);然而,主机本地拥塞响应做出保护决定,在此机制中不增加分配给主机本地流量的资源,以避免在达到目标网络带宽之前发生主机拥塞。
hostCC 中的主机本地拥塞响应使用主机拥塞信号并且纯粹是主机本地的;因此,它可以在亚 RTT 粒度上完成。
因此,即使主机本地流量以亚 RTT 粒度发生变化,主机本地拥塞响应也可以确保高主机资源利用率,同时根据任何给定策略维持目标网络带宽。
实验设计与验证
评估 hostCC 性能的目标有三个:
- 了解hostCC 核心思想(主机拥塞信号、主机本地拥塞响应以及使用主机和网络拥塞信号执行网络资源分配)对应用程序级性能的好处;
- 深入研究主机拥塞机制中的hostCC微观行为(捕获主机拥塞信号、主机本地拥塞响应和网络资源分配);
- 为主机拥塞机制制定经验教训,这对于设计未来的主机硬件和网络堆栈非常有用,可以更好地响应主机拥塞。
hostCC 的好处
hostCC 避免网络流量吞吐量下降,同时将主机处的数据包丢失减少几个数量级。
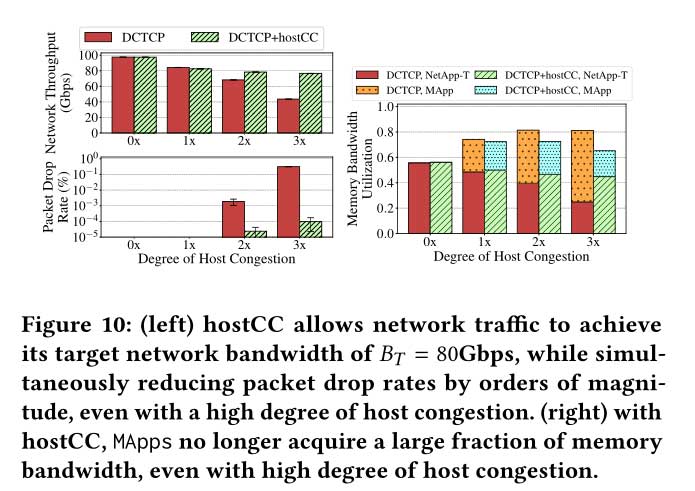
上图显示,当主机拥塞程度如此之低以至于 NetApp-T 可以达到其目标网络带宽而不会在主机网络内产生瓶颈(0× 和 1× 情况)时,hostCC 对 NetApp 的影响可以忽略不计。T 吞吐量(对于 0× 情况是带宽瓶颈,对于 1× 情况是 CPU 瓶颈)。更有趣的是,在存在主机拥塞的情况下,即使主机拥塞程度很高,hostCC 也能让 NetApp-T 实现接近所需目标网络带宽(本实验中为 80Gbps)的吞吐量。此外,上图(右)显示 NetApp-T 的这些优势不会以 MApp 流量不足为代价:每当 NetApp-T 能够维持目标时,hostCC 的主机本地拥塞响应也会增加分配给 MApp 流量的资源网络带宽。上图(左)还显示,hostCC 将数据包丢失率降至最低,因为主机本地拥塞响应和网络 CC(使用主机拥塞信号)协同工作,以在较长时间内保持 NIC 缓冲区占用率较低。
我们观察到,在主机拥塞程度较高的情况下,总内存带宽利用率略有下降。我们认为这种行为不是由于 hostCC 的架构造成的,而是由于使用现有工具(在本例中为英特尔 MBA)的主机资源分配的粗粒度造成的。由于分配的粒度如此之粗,MApp 有时会受到比其需要更多的背压,以便容纳额外的 NetApp-T 流量。图 9 显示了此行为的示例:当我们从主机本地响应级别 3 切换到 4 时,NetApp-T 获得 5.2GBps 的内存带宽,而 MApp 损失 13.8GBps 的内存带宽。我们在第 6 节中讨论了未来硬件支持改善主机本地拥塞响应的潜在途径。
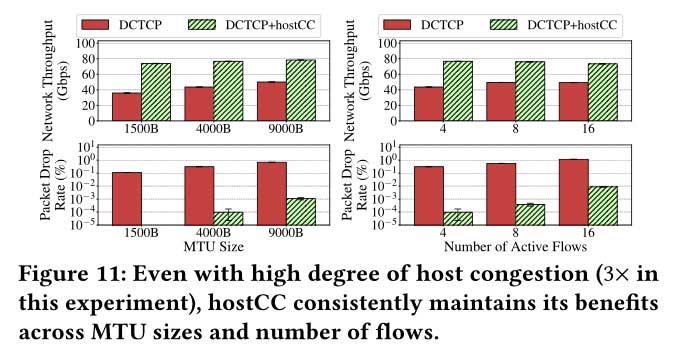
下图显示,在所有评估的 MTU 大小和流数量中,hostCC 在维持目标网络带宽和降低数据包丢失率方面始终取得了优势。
即使主机拥塞程度很高,hostCC 也能观察到延迟敏感流量的尾部延迟膨胀最小
hostCC 在主机拥塞情况下观察到最小的延迟膨胀,原因有两个:
- (1)hostCC 的主机本地拥塞响应确保主机的最小排队延迟;
- (2) hostCC 显着降低丢包率,避免重传和超时延迟。
即使存在主机和网络拥塞,hostCC 也能保持其优势
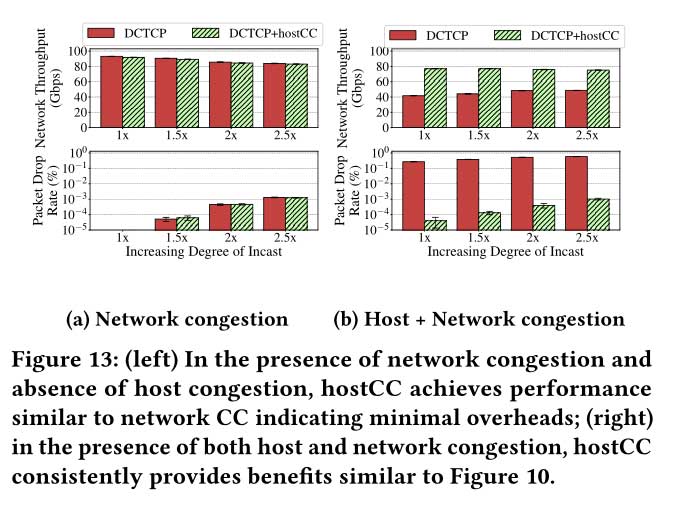
上图评估了存在网络拥塞(有或没有主机拥塞)的情况下的 hostCC 性能。在本实验中,我们使用具有两个发送器和一个接收器的 Incast 工作负载,直接连接到交换机。我们通过将 incast 程度(接收器处的活动并发流总数)从 4 更改为 10(1× 到 2.5× incast 程度)来改变网络拥塞程度。我们观察到,在没有主机拥塞的情况下,没有主机CC的网络CC观察到数据包丢失率随着网络拥塞程度的增加而增加(正如人们所期望的那样);由于不存在主机拥塞,因此 hostCC 性能与网络 CC 性能几乎相同,这表明在不存在主机拥塞的情况下,hostCC 的开销最小。然而,在主机和网络都存在拥塞的情况下,没有 HostCC 的网络 CC 性能会受到高丢包率和吞吐量降低的影响;在这种情况下,hostCC 使用其所有三个核心思想提供了显着的优势:它在子时间尺度收集主机拥塞信号,它能够调制分配给网络流量的主机资源以维持目标网络带宽,并产生通过确保网络 CC 收敛到与可用网络和主机资源匹配的速率,实现最小丢包率。该实验表明,即使存在主机和网络拥塞,hostCC 也能很好地与网络 CC 进行插值。
深入探讨 hostCC 性能
三种hostCC思想的必要性
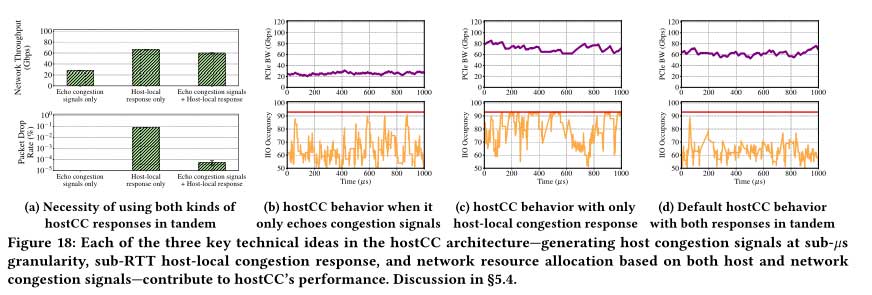
上图展示了 hostCC 架构中的三个关键技术思想(以亚粒度生成主机拥塞信号、亚 RTT 主机本地拥塞响应以及基于主机和网络拥塞信号的网络资源分配)中的每一个都有助于以hostCC的性能。
特别是,在没有主机本地拥塞响应的情况下,可以最大限度地降低数据包丢失率,但代价是吞吐量下降:网络流量仅实现约 28Gbps 的吞吐量。上图显示,通过仔细分配主机资源(使用主机本地拥塞响应)和网络资源(使用主机和网络拥塞信号),hostCC 能够同时实现高吞吐量和低丢包率。使用主机本地拥塞响应,hostCC 能够以避免 NIC 队列缓冲区堆积的方式调整分配给网络流量的主机资源(如越过阈值后立即较小的 IIO 占用所表明的那样),直到网络流量收敛到使用主机和网络拥塞信号获得正确的吞吐量。
讨论和结论
高带宽访问链路的采用和主机内资源相对停滞的技术趋势导致了主机拥塞的出现,即支持 NIC 和 CPU/内存之间数据交换的主机网络内的拥塞。hostCC 是一种拥塞控制架构,可处理主机和网络结构拥塞。hostCC 使用三个关键思想来实现这一目标:生成主机拥塞信号、子 RTT 主机本地拥塞响应,使用主机拥塞信号在网络和主机本地流量之间分配主机资源,并使用主机和网络拥塞信号以RTT粒度执行网络资源分配。我们在 Linux 网络堆栈中实现了 hostCC,无需对应用程序、主机硬件和/或网络硬件进行任何修改。我们根据构建 hostCC 的经验概述了未来研究的有趣途径。
现有的主机资源分配工具不足。
我们需要更多硬件的支持来进行细粒度的主机资源分配。例如,hostCC 当前使用的工具——MBA——有两个主要局限性。首先,虽然写入典型的 MSR 寄存器需要 < 1 秒,但写入 MBA MSR 寄存器需要 ∼22 秒,因此无法实现更细粒度的响应。其次,MBA 具有非线性性能:使用连续 MBA 级别增加延迟会导致非线性和粗粒度响应。我们还需要更多工具来在内存控制器上启用 QoS。
新技术会有帮助吗?
两种重要的新兴技术是 RDMA和 CXL。RDMA 本身不处理主机拥塞;而且,CXL 对于缓解主机拥塞的好处尚不清楚。例如,考虑 CXL 的两个用例。CXL 可以实现内存扩展,CPU 可以直接从 CXL 连接的内存中读取数据;这需要对主机基础设施进行巨大的改变,并且它是否会对主机拥塞带来好处仍然是未来研究的一个有趣的途径。由于主机网络上任何资源的瓶颈,可能会发生主机拥塞;一个特别有趣的案例是由于内存保护硬件设备(例如 IOMMU)内的瓶颈而导致 PCIe 利用率不足。像 ATS这样的新技术可以帮助 IOMMU 引起的主机拥塞,但我们认为需要做更多的工作来避免 IOMMU 引起的主机拥塞。
主机拥塞信号
hostCC 可以轻松扩展以纳入额外的拥塞信号。例如,我们讨论了 hostCC 中的简单扩展,以生成基于延迟的拥塞信号。使用此信号可以允许 hostCC 也与基于延迟的 CC 协议一起工作。虽然商用硬件不提供 NIC 缓冲区占用情况,但探索 NIC 缓冲区占用情况是否可以提供有关主机拥塞的时间、位置和原因的准确信息也很有趣。最后,我们需要额外的拥塞信号来捕获 IOMMU 引起的主机拥塞。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
