
本文主要讨论了端到端的视频编码方法,旨在同时满足机器视觉和人类视觉需求。本文提出了一种名为 DeepSVC 的深度可扩展视频编解码器,它支持从机器视觉到人类视觉的三层可扩展性。在编码器端,DeepSVC 使用语义、结构和纹理层来压缩视频,从视频中提取相应的表示并编码成紧凑且可扩展的比特流。解码器可以根据需要解码部分比特流以进行语义分析或解码更多比特流以进行视觉重建。实验结果表明,本文提出的方法在机器分析和视频重建方面优于传统和基于学习的视频编解码器。
题目:DeepSVC: Deep Scalable Video Coding for Both Machine and Human Vision
作者:Hongbin Lin, Bolin Chen, Zhichen Zhang et al.
来源:ACM MM 2023
文章地址:https://dl.acm.org/doi/10.1145/3581783.3612500
内容整理:令潇越
引言
目前,越来越多的视频数据被消耗用于机器分析,而不是纯粹由人类观看,例如在智能城市和视频物联网等应用中。现有的传统和神经编解码器已经实现了显著的率失真性能,但如何压缩视觉数据以同时供机器分析和人类观看仍有待研究。
为此,MPEG 专家组发起了机器视频编码 ( Video Coding for Machine, VCM ),旨在建立机器视觉的编码标准。最近,已经探索了一些关于 VCM 的工作。其中,部分研究提出了可扩展的图像压缩方案,即使用基础层特征来执行机器分析,使用附加信息在增强层中进行图像重建。然而,这些方法有两个缺点。首先,它们中的大多数仍然专注于图像编码而不是视频编码,因此在视频分析任务中遭受了比特率的显著增加。其次,一些研究提出了用于人类和机器视觉的可扩展图像编码框架,但很少考虑机器和人类分支之间的关系,实际上探索层间相关性对于提高可扩展编码方案的编码效率至关重要。
为了解决上述限制,本文提出了一个名为 DeepSVC ( Deep Scalable Video Coding ) 的深度可扩展视频编解码器,它支持从机器视觉到人类视觉的三层可扩展性。在编码器侧,首先压缩高级语义特征以供机器分析,然后提取并编码低级结构和纹理特征以重建视频以供人类观看。在解码器侧,语义特征可以独立解码,结构层可以与语义层相结合来预测低质量视频帧,纹理层可以基于前面两层重建高质量的视频帧。
本文的主要贡献如下:
- 提出了适用于机器和人类视觉的视频编码方案,支持语义、结构和纹理三层可伸缩性。
- 语义层引入了用于视频特征压缩的 CSC ( Conditional Semantic Compression) 网络,以减少语义特征之间的时空冗余。
- 结构层引入了用于帧预测的 IFP ( Interlayer Frame Prediction ) 网络,利用层间相关性从语义层预测视频帧。
模型
整体架构
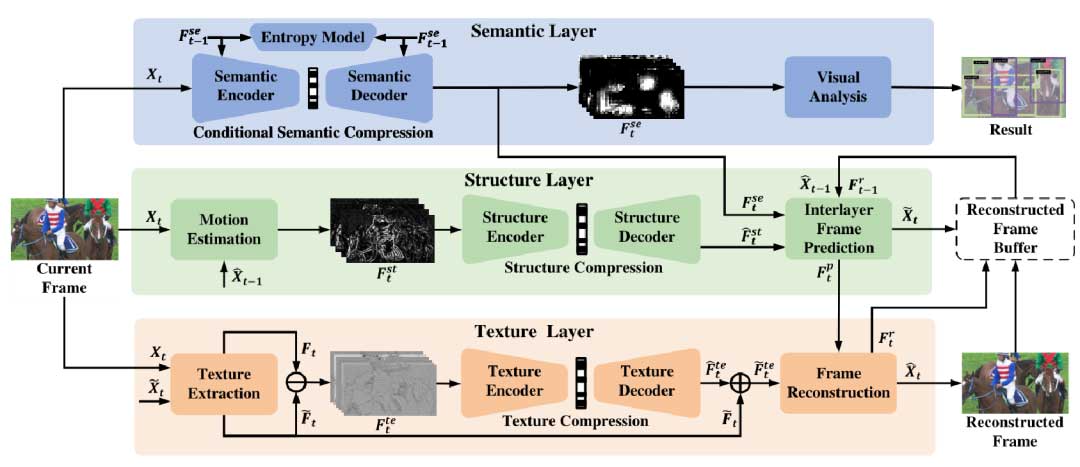
图 1 是 DeepSVC 的整体框架,包括语义、结构和纹理三个层次。语义层旨在压缩用于机器分析任务的高级视觉特征,该层使用条件语义压缩网络对语义特征进行编码。结构层可以与语义层结合,利用层间预测网络预测低质量帧。在纹理层中,基于前面的层重建高质量帧,纹理层还利用 IFP 网络的特征 Ftp 作为参考来提高其编码效率。

CSC 网络
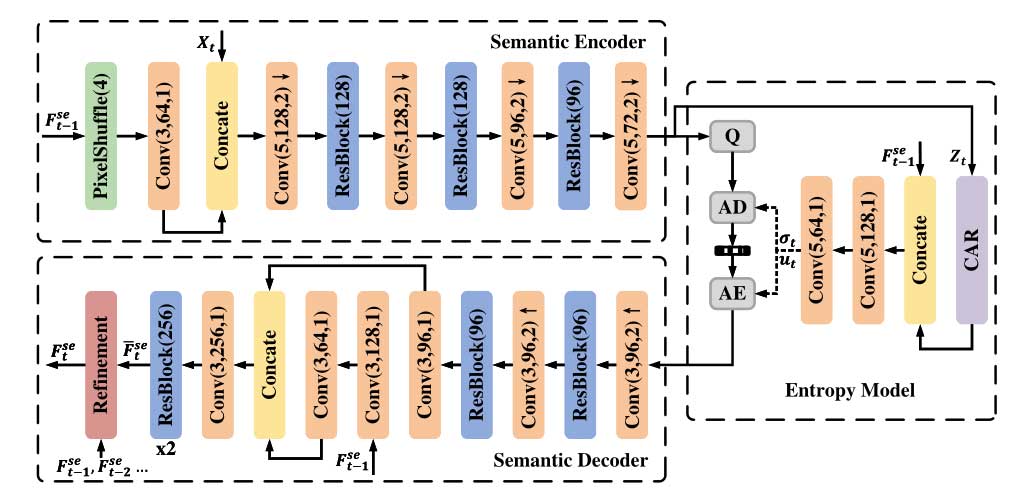
图 2 所示是 CSC 模块的网络结构。在语义层,CSC 网络用于高效地压缩语义特征,以满足机器分析任务。由于连续视频帧之间存在高度相似性,尤其是在高级语义特征中,CSC 网络通过利用这种相似性来降低语义特征的编码比特率。该网络通过将先前解码的语义特征用作条件,以减少当前语义特征的时空冗余。具体而言,CSC网络通过语义编码器和解码器结构,以及一个细化模块,对语义特征进行压缩和解压缩。此外,CSC网络使用了通道自回归(CAR)熵模型来学习潜在表示的空间相关性。
IFP 网络
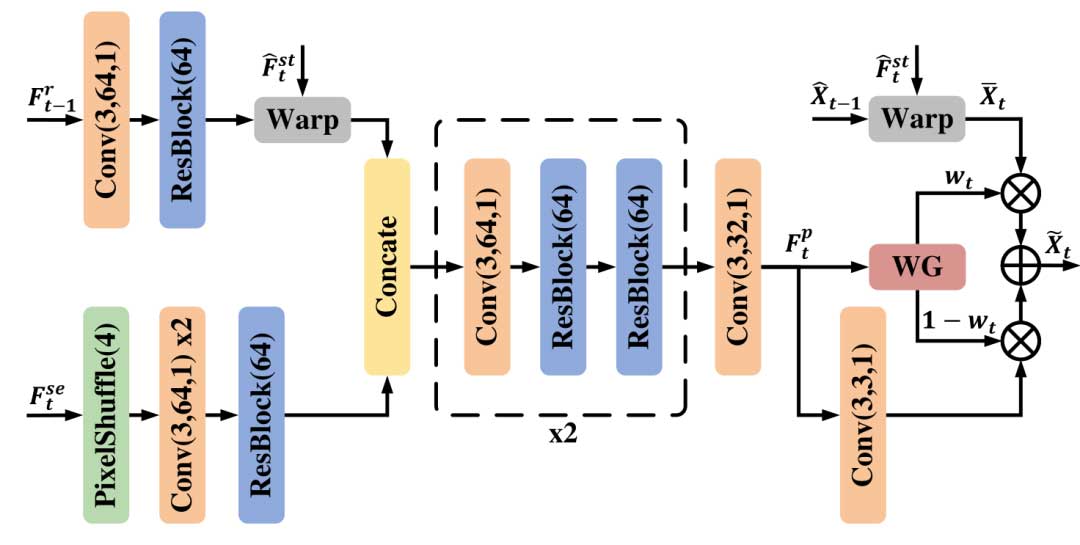
图 3 所示是 IFP 模块的网络结构。IFP网络的设计灵感来自于传统可扩展视频编码中的层间参考机制,该网络旨在通过探索视频不同层次之间的相关性来提高视频帧的预测效果。IFP网络接收已解码的参考帧、对应的特征、已解码的语义特征以及结构层特征,通过加权融合生成当前帧的预测。IFP网络包括特征提取、初始预测、帧变形和加权融合等模块,以有效地进行视频帧的预测。
实验
实验设计
数据集
- 视频目标检测:ImageNet VID
- 视频动作识别:UCF-101 or HMDB-51
- 人类视觉:Vimeo-90k训练,在HEVC Class B C D上验证
评价指标
mAP, Top-1 Acc, Top-5 Acc, PSNR, MS-SSIM, bpp, BDBR
损失函数
- 阶段1:面向机器视觉,按照公式 (1)、(2) 训练语义层
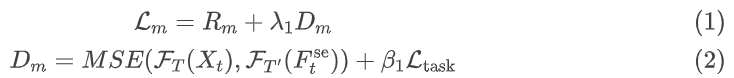
- 阶段2:面向人类视觉,按照公式 (3)、(4)训练结构层和纹理层
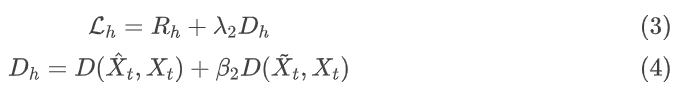
实验验证
速率准确度性能
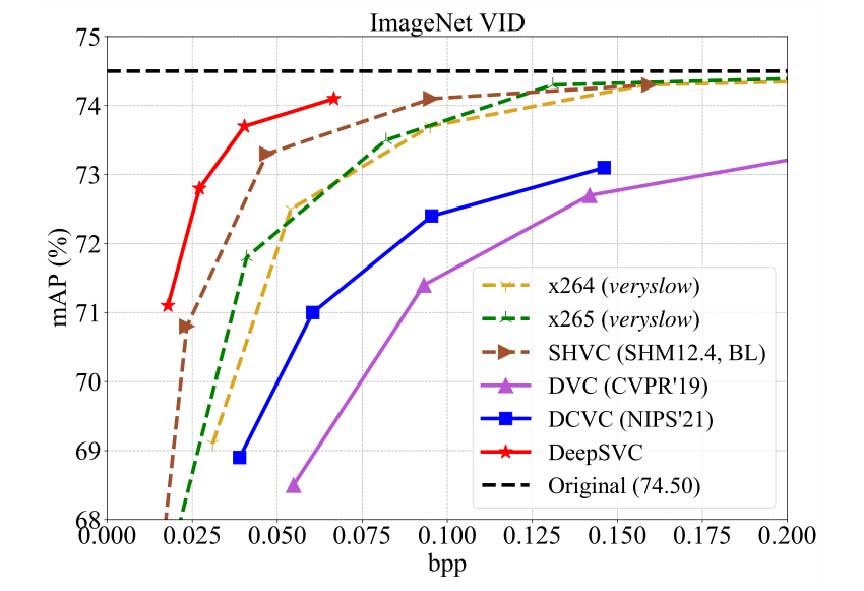

图 4 和表 1 分别是 DeepSVC 语义层在视频目标检测和动作识别任务中的性能评估。与其他压缩方法相比,本文的方法实现了更好的速率准确度权衡,可以以更低的 bpp 获得更高的任务准确度。
率失真性能
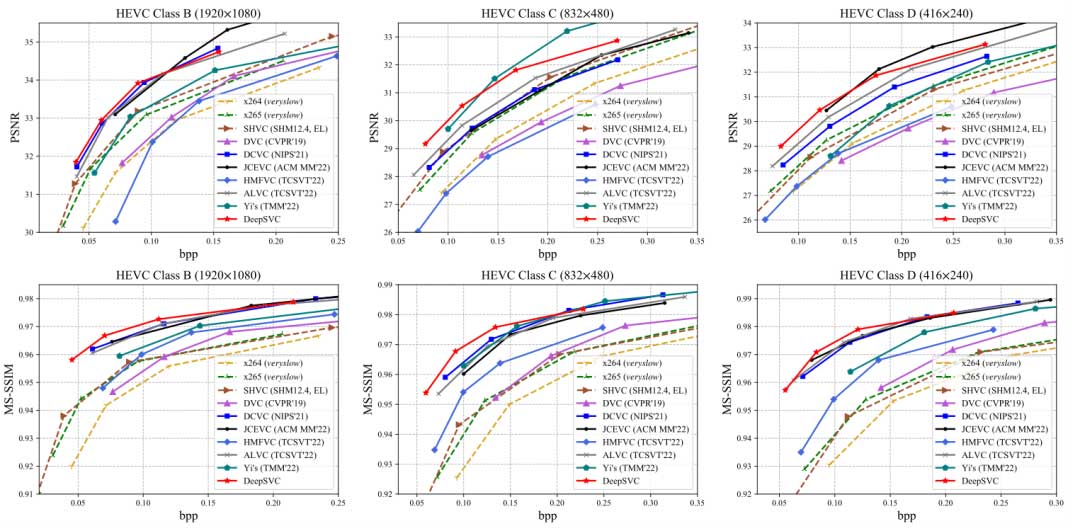
图 5 是 DeepSVC 纹理层在视频重建中的性能评估。关于 PSNR 和 MS-SSIM,与不可扩展编解码器和传统可扩展编解码器相比,本文提出的方法在较低比特率下实现了有竞争力的性能,但重建质量在较高比特率下下降,这可能归因于机器和人类视觉的可扩展性和多任务的额外成本。
复杂性
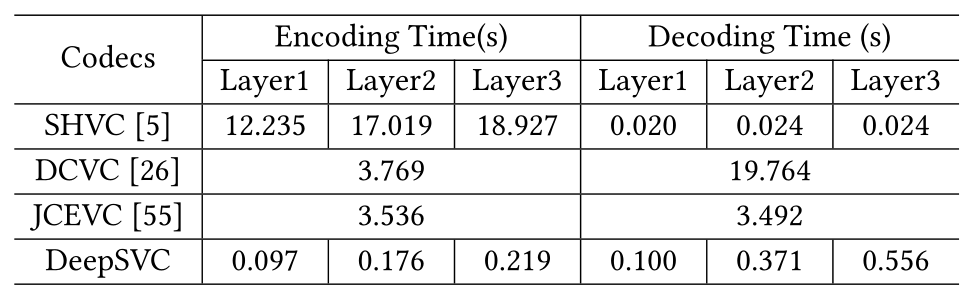
表 2 是DeepSVC与其他方法的平均编解码时间对比。DeepSVC方案可以实现更少的编码/解码时间,为实际应用提供了很大的可能性。
消融实验
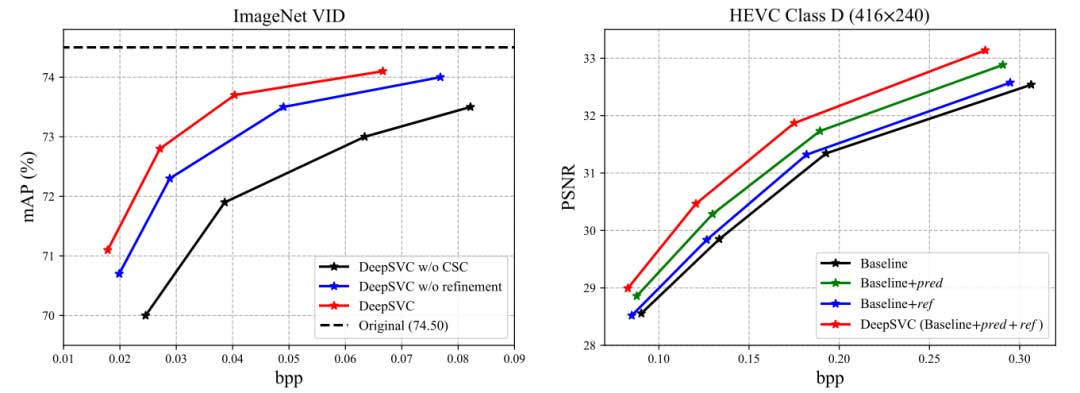
图 6 中左边是 CSC 网络的消融实验,右边是 IFP 网络的消融实验。在 CSC 网络消融实验中,当 bpp=0.05 时,三种设置的 mAP 分别为 72.39%、73.52% 和 73.85%,这意味着所提出的 CSC 网络的有效性。在 IFP 网络消融实验中,与本文采取的方案对比,三种设置的 BDBR 值分别为 29.43%、23.03% 和 12.66%。可以很容易得出结论,通过层间预测和参考,RD 性能不断提高。
结论
本文主要讨论了端到端的视频编码方法,旨在同时满足机器和人类视觉需求。论文提出了一个名为 DeepSVC 的深度可扩展视频编解码器,支持从机器到人类视觉的三层可扩展性。实验结果显示,DeepSVC在机器和人类视觉方面优于流行的编解码器。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
