

研究意义
联邦学习(Federated Learning)可在无需共享原始数据的情况下实现分布式客户端协作训练机器学习模型而得到广泛关注。然而,该架构中上传本地模型仍然有泄露客户端隐私信息的风险。由差分隐私的定义可知,基于差分隐私(Differential Privacy)保护的联邦学习为客户端的数据提供了严格的隐私保障。但此架构需要限制本地训练过程中每个样本梯度对模型更新的影响,然后通过具有一定规模的随机噪声来扰动它,会对训练性能造成一定影响。特别地,随着机器模型参数量的日益增长,差分隐私机制将严重影响模型的准确性,并且造成较高的训练延迟。因此,模型性能和数据隐私之间存在固有的权衡关系。梯度稀疏化技术可对每个样本梯度进行降维,从而一定程度上缓解差分隐私对性能的负面影响和通信带宽有限的压力。然而,现有的基于差分隐私保护的联邦学习系统的研究尚未从无线通信调度和隐私训练两个方面共同考虑梯度稀疏化的优势,缺乏一个高效的框架来提高训练性能和传输效率。
本文工作
为了解决以上问题,本文面向无线网络提出了一种新的隐私保护联邦学习方案,称为基于梯度稀疏化的差分隐私保护联邦学习(DP-SparFL)。通过引入梯度稀疏化技术减轻差分隐私引起的性能下降,并减少无线信道上的参数传输量。以算法的收敛性能上界为目标,优化信道分配和传输功率,可在保证隐私等级情况下获得较高的模型训练精度。
本文的创新点如下:
(1) 提出了一种具有差分隐私保护的梯度稀疏赋能通信高效联邦学习系统。该系统将随机减少样本训练梯度中的元素。可配置梯度稀疏化率的自适应梯度裁剪技术可以提高基于差分隐私的联邦学习的训练性能。该算法能够有效降低差分隐私对联邦学习训练和通信带宽受限的不利影响。
(2) 为了进一步提高训练效率,分析了非凸联邦学习设置下梯度稀疏化速率的收敛上界。构造了一种以收敛上界为目标,满足发射功率、平均延迟和客户端差分隐私要求为约束的随机优化问题。利用李雅普诺夫技术和凸优化方法,提供了一个针对该优化问题的解决方案。
(3) 在MNIST、Fashion-MNIST和CIFAR-10数据集验证所提算法的有效性。实验结果表明所提算法在满足差分隐私要求下明显优于随机调度、轮询和时延最小化算法。
实验结果
本文所提出的算法在3个真实图像数据集上进行了验证,并与3个基准算法进行了对比。本文统计了所有对比算法在各个数据集上的分类测试准确度和累计延迟。实验结果显示,所提出的算法相较于基准算法,仅需消耗更短的累计时延并获得更高分类测试准确度。
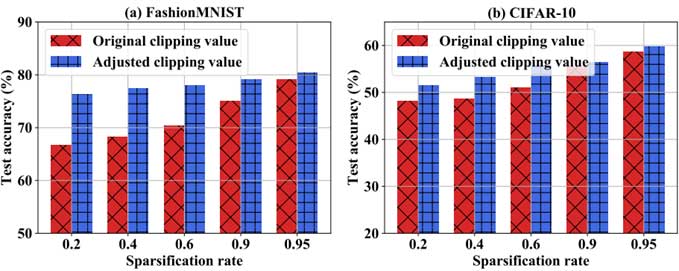
下图展示了所提出DP-SparFL算法在FashionMNIST和CIFAR-10上未调整和调整剪裁阈值的分类测试准确度。可以看到,在各种梯度稀疏化速率下,调整后的方法在FashionMNIST和CIFAR-10数据集上都优于未调整的方法。直观地,较小的梯度稀疏化率可能导致每个客户端的训练梯度的 L2 范数更小,因此较小的剪裁值可以减少噪声方差并提高学习性能。在无线系统中,每个客户端的梯度稀疏化率是不确定的,并且会随着信道条件而变化,因此在每一轮通信中都无法使用预训练方法去搜索最优的切削阈值。
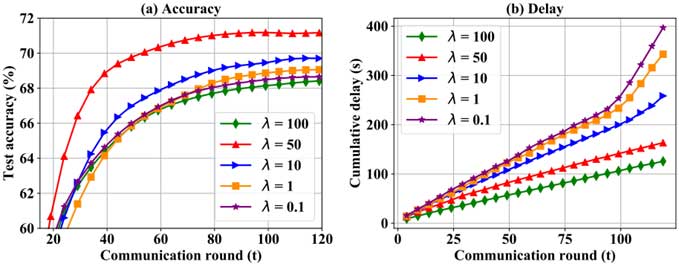
下图展示了在 FashionMNIST 数据集上使用各种值下DP-SparFL 算法的分类测试精度和累积延迟。可以观察到,存在一个最优的可以获得最优的分类测试精度,值越大,训练延迟越大。这是由于较大的值会导致优化目标更偏向于训练精度,相对忽视了训练延迟。因此我们在训练延迟和稀疏率之间找到更优的权衡,以实现最佳的训练性能。
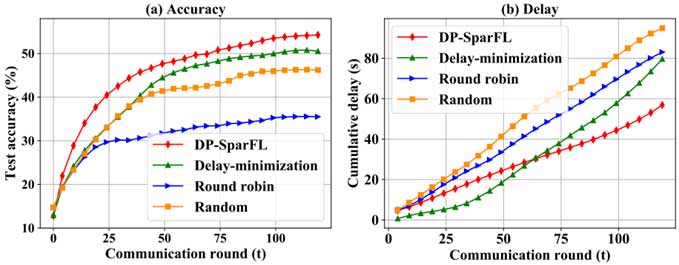
下图展示了FashionMNIST 数据集上非独立同部分数据集条件下的分类测试精度和累积延迟。可以看出,所提算法相比于基准算法能够获得更高的测试精度。原因是在非独立同部分数据设置中,所提算法中隐私性的约束(即参与度)保证了所有客户端能够参与到联邦学习训练,而不会忽略特殊的本地数据。
文章下载
Kang Wei, Jun Li, Chuan Ma, et al. Gradient Sparsification for Efficient Wireless Federated Learning with Differential Privacy. Sci China Inf Sci, doi: 10.1007/s11432-023-3918-9

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
