
最近,基于深度学习的图像压缩方法取得了显着的成就,并在 PSNR 和 MS-SSIM 指标方面逐渐优于包括最新标准通用视频编码 (VVC) 在内的传统方法。学习图像压缩的两个关键组成部分是潜在表示的熵模型和编码/解码网络架构。人们已经提出了各种模型,例如自回归、softmax、逻辑混合、高斯混合和拉普拉斯。现有方案仅使用这些模型之一。然而,由于图像的多样性,对所有图像(甚至一张图像中的不同区域)使用一种模型并不是最佳选择。在本文中,作者针对潜在表示提出了一种更灵活的离散高斯-拉普拉斯-逻辑混合模型(GLLMM),在给定相同复杂度的情况下,它可以更准确有效地适应不同图像中的不同内容以及一幅图像的不同区域。此外,在编码/解码网络设计部分,作者提出了一种级联残差块(CRB),其中多个残差块通过附加的快捷连接串联起来。CRB可以提高网络的学习能力,从而可以进一步提高压缩性能。使用 Kodak、Tecnick100 和 Tecnick-40 数据集的实验结果表明,所提出的方案优于所有领先的基于学习的方法和现有的方法。
题目: Learned IMAGE Compression With Gaussian-Laplacian-Logistic Mixture Model and Concatenated Residual Modules
作者: Haisheng Fu, Feng Liang, Jianping Lin, Bing Li, Mohammad Akbari, Jie Liang, Guohe Zhang, Dong Liu, Chengjie Tu, Jingning Han
论文地址: https://ieeexplore.ieee.org/document/10091784
来源:TIP 2023
代码地址: https://github.com/fengyurenpingsheng/Learned-image-compression-with-GLLMM
内容整理:杜君豪
引言
图像压缩是许多应用中的重要步骤。经典方法,例如JPEG、JPEG 2000和BPG(H.265/HEVC的帧内编码),主要使用线性变换、量化和熵编码等技术来去除减少输入的冗余并实现更好的率失真(R-D)性能,如图1所示。最近,人们研究了基于深度学习的方法,其中根据神经网络的特性重新设计了三个主要组件。该方法在 PSNR 和 MS-SSIM 指标方面逐渐优于传统方法,并显示出巨大的潜力。
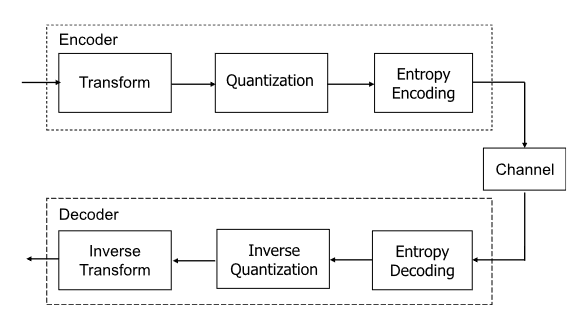

基于学习的方案最重要的区别在于,经典的线性变换被从训练数据中学习的非线性神经网络取代。因此,如何设计网络架构来减少潜在表示(编码网络的输出(也称为特征图))的相关性,对于学习图像压缩方案的性能至关重要。另一个重要的任务是设计一个好的概率模型来捕获潜在表示的剩余相关性,以便可以有效地对它们进行编码。
尽管学习的方法取得了显着的进步,但压缩性能还可以进一步提高。首先,以前的熵模型仅使用单一分布,这对于每个潜在变量来说并不是最优的。其次,潜在表示仍然存在一定的空间冗余。为了解决这些问题,作者在本文中做出以下贡献:
- 提出了一种离散高斯-拉普拉斯-逻辑混合模型(GLLMM),而不是使用单一概率模型,在给定相同复杂度的情况下,该模型在估计潜在变量的条件概率方面更加灵活和高效。事实上,之前的模型是所提出模型的特例。
- 开发具有附加快捷方式连接的级联残差模块(CRM)来改进编码器网络的基本构建块。CRM 改善了信息流,减少了输出的相关性,并改善了网络的训练。
- 实验表明,在作者的方法中不需要应用后处理,因为所提出的 CRM 和熵模型已经做得很好。这也降低了方案的复杂度。
使用 CRM 和 GLLMM 的图像压缩方案
总体框架
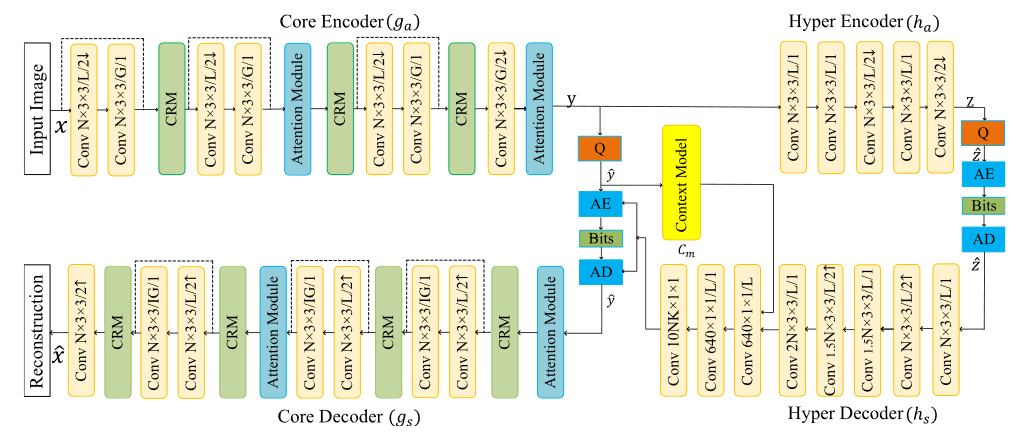
本文采用的学习图像编码框架如图2所示,主要基于Cheng2020。它由两个主要部分组成:核心自编码器和超先验编码。
输入彩色图像 x 的尺寸为 W x H x 3 ,其中 W 和 H 分别表示图像的宽度和高度。在网络训练中,像素值归一化为 [−1, 1]。
核心自编码器包括编码器(ga)和解码器(gs)。输入图像 首先被发送到编码器网络 ga ,其目的是减少冗余并学习输入图像的紧凑潜在表示 y 。然后对潜在值进行量化和熵编码。量化潜在表示由 ŷ 表示。
核心编码器网络包括各种卷积层和四个阶段的池化算子来获取潜伏。具有快捷连接的残差块被广泛使用。尺寸更改时使用 GDN 运算符。
为了提高研发性能,简化注意力模块在两种分辨率下应用来捕获长程相关性,并加强更重要的区域,以便它们获得更多的比特分配。
为了估计潜在分布并提高熵编码效率,引入了超先验编码部分,它由超编码器(ha)和超解码器(hs)组成。超编码器从潜在向量中提取超先验 z,该超先验 z 被量化为 z^ 并被熵编码为超解码器的辅助信息。超解码器首先通过熵解码恢复,然后使用超解码器网络 hs 来估计 ŷ 的条件分布的参数,用于 ŷ 的熵编码和解码。
由于超网络的输入维度远小于原始图像,因此超网络比核心网络简单得多。除了超级编码器和解码器中的最后一层没有任何激活函数之外,大多数卷积层都使用了 Leaky ReLU。
为了进一步提高熵编码效率,我们的系统中还使用了上下文模型网络 cm ,它使用掩码卷积来捕获相邻潜在变量的相关性。上下文模型的输出层与超级解码器第一部分的输出连接,然后通过一些额外的卷积层进一步处理以估计潜在条件分布的参数,然后将其用于熵编码和解码 。
由于使用自回归上下文模型,因此必须以串行方式对符号进行解码。 的所有符号被解码后,被发送到核心解码器(gs)以生成重建图像。
在图2中,核心网络和超网络中的编码器和解码器是对称的,只是它们分别使用卷积和反卷积算子。
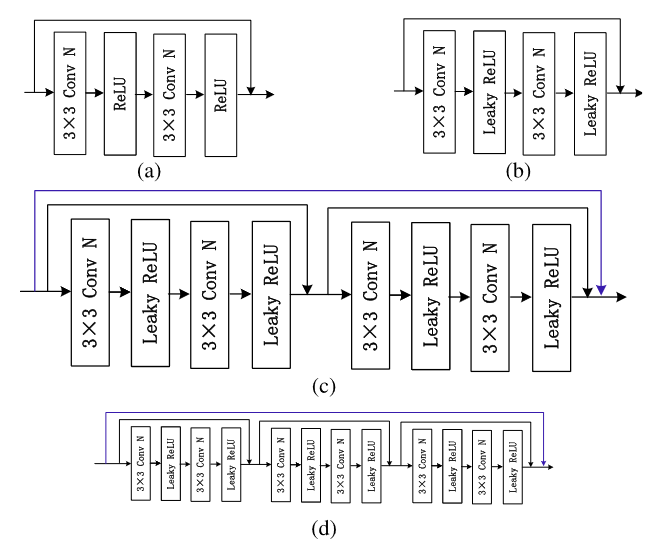
级联残差模块(CRM)
当尺寸不变时,为了进一步消除潜在表示中的空间相关性,我们在本文中开发了两个更深的残差块,如图3所示。基本构建块是ResNet中开发的标准残差块,如图3(a)所述。作者首先使用leaky ReLU激活函数来替换ReLU函数,并从残差块中删除批量归一化层。Leaky ReLU激活函数可以加快网络的收敛速度。详细结构如图3(b)所示。在此基础上,作者开发了两个级联残差模块,如图3(c)和图3(d)所示。
在图3(c)中,将图3(b)中的两个残差块连接起来,并在输入和输出之间添加另一个短连接。在图 3(d) 中,三个残差块被连接起来,还有一个附加的快捷方式连接。
与图3(b)中的标准残差块相比,级联模块具有更大的感受野。它们可以消除更多的空间相关性,这也可以帮助网络中的注意力模块。
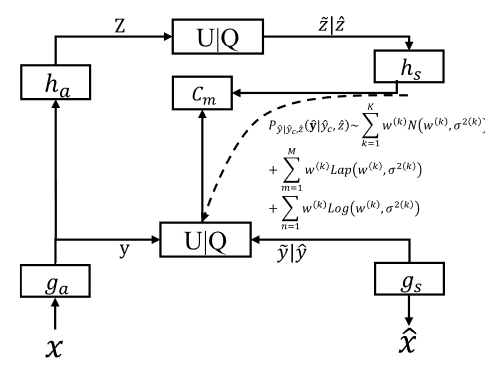
高斯-拉普拉斯-逻辑混合模型 (GLLMM)
在本文中,作者提出了一种强大的高斯拉普拉斯逻辑模型(GLLMM)分布,如图 4 所示。

与以前的单一分布模型相比,所提出的 GLLMM 模型包括三种类型的分布,并且在相同复杂度的情况下可以更准确、更有效地捕获潜在分布,从而提高性能。
实验
Kodak、Tecnick-100 和 Tecnick-40 数据集上的性能
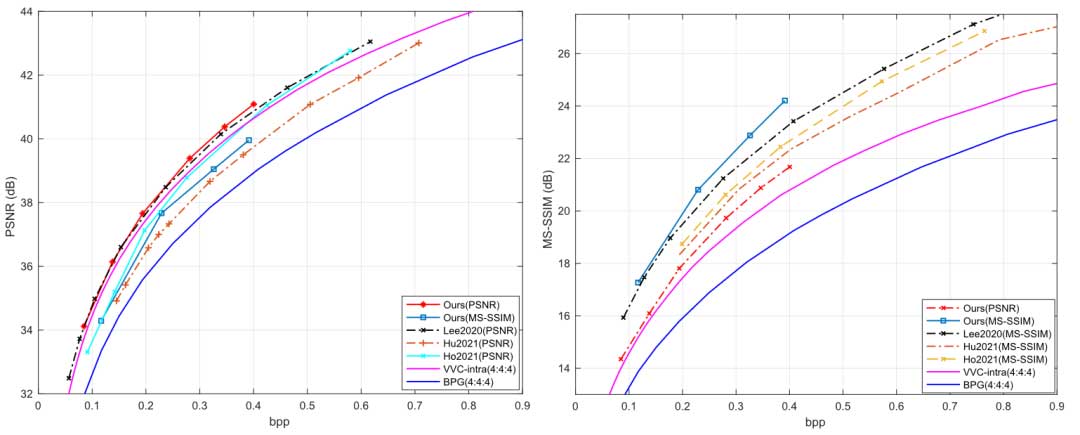
在图5中,当针对PSNR进行优化时,Lee2020(PSNR)是之前方法中最好的,在高速率下获得了比VVC(4:4:4)更好的性能。下一个最接近 VVC (4:4:4) 的方法是 Cheng2020 。当比特率小于0.3 bpp时,作者的方法具有与Lee2020(PSNR)和VVC(4:4:4)相似的性能。当比特率高于 0.4 bpp 时,作者的方法实现了最佳性能,比 Lee2020(PSNR) 提高了 0.2-0.3 dB,比 VVC (4:4:4) 提高了 0.3-0.4 dB。
在图 5(b) 的 MS-SSIM 结果中,Lee2020 (MS-SSIM) 也取得了比之前基于学习的方法和包括 VVC (4:4:4) 在内的所有传统图像编解码器更好的性能。作者提出的针对 MS-SSIM 进行优化的方法取得了比 Lee2020 (MS-SSIM) 稍好的结果。
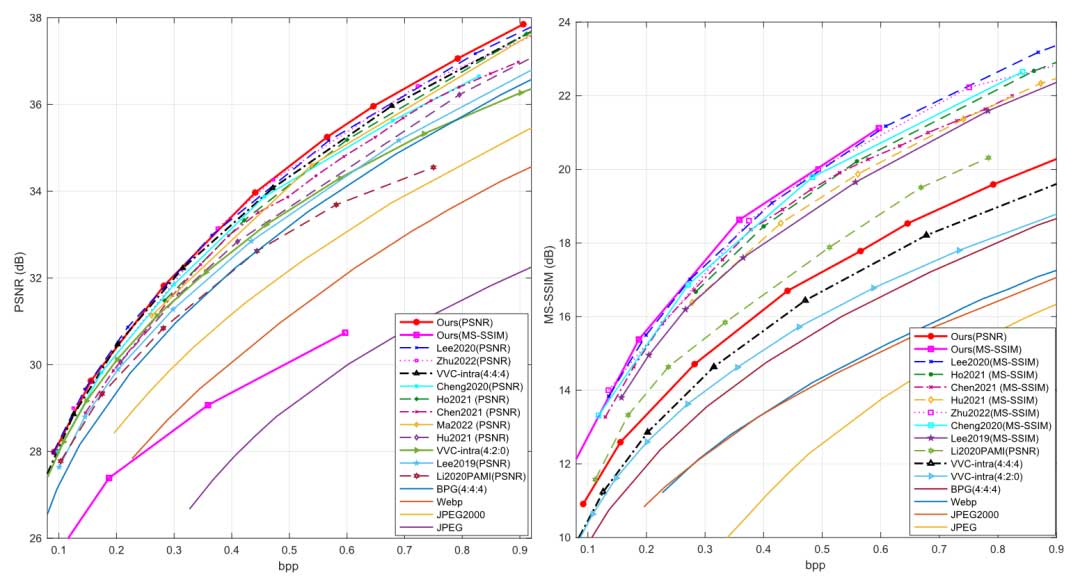
图 6 比较了不同方法在 Tecnick-100 数据集上的性能。作者的方案在 PSNR 和 MSSSIM 方面也优于所有可用的基于学习的方法和所有传统图像编解码器,包括 VVC (4:4:4)。作者的方法是唯一比 VVC 更好的方法。当比特率高于 0.2bpp 时,作者的方法比 VVC (4:4:4) 高约 0.2-0.3 dB。
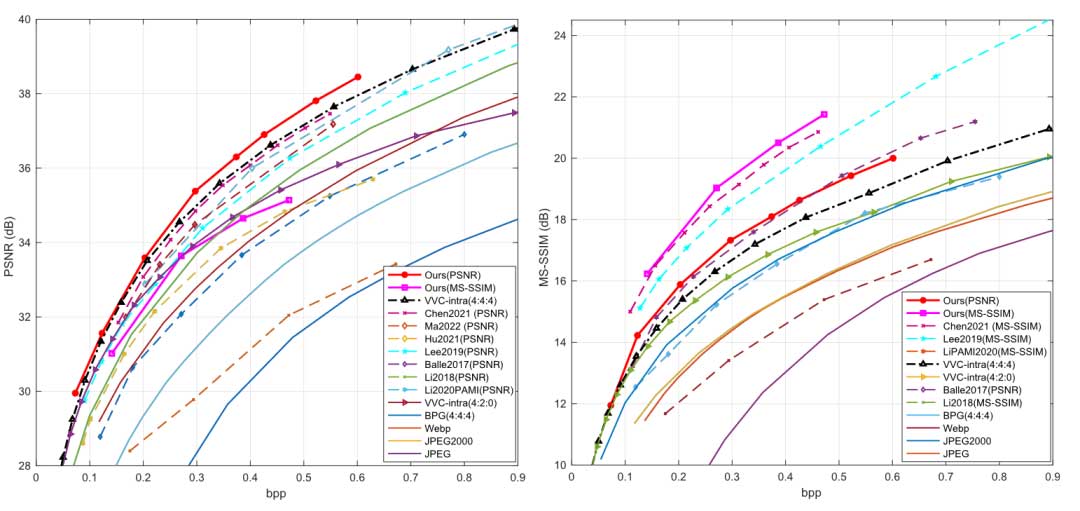
图 7 比较了一些方法在 Tecnick-40 数据集上的性能。其他方法的结果无法得到。作者的方案在 PSNR 和 MS-SSIM 方面也优于其他学习方法,包括 Lee2020 和 VVC (4:4:4)。
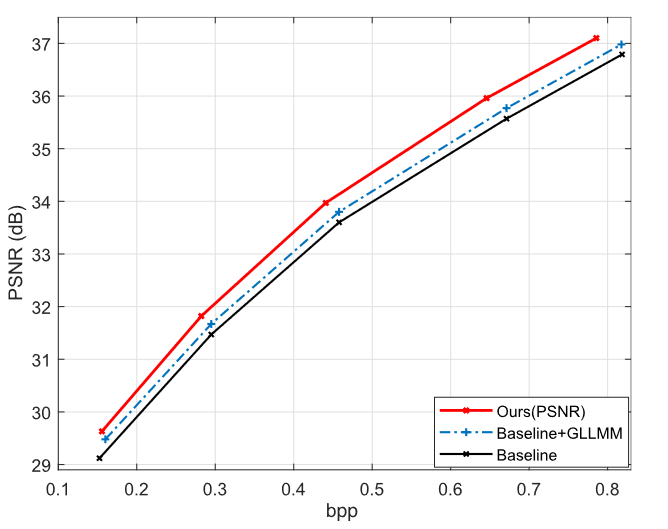
CRM 和 GLLMM 的贡献
结果如图8所示。作者首先将基线中的GMM替换为GLLMM,记为Baseline+GLLMM,这在相同码率下将R-D性能提高了约0.15 dB。与Baseline+GLLMM相比,本文提出的full方法进一步提高了0.3 dB,这是CRM对原始残差块的贡献。
级联残差模块数量
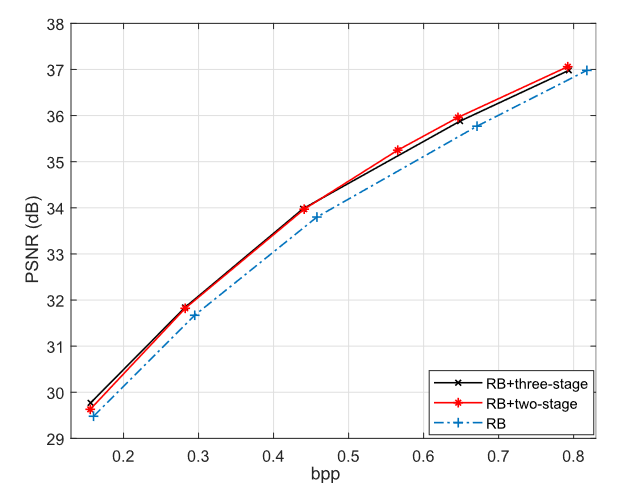
接下来,作者比较标准残差块(RB)、两级级联残差模块(RB+two-stage)和三级级联残差模块(RB+three-stage)。结果如图 9 所示。使用 RB 的方法获得了最差的性能。RB+two-stage法比RB高0.3dB。RB+three-stage在低比特率下实现了与RB+two-stage相同的性能,但在高比特率下明显较差。而且,模型尺寸将增加约13%。因此,我们在框架中采用RB+two-stage方法。
不同熵编码模型的比较
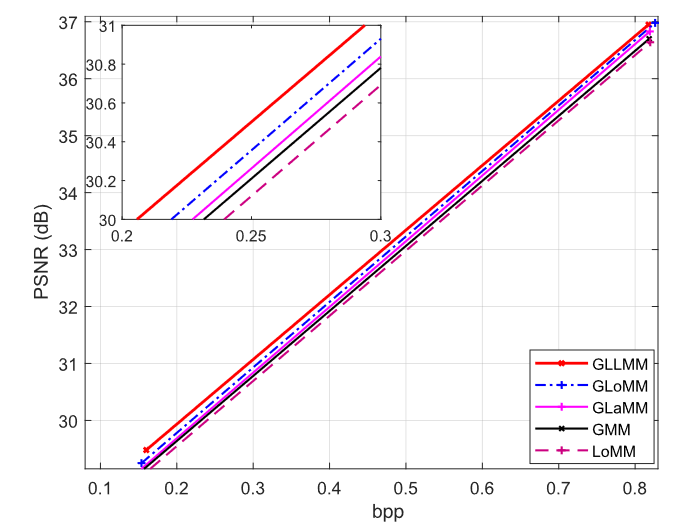
在图10中,我们使用Kodak数据集来比较不同熵编码模型的性能,包括逻辑混合模型(LoMM)、高斯混合模型(GMM)、高斯-逻辑混合模型(GLoMM)、高斯-拉普拉斯混合模型(GLaMM)以及提出的高斯-逻辑-拉普拉斯混合模型(GLLMM)。可以看出,LoMM取得了最差的性能。GMM 比 LoMM 稍好。在 GMM 中添加拉普拉斯分布或逻辑分布可以进一步提高其性能,逻辑分布的收益比拉普拉斯分布的收益更多。最后,如所提出的 GLLMM 中那样添加拉普拉斯分布和逻辑分布可以获得最佳结果。在所有比特率下,不同曲线之间的差距非常一致。
不同阶数的 GLLMM
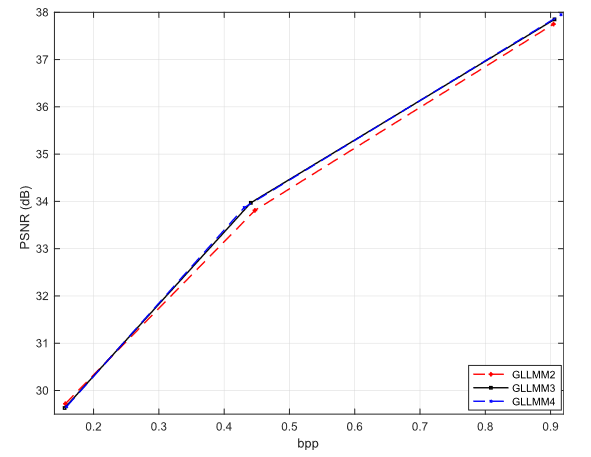
作者使用 GLLMMn 来表示 GLLMM,式(1)中 K = M = J = n。结果如图11所示。可以看出,GLLMM2的性能最差。GLLMM3 比 GLLMM2 高出约 0.15 − 0.2 dB。GLLMM4 几乎实现了与 GLLMM3 相同的性能。因此,本文其他实验中的K、M、J取值为3。
GLLMM 和高阶 GMM 的比较
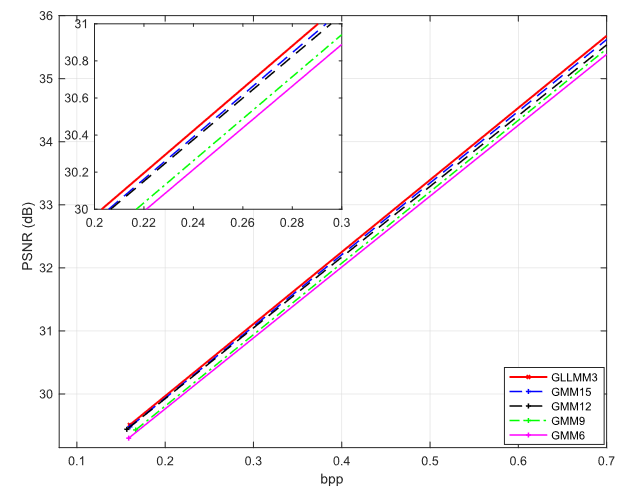
作者还比较了 GLLMM3 和高阶 GMM(表示为 GMMn)的性能。理论上,只要有足够的阶数,GMM 就可以实现任意分布。然而,这是以复杂性增加为代价的,并且收益逐渐减少。对于每种方法,作者分别在低码率和高码率下训练两个模型。结果如图12所示。可以看出,高阶GMM具有更好的性能。然而,性能逐渐饱和。GLLMM3 的性能比 GMM15 更好。此外,GLLMM3 的方程有 30 个参数。而 GMM15 有 45 个参数。与GLLMM3相比,GMM15的编解码时间慢了52.32%,模型尺寸大了17.07%,训练时间长了8.23%。因此,当考虑复杂性时,所提出的 GLLMM 比 GMM 更有效。
注意力模块和上下文模型的影响
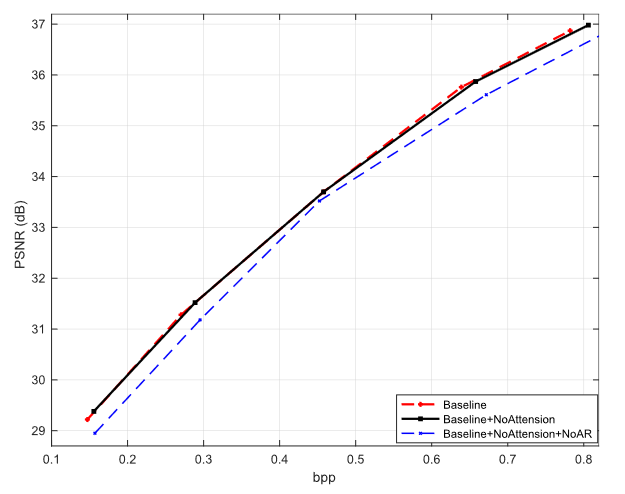
图 13 显示了注意力模块和上下文模型的有效性。在此图中,基线是使用 CRM 和 GLLMM 提出的方法,它实现了最佳性能。Baseline+NoAttension中,去掉了attention模块,与Baseline有类似的性能。Baseline+NoAttension+NoAR 中也去掉了自回归(AR)上下文模型,比 Baseline 低 0.2-0.3 dB。
不同损失函数的影响
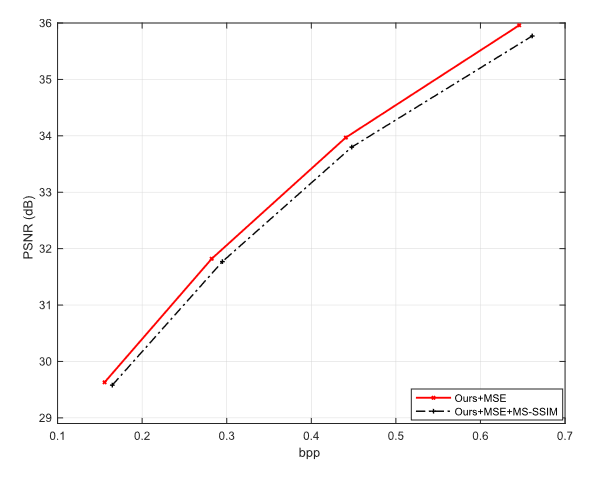
图 14 显示了不同损失函数的影响。在该图中,Ours+MSE是所提出的方法,仅使用MSE作为损失函数中的失真度量D(x, ˆ x),实现了最佳的PSNR性能。在Ours+MSE+MS-SSIM中,作者将MSE和MS-SSIM都包含在损失函数的失真部分中,其PSNR比仅MSE失真的损失函数低0.2-0.3 dB。
总结
在本文中,作者通过提出一种基于离散高斯-拉普拉斯-逻辑混合分布的更灵活的条件概率模型来改进基于学习的图像压缩的技术水平,该模型更有效地捕获潜在表示中的空间通道相关性。作者还为编码器网络开发了一种改进的级联残差块模块。
实验表明,在 Kodak、Tecnick-100 和 Tecnick-40 数据集上测量时,所提出的方法在 PSNR 和 MS-SSIM 指标方面均优于 VVC (4:4:4)。此外,与之前所有最先进的基于学习的方法相比,作者的方案取得了更好的性能。
作者的方法仍有一些改进的空间。由于作者的框架中采用了自回归上下文模型,因此必须以串行方式对符号进行解码。虽然它可以有效地降低潜在表示的空间相关性,但它显着增加了时间复杂度。如何降低上下文模型的复杂性而又不会过多降低性能是未来的研究课题。此外,作者方法的复杂性可以通过模型压缩和优化等不同方法进一步优化。
未来另一个可能的主题是开发用于学习图像压缩的低成本多元混合模型。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。