
本文提出了一种新的轨迹感知 Transformer——TTVSR,以实现视频超分辨率的有效视频表示学习。
来源:CVPR 2022
论文题目:Learning Trajectory-Aware Transformer for Video Super-Resolution
作者:Chengxu Liu, Huan Yang, Jianlong Fu, Xueming Qian
内容整理:王妍
引言
与通常在空间维度上学习的图像超分辨率不同,视频超分(VSR) 任务更注重利用时间信息。为了解决这一挑战,近年来出现了越来越多的 VSR 方法,这些方法可以分为两种范式。前者试图利用相邻帧作为输入(例如,5帧或7帧),并以隐式或显式的方式对齐时间特征。然而,较大的窗口尺寸将极大地增加计算成本,使得这种范式无法捕获远距离帧。后者研究通过循环机制对时间进行利用。然而,由于梯度消失,递归网络通常缺乏长期建模能力。
受 Transformer 在自然语言处理方面的最新进展的启发,其在视觉识别和生成任务方面都取得了重大进展。然而,由于视频的高计算复杂度,它只能从一个较窄的时间窗口学习,导致性能不佳。因此,探索 Transformer 在视频中的正确运用方式仍然是一个很大的挑战。
本文提出了一种新的轨迹感知 Transformer——TTVSR,以实现视频超分辨率的有效视频表示学习。TTVSR 的关键见解是将视频帧制定为视觉令牌的预对齐轨迹,并在同一轨迹中计算 Q, K 和 V。具体来说,本文学习沿着时间维度将相关的视觉令牌链接在一起,这形成了多个轨迹来描述视频中的物体运动。本文通过提出的位置地图更新l’p轨迹,该地图通过平均池化在线聚集令牌周围的像素运动。一旦学习了视频轨迹,TTVSR 只计算位于同一轨迹中最相关的视觉令牌的自关注。本文的贡献总结如下:
- 提出了一种新的轨迹感知 Transformer,这是将 Transformer 引入视频超分辨率任务的首批工作之一。该方法大大降低了计算成本,并实现了视频中的远程建模。
- 广泛的实验表明,在四种广泛使用的 VSR 基准测试中,所提出的 TTVSR 可以显著优于现有的 SOTA 方法。在最具挑战性的 REDS4 数据集中,TTVSR 比 BasicVSR 和 IconVSR 分别提高了 0.70db 和 0.45db 的 PSNR。
提出的方法
用于轨迹生成的位置地图
现有的方法使用特征对齐和全局优化来计算视频的轨迹,这些方法耗时且效率较低。特别是在本文的任务中,随着时间的推移,轨迹会不断更新,计算成本会进一步增加。
本文提出一种用于轨迹生成的位置图,其中位置图随时间表示为一组矩阵。通过这种设计,可以将轨迹生成表示为一些矩阵运算,既方便计算又便于模型实现。在时刻 T,位置图可表示为:

图 1 中给了一个的例子来进一步说明位置地图和轨迹之间的关系。
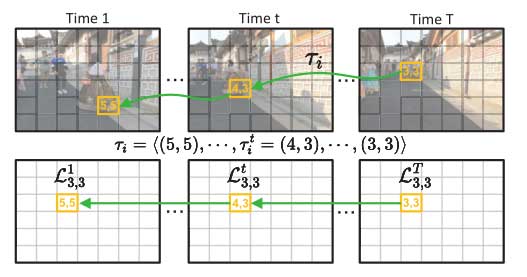
位置地图将随着时间的推移而变化。更新后的位置图表示为 *LT。当从时间 T 改变到时间 T+1 时,应初始化时间 T+1 的新位置地图 *LT+1。 *LT+1 的元素值正好是 T+1 帧的坐标。然后利用逆向光流 OT+1 跟踪从 T+1 时刻到 T 时刻的位置图 L1,. . . ,LT,得到剩余的更新位置图 *L1,. . . ,*LT。具体来说,从轻量级的运动估计网络中获得的 OT+1 可以在时间 T 和时间 T+1 之间建立轨迹的连接。由于流中的相关性通常是浮点数,我们通过插值其相邻坐标来获得位置地图 LT 中的更新坐标:
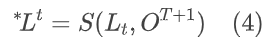
其中 S(·) 表示空间相关 OT+1 的空间采样操作(即 PyTorch 中的网格采样)。由此,时间 T+1 的所有位置地图更新完毕。通过对位置图的精心设计,轨迹感知 Transformer 中的轨迹可以通过一个并行矩阵运算(即 S(·) 运算)有效地计算和维护。
轨迹感知 Transformer
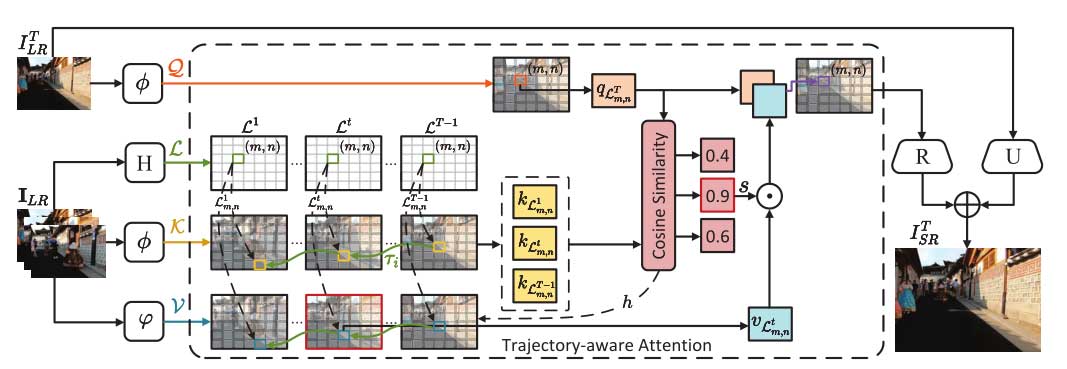

其中,Ttraj(·) 表示轨迹感知 Transformer。Atraj(·) 表示轨迹感知注意。R(·)表示重建网络,U(·) 表示双三次上采样运算。通过在Transformer中引入轨迹,可以避免对空间维度的计算,从而显著减少对 K 和 V 的注意力计算。
不同于传统的注意机制在时间上取键的加权和。Atraj(·) 使用硬注意来选择轨迹上最相关的标记,减少加权和带来的模糊,使用软注意来产生相关 patch 的置信度,当硬注意得到不准确的结果时,减少不相关 token 的影响。hτi,sτi 分别表示硬注意和软注意的结果,计算过程可表示为:

跨尺度特征令牌化
利用序列多尺度纹理的前提是该模型能够适应内容的多尺度变化。因此,本文提出了一个跨尺度特征令牌化模块,在轨迹感知注意之前从多个尺度中提取标记。它可以将多尺度特征统一到一个统一长度的令牌中,并允许在注意机制中利用大尺度的丰富纹理来恢复小尺度的纹理。
具体来说,本文遵循三个步骤来提取令牌。首先,利用连续的展开和折叠操作来扩大特征的接受域。其次,通过池化操作将不同尺度的特征缩小到相同尺度。第三,通过展开操作对特征进行拆分,以获得输出令牌。值得注意的是,这个过程可以从更大的范围提取特征,同时保持与输出令牌相同的大小。它便于注意力计算和令牌集成。
实验
实施细节
本文遵循 IconVSR 和 VSR-Transformer,使用相同的特征提取网络、重建网络和预训练的 SPyNet 进行运动估计。为了充分利用整个序列的信息,采用了双向传播方案,不同帧中的特征可以分别向前和向后传播。为了减少对时间和内存的消耗,从不同的帧生成不同尺度的视觉令牌。相邻帧的特征更精细,所以生成大小为 1 × 1 的令牌。远距离的特征比较粗糙,所以在一定的时间间隔上选择这些帧,并生成大小为 4 × 4 的令牌。此外,在跨尺度特征令牌化中,使用大小为 4 × 4、6 × 6 和 8 × 8 的核进行跨尺度特征标记化。
本文通过两种 4 次下采样的退化方式来评估 TTVSR: MATLAB 双三次下采样(BI),以及标准差 σ = 1.6 的高斯滤波器和下采样(BD)。本文在 REDS4 上应用 BI 退化,在 Vimeo-90K-T、Vid4 和 UDM10 上应用 BD 退化。评价指标为峰值信噪比 (PSNR) 和结构相似性指数 (SSIM)。
实验结果
如表 1 所示,TTVSR 的性能优于其他 SOTA 方法。具体而言,在 Vid4 和 UDM10 数据集上,TTVSR 分别比 IconVSR 高 0.36dB 和 0.38dB。另外,可以注意到,与每个测试序列只有 7 帧的 Vimeo-90KT 数据集上的结果相比,TTVSR 在其他数据集(每个视频至少有 30 帧)上有更好的改进。该结果表明,TTVSR 具有较强的泛化能力,能够很好地对长时间序列的信息进行建模。
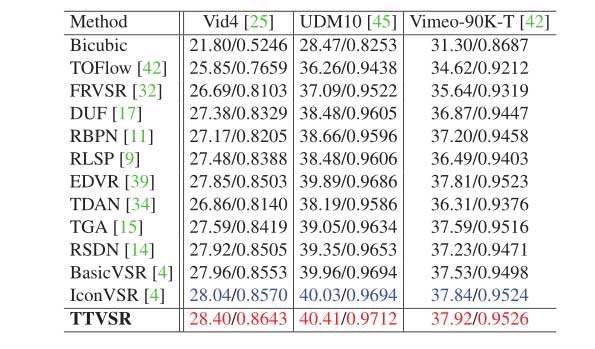
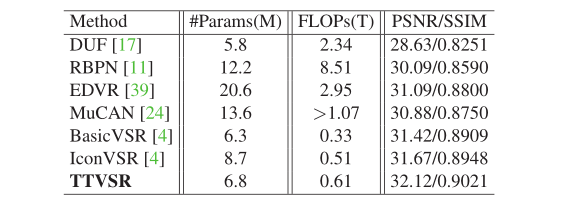
表 2 中评估了各模型的大小和计算成本。与 IconVSR 相比,TTVSR 在保持相当的 #Params 和 FLOPs 的情况下实现了更高的性能。此外,需要强调的是,该方法比 SOTA 基于注意力的方法 MuCAN 要轻量级得多。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
