
本文提出了一种表征条件图像生成方法(Representation-Conditioned image Generation, RCG)。无需任何人类标注提示,它以自监督的表征分布为条件,这个表征分布是通过一个预训练的编码器从图像分布中映射得到的。在生成过程中,RCG使用表征扩散模型从这个分布中采样。使用一个像素生成器从采样得到的表征条件生成图片像素。表征条件为图像生成提供了实质性的指导。本方法达到了无条件生成的SOTA,弥补了条件生成和无条件生成长期以来的性能差距。
来源:arXiv
文章链接:https://arxiv.org/pdf/2312.03701.pdf
作者:Tianhong Li, Dina Katabi, Kaiming He
代码链接:https://github.com/LTH14/rcg
内容整理:王寒
引言
最近利用人类标注的类别条件、文字描述等的条件图像生成达到了令人印象深刻的效果,然而无条件生成还不能达到令人满意的效果。这一定程度上反映了有监督学习和无监督学习之间的差距。从历史发展来看,无监督学习一直落后于监督学习。这种差距随着自监督学习( SSL )的出现而缩小,SSL从数据本身产生监督信号,实现了与监督学习相比具有竞争力或更优越的结果。
自条件图像生成是重要的。首先,对表征的自我调节是一种更直观的无条件图像生成方式,反映了艺术家在将抽象概念转化到画布之前的概念化过程。其次,与自监督学习如何超越监督学习类似,自条件图像生成利用大量无标签数据集,具有超越条件图像生成性能的潜力。第三,通过忽略对人类注释的依赖,自条件生成为在人类注释能力之外的领域(如分子设计或药物发现)的生成性应用铺平了道路。
自条件图像生成的核心在于从图像表示分布中精确建模和采样。这样的图像表示也应该保留足够的信息来指导像素生成过程。为了实现这一点,我们开发了一个表征扩散模型( Representation Diffusion Model,RDM )来生成低维的自监督图像表示。该分布由使用自监督图像编码器的图像分布映射而来。该方法提供了两个重要的好处。首先,RDM能够捕获表示空间底层分布的多样性,使其能够生成多种表示,以方便图像生成。其次,这种自监督的表示空间是结构化的并且是低维的,这简化了直接神经网络结构的表示生成任务。因此,与像素生成过程相比,生成表示的计算开销是最小的。
利用RDM,我们提出了表示条件图像生成( Representation- Conditioned Image Generation,RCG ),这是一个简单而有效的自条件图像生成框架。RCG由三个部分组成:一个SSL图像编码器( Moco v3 ),用于将图像分布转换为一个紧凑的表示分布;一个RDM,用于从该分布中建模和采样;一个像素生成器,用于处理基于表示的图像像素。该设计实现了RCG与常用图像生成模型的无缝集成(常用图像生成模型作为RCG像素生成器),使其无类别条件图像生成性能获得了巨大的提升(如图所示)。
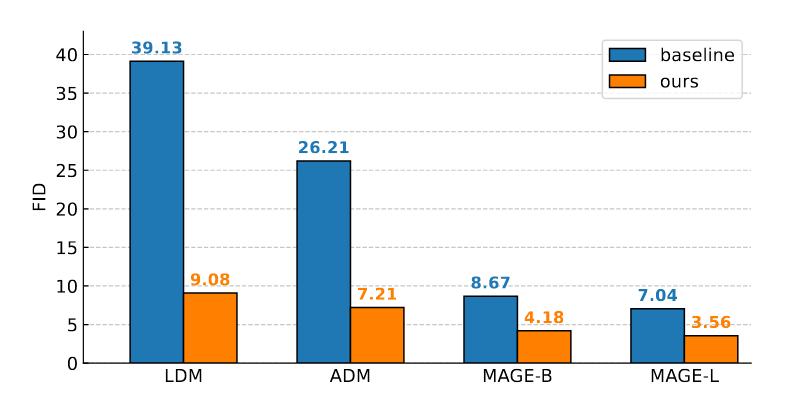
RCG具有出色的图像生成能力。在ImageNet 256 × 256上评测,RCG的FID为3.56,Inception Score为186.9,显著优于所有以往的无类条件生成方法(最近的SOTA结果是7.04 FID和123.5 Inception Score )。这样的结果可以进一步改进为无分类器指导下的3.31 FID和253.4 Inception Score。值得注意的是,我们的结果可以媲美甚至超越现有的类条件生成基准。这些结果强调了自我条件图像生成的巨大潜力,可能预示着该领域的一个新时代。
Method
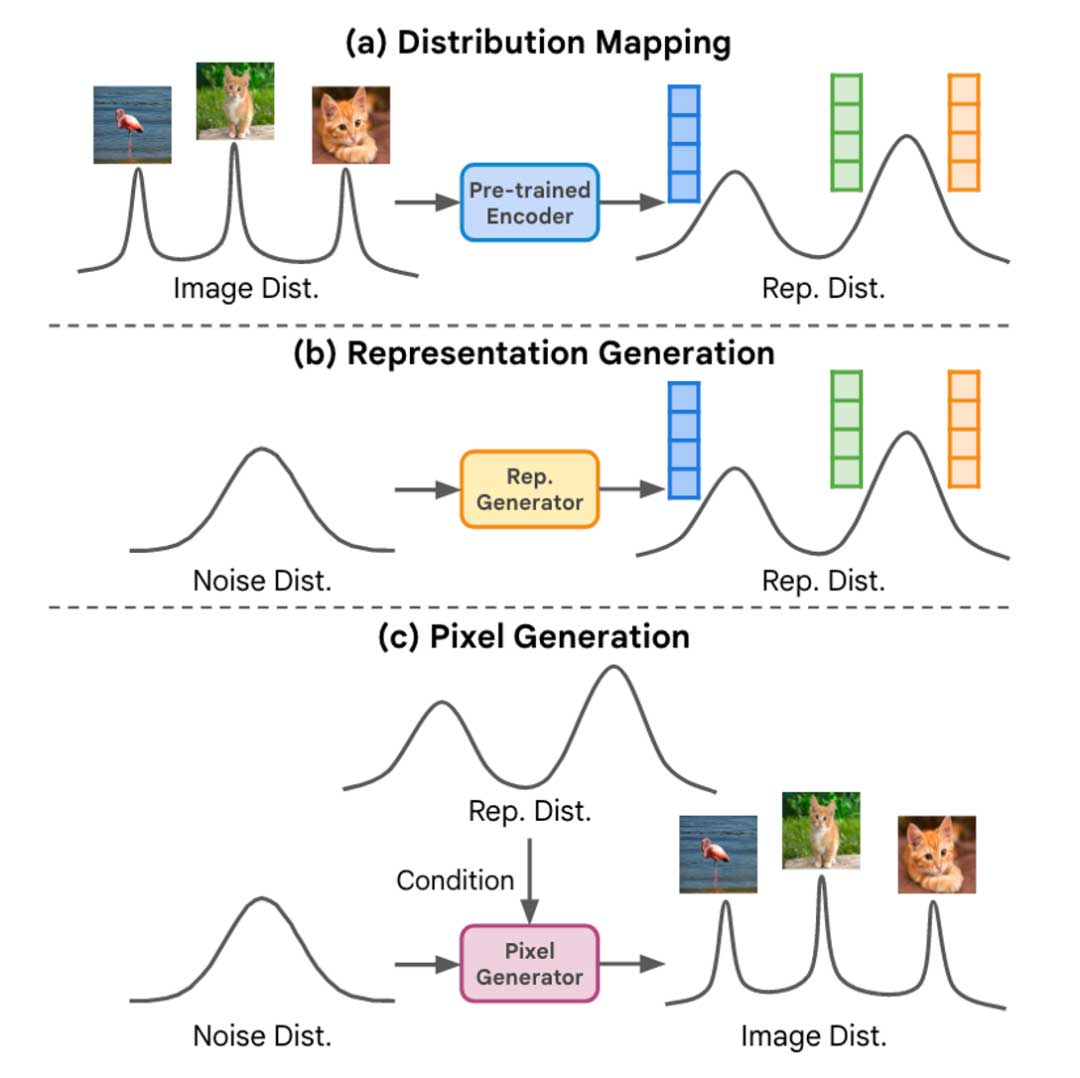
RCG整体框架包括三部分:

图像编码器
图像编码器将图像分布转换为表征空间分布。这种分布具有两个基本特性:通过表征扩散模型进行建模的简单性,以及用于指导像素生成的高层语义内容的丰富性。我们使用经过自监督对比学习方法( Moco v3 )预训练的图像编码器,它在超球体上正则化表示的同时,在ImageNet上实现了SOTA的表征学习性能。我们取经过256维的投影头后的表示,每个表示通过其自身的均值和标准差进行归一化。
表征生成器
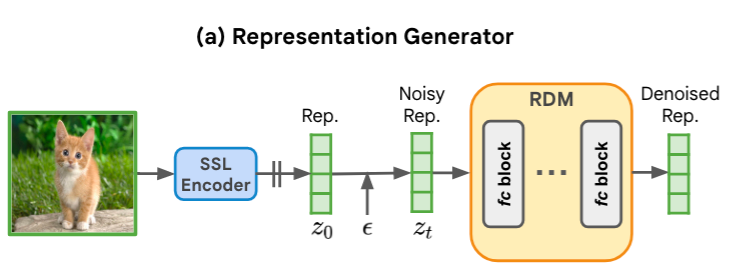
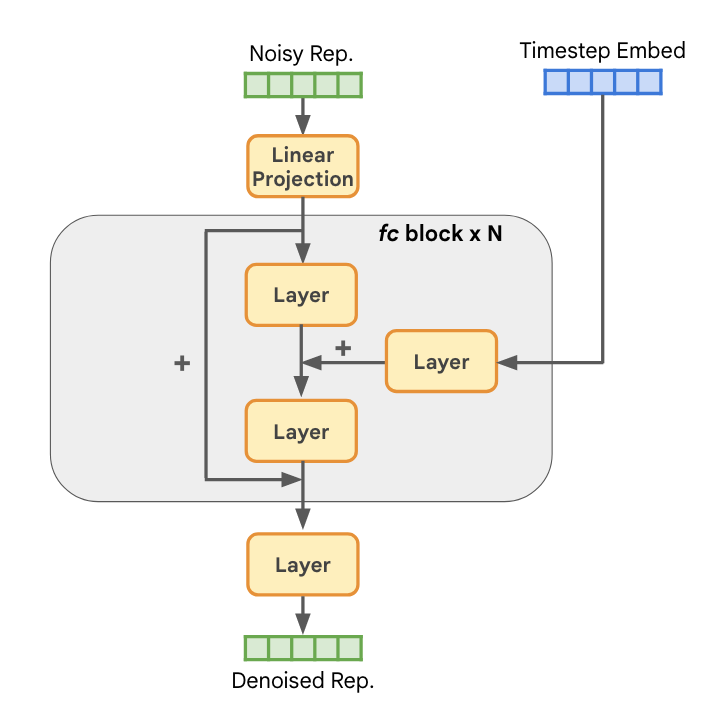
RCG使用一种简单但有效的表征扩散模型( RDM )从表示空间中采样。RDM采用具有多个残差块的全连接网络作为其骨干,如图下所示。每个块由输入层,时间步嵌入投影层和输出层组成,其中每层由LayerNorm,SiLU和线性层组成。这种结构由两个参数控制:残差块的个数N和隐藏维数C。
由于RDM操作于高度紧凑的表示,它为训练和生成都带来了边际计算开销(下表 )。能用更少的参数、时间生成更高质量的图片。
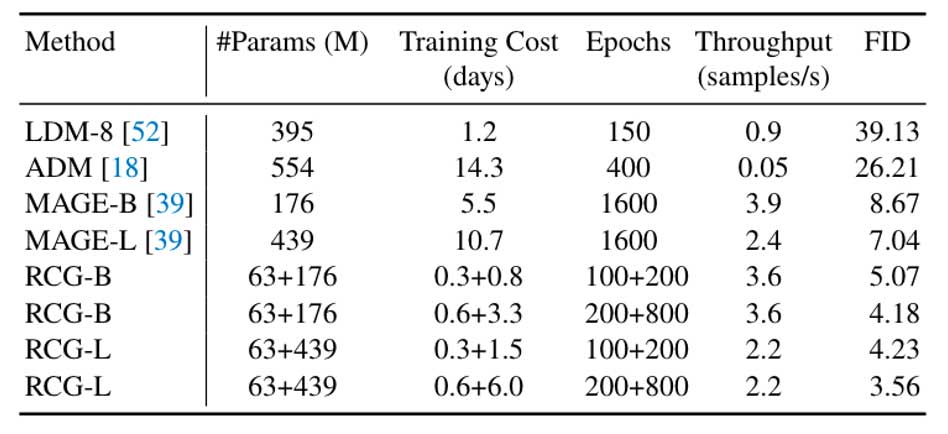
注:使用64个V100 GPU的集群来测量训练成本。在单个V100 GPU上测量了生成吞吐量。
像素生成器
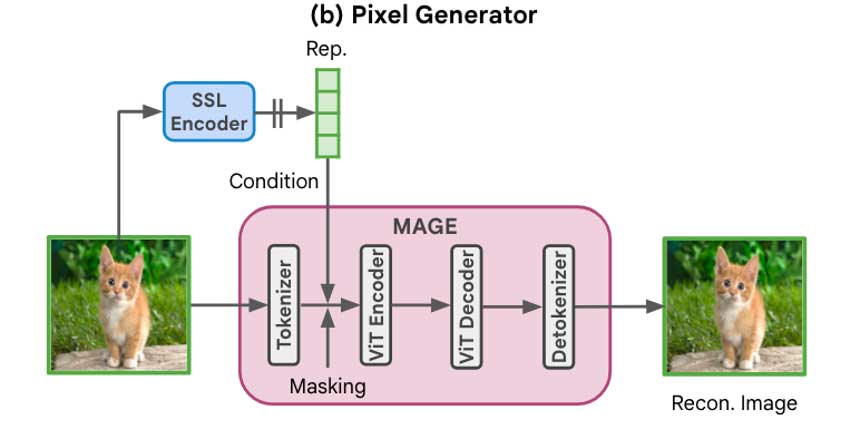
RCG中的像素生成器处理基于图像表示的图像像素。从概念上讲,这样的像素生成器可以是任何条件图像生成模型,通过用SSL表示来代替它的原始条件(例如,类标或文本)。图中我们以并行解码生成模型MAGE为例。训练像素生成器,以同一图像的表示为条件,从图像的掩膜版本中重建原始图像。在推理过程中,像素生成器从一个完全遮蔽的图像生成图像,并以表示生成器的表示为条件。
Classifier-free guidance
RCG的一个优点是它无缝将Classifer-free guidance用于无条件生成任务。虽然RCG是为无条件生成任务而设计的,但RCG的像素生成器是以自监督representation为条件的,因此可以无缝地集成Classifer-free guidance,从而进一步提高其生成性能。
实验
实验细节
我们在ImageNet 256 × 256 上评估了RCG,这是一个用于图像生成的通用基准数据集。我们生成了50K的图像,使用Frechet Inception Distance ( FID )和Inception Score ( IS )作为衡量生成图像的保真度和多样性的标准度量。
FID针对ImageNet验证集进行测量。在RCG的像素生成器训练过程中,对图像进行缩放,使较小的边长为256,然后随机翻转并裁剪为256 × 256。SSL编码器的输入进一步调整为224 × 224,以兼容其位置嵌入大小。对于我们的主要结果,RCG-L使用Moco v3 预训练的视觉转换器( ViT-L )作为图像编码器,具有12个块和1536个隐藏维度的网络作为RDM的骨干,MAGE-L 作为图像生成器。RDM以恒定的学习率训练200个epoch,MAGE-L以余弦学习率调度训练800个epoch。
实验结果
在ImageNet 256 × 256上将RCG与SOTA生成模型进行了比较。由于传统的class-unconditional生成不支持分类器或classifier-free guidance,表1中的所有结果都是在没有这种指导的情况下报告的。
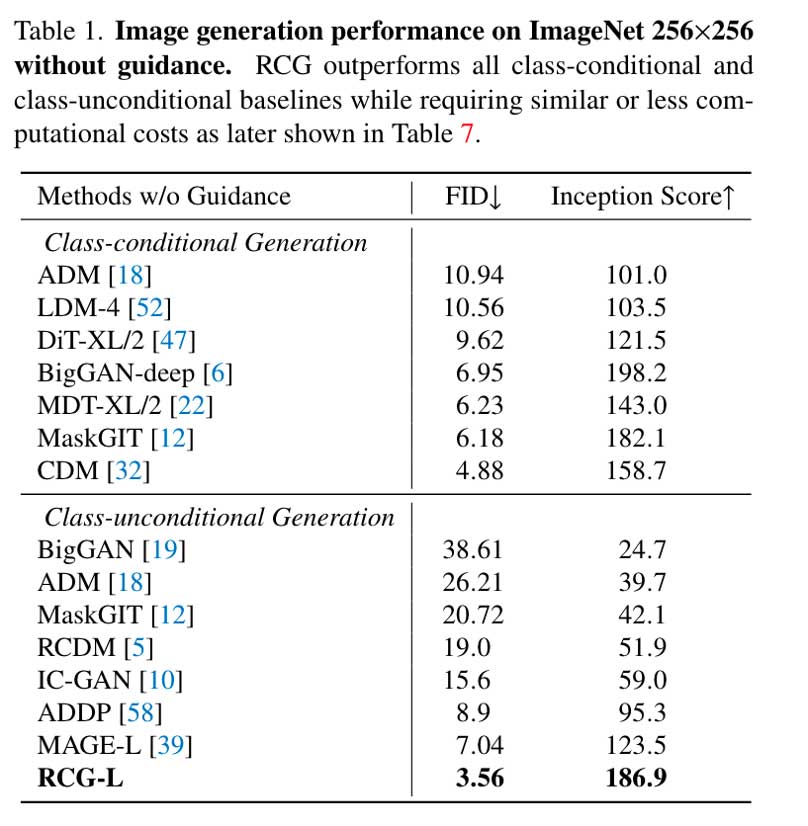

RDM可以促进类条件表示的生成,从而使RCG也能很好地进行Class-conditional 图像生成。证明了RCG的有效性,进一步凸显了自条件图像生成的巨大潜力。


消融实验
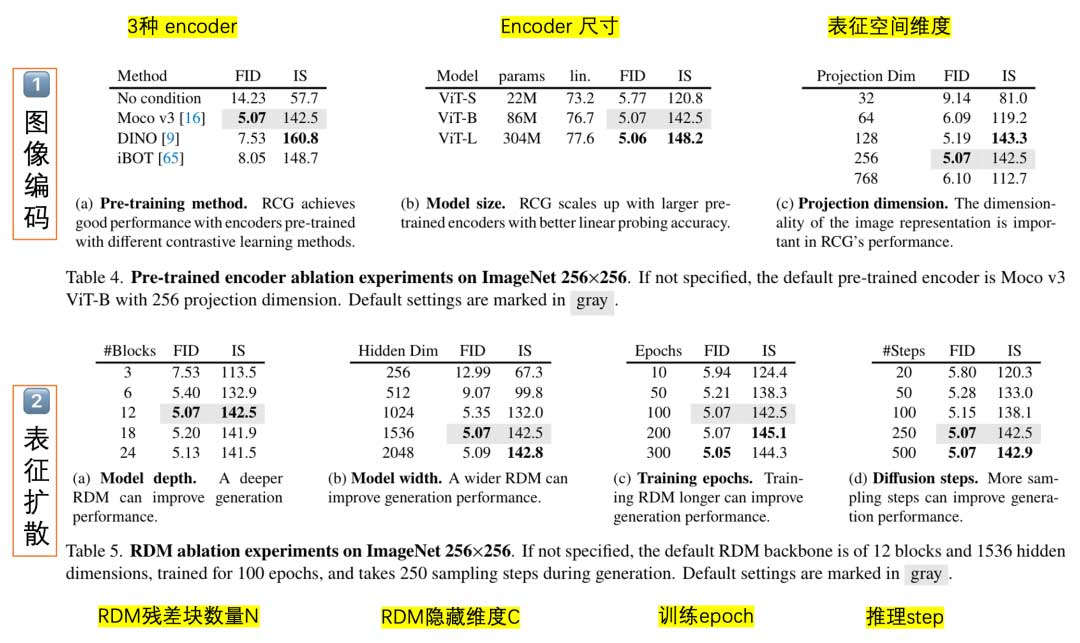
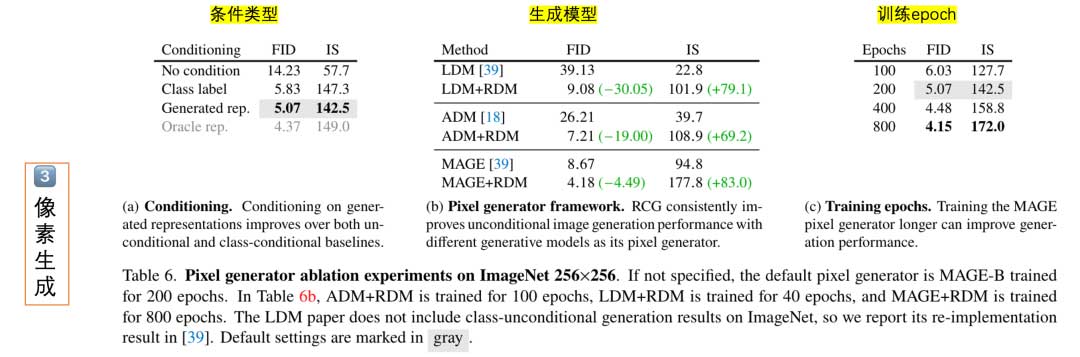
本部分对RCG的三个核心部件进行了全面的消融研究。我们的默认设置使用Moco v3 ViT-B作为预训练的图像编码器,一个12块、1536维隐藏骨干的RDM训练100个epoch,一个MAGE-B像素生成器训练200个epoch。默认设置在表中用灰色标注。除非另有声明,在每个组件的单独消融过程中,所有其他属性和模块都设置为默认设置。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
