
手势是人们讲话时伴随的重要行为,尽管以前的方法和技术能够生成与讲话节奏同步的手势,但这些手势通常缺乏讲话的语义背景。尽管在人类讲话中语义手势并不是非常普遍,但它们对于观众更深入理解讲话上下文是至关重要的。因此,我们引入了Lively Speaker框架,可以实现语义感知的同时生成手势。具体而言,我们将这个任务分解为两个阶段:基于脚本的手势生成和音频引导的节奏优化。广泛的实验证明了所提出的框架相对于其他方法的优势。
作者:Yihao Zhi,Xiaodong Cun 等
论文题目:LivelySpeaker: Towards Semantic-Aware Co-Speech Gesture Generation
来源:ICCV 2023
论文链接:https://arxiv.org/abs/2309.09294
内容整理:王怡闻
引言
人类对话中通常存在非语言行为,其中最重要的是手势语言。这些非语言手势提供了关键信息、丰富了对话的上下文线索。最近,基于深度学习的方法在从多模态输入生成手势的领域中广泛应用。特别是,这些方法将问题建模为有条件的运动生成,并通过训练一个以说话者身份音频波形、语音文本或这些多模态信号的组合为输入的有条件生成模型来解决。虽然结合了多个模态,但结果往往受到音频信号的节奏高度相关的影响,因为它与说话期间手势的表现密切相关。而其他工作认识到通过共话手势传达的语义的重要性,但它们的框架在很大程度上依赖于预定义的手势类型或关键字,这使得难以有效表达更复杂的意图。
我们从以下两个角度的见解开始:
- 现实世界中的人类对话包含有限数量的语义手势,这在学习对语义敏感但与节奏无关的共话手势方面存在困难。这在一定程度上解释了为什么先前的方法产生的结果在很大程度上依赖于音频节奏。
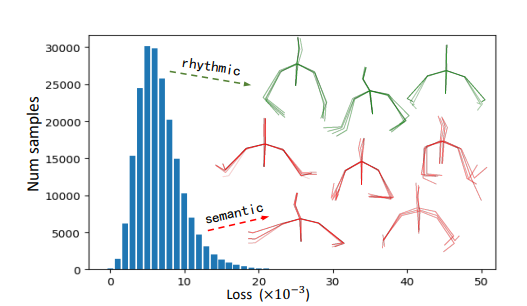
- 大多数先前的方法都建立在生成对抗网络(GANs)之上,这可能很难训练,特别是在学习文本/音频与手势之间的多对多映射时。
在此基础上,我们提出了LivelySpeaker,一个用于语义感知的共话手势生成的简单而有效的框架。具体来说,我们的框架将生成明确地分为两个阶段,即基于脚本的手势生成和音频引导的节奏优化。第一阶段,我们利用预训练的CLIP文本嵌入作为生成与文本脚本高度语义相关手势的引导。在第二阶段,我们设计了一个简单但有效的基于扩散的手势生成骨干,仅以音频信号为条件,并学会以逼真的动作做手势。
在这两个强大模块的基础上,我们的方法可以生成在文本描述和音频给定的情况下语义有意义的共话手势,且多样而高质量。广泛的实验证明了所提出的框架在共话手势生成方面具有领先的性能。我们还进行了实验证明了我们的方法的可控性,包括改变手势风格、通过文本提示编辑共话手势,以及通过引导扩散控制语义意识和节奏对齐。本文的主要贡献总结如下:
- 我们提出了LivelySpeaker,一个用于语义感知和节奏感知的共话手势生成的新型两阶段框架。
- 我们设计了一种新颖的基于MLP的扩散骨干,该骨干在共话生成的两个基准上取得了最先进的性能。
- 我们的框架实现了共话手势生成的几个新应用,例如基于文本提示的手势控制、在两个不同条件模态之间(即文本和音频)平衡控制。
方法
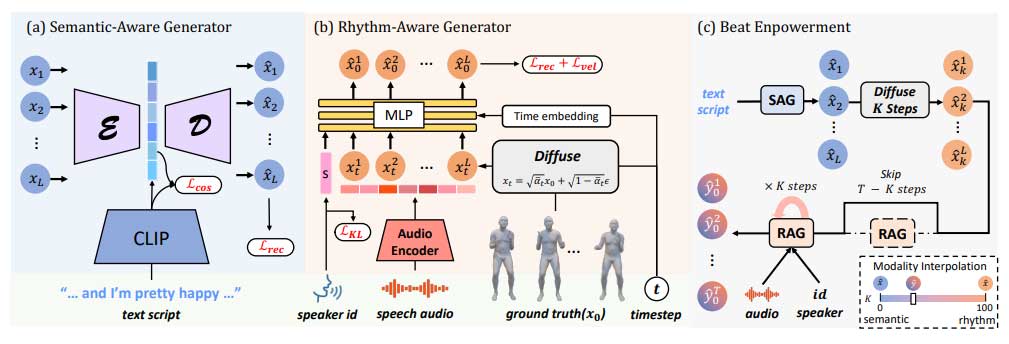
我们的系统旨在生成与演讲在语义和节奏上对齐的3D骨骼手势。我们通过一个两阶段框架来解决这个问题,包括语义感知生成器(SAG)和节奏感知生成器(RAG),在训练每个组件之后,我们可以首先从文本脚本生成手势,然后利用节奏感知网络作为强化器。
语义感知生成器
为了充分利用语义信息,在我们框架的第一阶段中,我们只训练一个语义感知生成器(SAG)从文本脚本中生成手势。受到文本到运动的启发,我们将运动序列分割成固定的段,并将它们送入一个编码器-解码器式的Transformer进行运动生成。我们的网络包含3层编码器和解码器。每个Transformer层的潜在维度为512,前馈层的维度为1024。为了整合语义感知信息,我们使用预训练的ViT-B/32的CLIP作为文本嵌入网络,获得整个脚本序列的512维语义特征。
节奏感知生成器
尽管我们的语义感知生成器(SAG)能够产生一些具有语义意识的手势,但不同步的手势也限制了生成动作的真实感。然而,仅仅调整生成动作的时间信息并保持其他内容不变存在困难,因此我们利用了基于扩散的模型。与原始的MDM不同,我们使用了N层基于MLP的网络构建,它生成更好的节奏并产生更平滑的结果。具体而言,我们首先使用一个线性层将输入数据投影到更高维度的潜在空间。在应用一系列MLP块之后,使用最后的线性层将潜在特征投影回姿势作为输出。每个MLP块由一个用于时间合并的全连接层(FC层)和一个用于空间合并的FC层组成。对于每个MLP块,我们使用层归一化(LN)作为预归一化,SiLU作为激活,并应用跳跃连接。至于附加条件,我们将音频特征连接到采样的姿势并将时间步骤嵌入temb添加到每个MLP块。我们还将说话者ID嵌入到向量中,并通过重新参数化计算样式嵌入s,其中s沿时间维度串联。
完整流程与应用
在训练完语义感知生成器和节奏感知生成器模型之后,我们可以利用后者来解决前者输出的节奏问题。具体而言,如图2(c)所示,在从SAG生成语义感知动作后,按照SDEdit的方法,我们可以通过添加K步噪声反转生成的动作,然后将此动作视为T−K(此处K = 20)的生成动作,通过DDIM(T = 100)以音频的指导将其去噪到一个新的分布。在推断长序列时,我们依次对每个运动片段(由34帧组成)重复上述过程,然后将它们连接在一起。由于扩散型模型的强大功能,这个简单的拍子强化步骤既保留了来自语义感知生成器的多样性,又极大地增加了节奏的对齐度。
由于我们单独学习每个阶段,而每个阶段建模不同的分布,我们的方法能够实现一些有趣的应用:
- 通过新文本提示生成语义动作:我们发现单独学习的语义感知生成器也是一个良好的可控手势生成器。我们可以将一些新的文本提示添加到我们的语义感知生成器的CLIP编码器中,我们的方法还会生成相应的动作。
- 在不同模态之间插值姿势:我们的方法可以通过控制扩散模型的去噪步骤,实现基于脚本运动和基于节奏的微调的不同手势的生成。
实验
定量比较
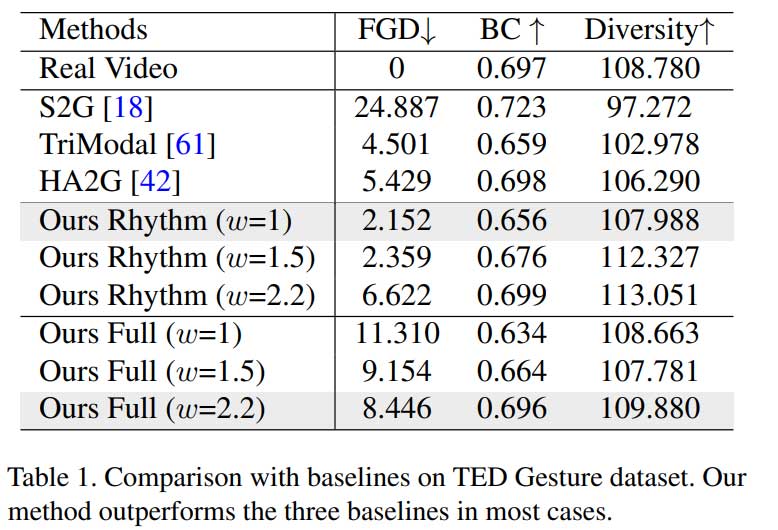
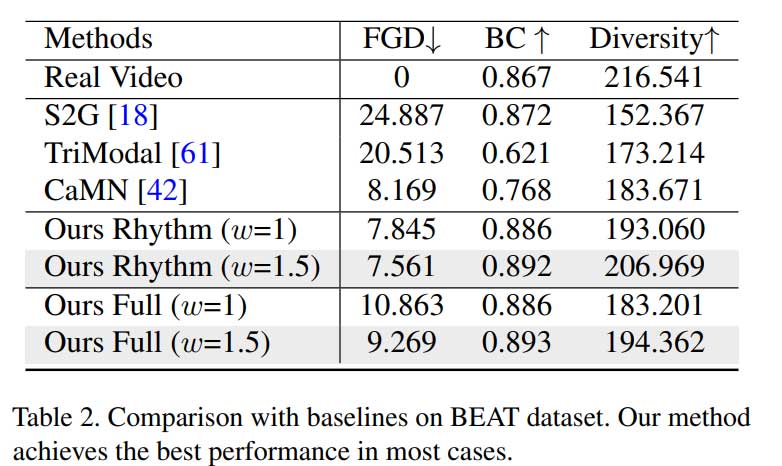
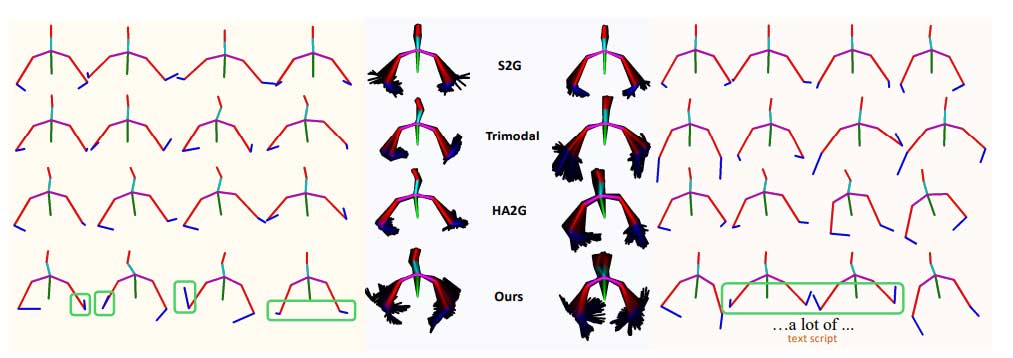
结果可视化
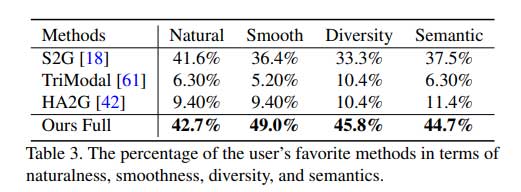
人类评价
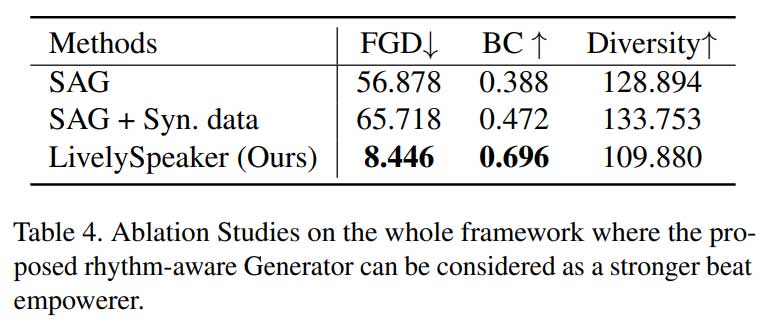
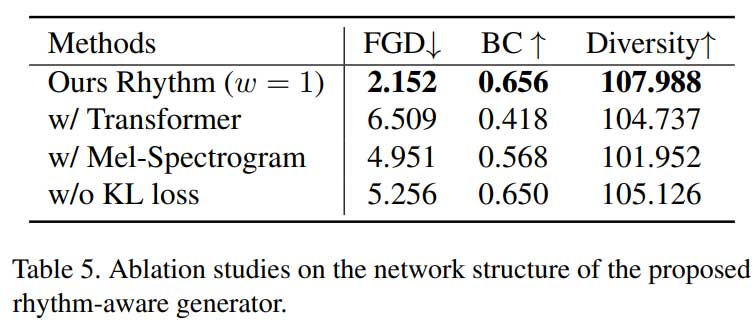
消融实验
总结
在本文中,我们提出了LivelySpeaker,这是一个新颖的语义感知和节奏感知的共话手势生成系统。为了实现这一目标,我们首先从语义感知生成器生成动作,然后训练了一个基于扩散的节奏感知生成器,并利用它进行节奏感知的微调。由于我们的解耦框架的支持,我们的方法在共话生成中实现了多种新应用,包括基于文本的姿势风格控制和在文本和音频之间进行插值手势。此外,我们纯粹基于扩散的骨干结构在共话手势生成方面也实现了最先进的性能。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
