
语种混杂(Code-mix)是一句话中交替使用两种或多种语言的行为,在当今全球化和文化多样的世界中变得越来越普遍。这种语言现象对语音和语言处理任务,特别是语音识别(ASR)形成了新的挑战,包括对特定语言表示的有效建模和对语言边界的准确预测。目前基于混合专家(Mixture of Experts, MoE)的模型利用语言专家有效地提取特定语言的表示,已在语种混杂语音识别中得到应用。然而,由于不同语言之间发音相似可能导致多语言建模能力减弱和语言边界估计不准确,因此仍有改进空间。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)和华为合作论文“BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching Speech Recognition”被语音领域旗舰会议IEEE ASRU 2023接收。该论文提出了边界感知的中英混杂语音识别方案,引入了特定语言的适配器来分离特定语言的表示,同时计算特定语言适配器平均输出的语言自适应损失,以改进适配器模块的特定语言表示学习,利用边界感知预测器来学习边界表示,以处理语言边界混淆。本文将对该文章进行简要的解读。
论文题目:BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching Speech Recognition
合作单位:华为
作者列表:陈培坤,俞帆,梁宇颢,薛鸿飞,万旭成,郑乃君,周欢,谢磊
论文原文:https://arxiv.org/abs/2310.02629


背景动机
在当今全球化和文化多样的世界中,语种混杂(比如中英混)的场景变得越来越普遍。这种语言现象对语音和语言处理任务提出了新的挑战。对于语音识别而言,在统一的神经架构中同时对多种语言进行有效建模是一个关键问题,因为不同语言的建模单元存在差异,尽管它们在发音上有相似之处。此外,在语言切换过程中混淆语言边界会误导模型的语言识别倾向,从而影响模型表现。
针对上述问题,我们提出了一种语种边界感知的混合专家系统,即Boundary-Aware Mixture-of-Experts (BA-MoE),引入特定语言的适配器来分离特定语言的表示,同时计算特定语言适配器的平均输出的语言自适应损失,以改进适配器模块的特定语言表示学习,利用边界感知预测器来学习边界表示,以处理语言边界混淆。在ASRU2019中英混杂挑战竞赛数据集[1]上相对于基线错误率下降了16.55%,同时优于其他对比方案。
提出的方法
BA-MoE
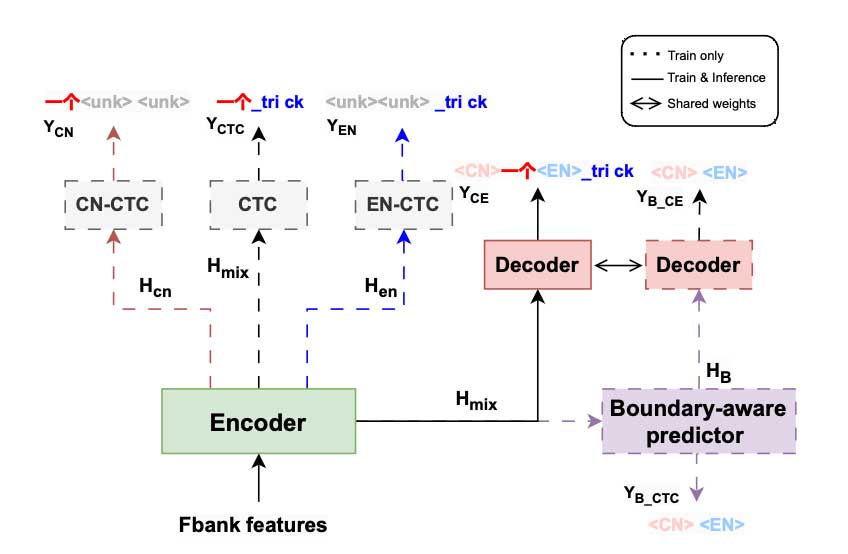
模型结构如图1所示,使用MoE-Adapter作为Encoder来提取语音表示。为了促进单语表征学习,我们采用了一种跨层的语言自适应训练方法来优化适配器模块。注意池机制被用作边界感知预测器,从而能够预测分段级别的语言切换。最后,我们使用Transformer解码器来分别预测帧级和分段级声学表示的生成标签和边界标记。
MoE-Adapter
为了有效地捕捉不同语言之间的语言特定知识,我们将adapter模块作为专家模块来捕捉语言特定表示。如图2所示,同时在每层的适配器之后引入了门控网络。因此,每个MoE-Adapter块包含一个Conformer层,然后分别是中文和英文adapter和一个门控网络。适配器的输出使用门控网络进行组合,生成MoE-Adapter Block的输出。随后,该输出被传递给下一个块进行下一步处理。如下公式:
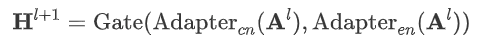
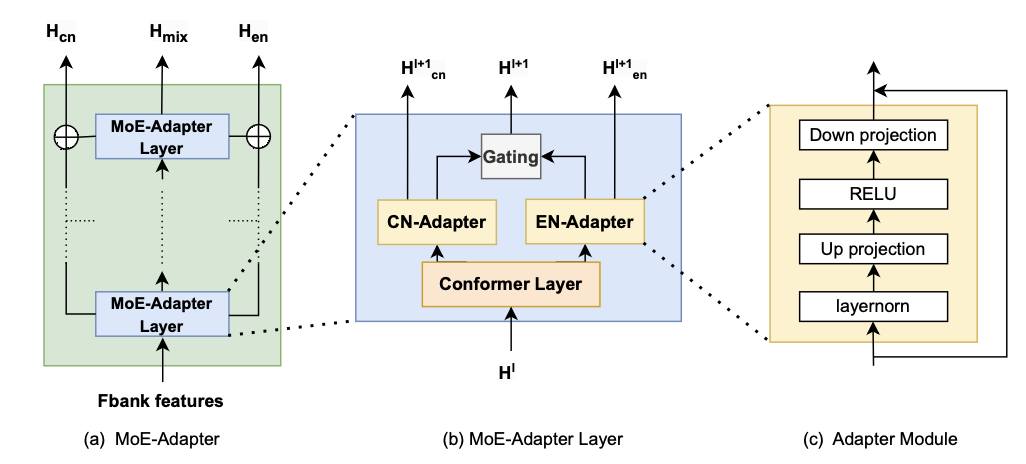
(c)Adapter Module
Cross-layer language adaptation training(CLA)
为了进一步提高adapter捕获语言特定表示和不同适配器之间相关性的学习能力,我们提出了一种跨层语言适应(CLA)训练方法。此外利用多层单语适配器的输出作为单语语言表示,从而提高了两种语言的基础适配器之间的区分度。(2)为中文部分的公式,英文部分同理。
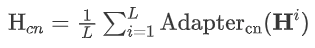
在训练期间,通过使用特殊标记 <Unk> 掩蔽目标序列中的非目标语言标记来生成目标序列。我们使用 CTC 损失仅在训练阶段作为辅助损失。
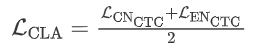
该损失作为CLA的整体损失参与最后的损失计算。
Boundary-aware trainng(BAT)
为了解决边界混淆,我们提出了一种边界感知训练(BAT)方法。首先,利用明确的边界信息对目标进行标记,从而获得Yatt,其中<CN>和<EN>作为表示语言边界的标记。然而,直接将这些标记合并到编码器中并不能为编码器提供足够的边界表示。为了克服这一局限性,我们采用一种边界感知预测器,该预测器基于声学表示隐式地预测语言切换。我们利用自注意力池化将编码器输出从帧级声学表示映射到段级声学表示,注意力机制将整个编码器输出作为输入,并输出权重向量A,
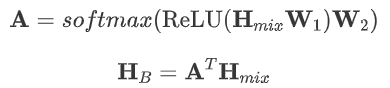
从而得到段级别的声学表示,然后通过解码器得到边界转换的预测计算损失。
实验验证
实验设置
数据 使用ASRU中英混杂语音识别挑战赛的数据(asru700h)[1],包含了200h的混杂音频和500h的中文音频,同时我们使用了Librispeech的460h的英文数据集[2],和论文[3][4]对齐。
模型配置 所有模型基于AED结构:
- 基线模型: 16 层堆叠的conformer层。
- Gating Conformer[3]:2个分离的各八层的conformer层。
- Lae Conformer[5]: 8层共享的conforemer层以及各四层的分离的conformer 单语层。
- Attention Module[4]: 16层堆叠的conformer层,decoder采用特殊的注意力机制。
- BA-MoE: 12层堆叠的 MoE-Adapter 层。
所有模型的decoder均是6层堆叠的Transformer。
指标 中文部分采用字错误率(CER),英文部分采用词错误率(WER),整体采用混合错误率(MER),同时我们额外设置了边界预测错误率(BER)来判断边界预测的准确性。
实验结果
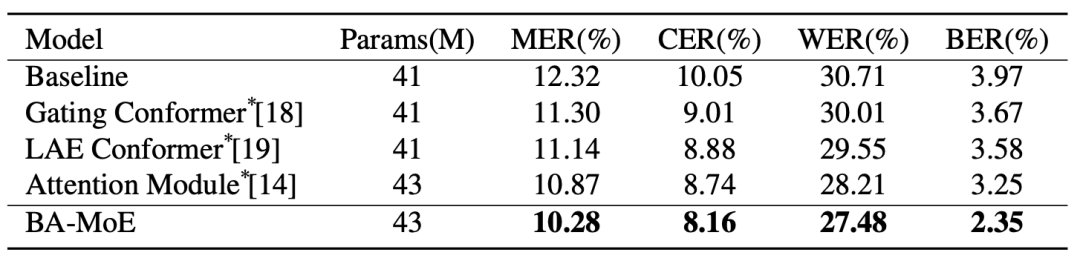
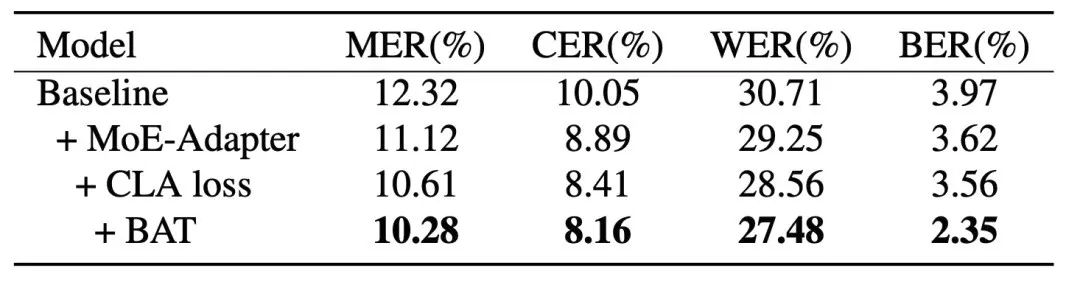
如表1所示,本文提出的BA-MoE方法优于基线,在测试集上的MER相对降低16.55%(12.32% → 10.28%)。与其他方法相比,BA-MoE方在测试集中取得了最低的CER、WER和MER,分别为10.28%、8.16%和27.48%。该方法在具有相似参数预算的其他方案中具有优越性。就边界预测而言,BA-MoE方在测试集上带来了40.81%(3.97%→2.35%)的相对BER降低。
表1 各种方法在Test集上的结果(%),*表示复现结果
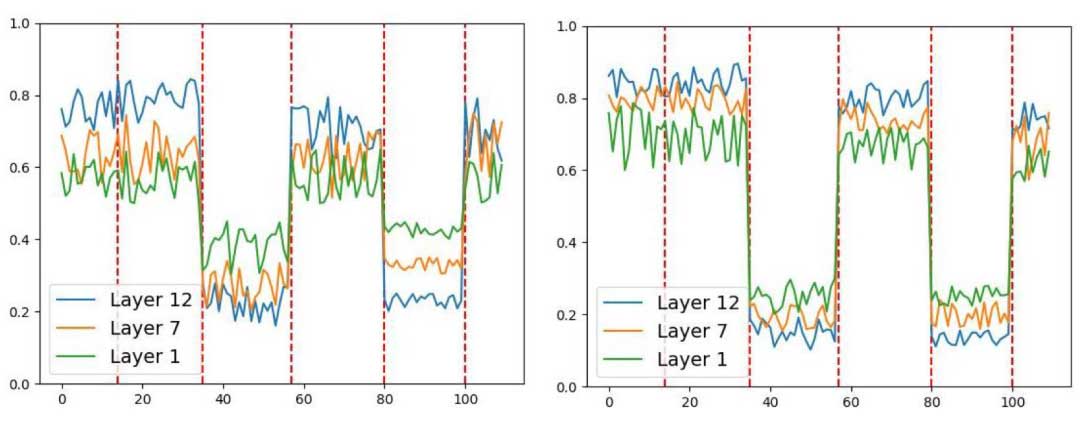
对于CLA,显示了中文在层1、层7和层12的门控网络的权重系数。如图3所示,在没有CLA损失的情况下,适配器对语言特定表示的学习能力有限。然而,由于CLA损失的引入,层的权重系数变得更加明显,表明适配器捕捉语言特定特征的能力得到了提高。这突出了CLA损失在增强适配器学习语言特定特征的能力方面的有效性。
我们进一步对边界感知学习、适应损失和MoE-Adapter结构进行了消融,结果如表2所示。结果表明,缺少这些组件会削弱模型的识别性能。值得注意的是,MoE-Adapter对整体MER的影响最大(12.32%→11.12%)。这突显了MoE-Adapter在有效建模混杂声学代码转换ASR中的重要性。此外,CLA损失在提高适配器单语建模能力方面起着至关重要的作用,在测试集上带来0.51%(11.12%→10.61%)的绝对MER降低。最后,BAT方法通过有效地检测语言边界,成功地实现0.33%(10.61%→10.28%)的绝对MER降低。
表2 消融实验在Test集上的结果(%)
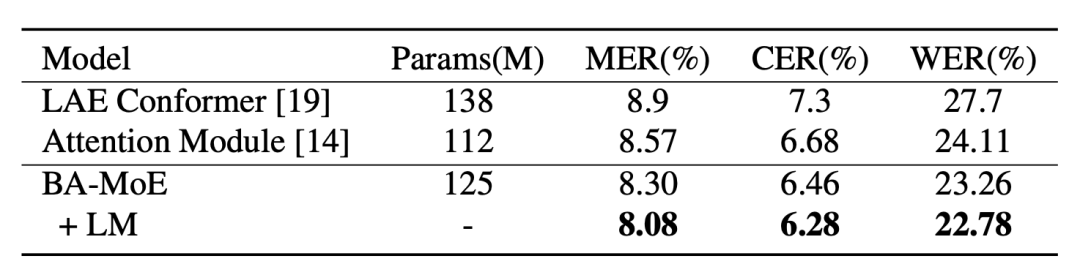
由于ASRU 2019 中英混杂挑战数据集上具有竞争力的方法的模型大小不同,我们增加了模型大小,以便与这些方法进行公平比较。针对本文提出的BA-MoE,我们将注意力维度、前馈维度和注意力头数分别固定为512、8和1024,模型大小与其他两种对比方法相似,如表3所示。我们进一步将语言模型(LM)集成到BA-MoE模型中,以提高语言泛化能力,这在测试集上带来了2.6%的相对MER降低。最终,我们的方案实现了0.5%的绝对MER下降(8.57%→8.08%)。
表3 大参数量模型在ASRU2019中英混Test集上的结果(%)
参考文献
[1] Xian Shi, Qiangze Feng, and Lei Xie, “The ASRU2019 mandarin-english code-switching speech recognition challenge: Open datasets, tracks, methods and results,” CoRR, vol. abs/2007.05916, 2020.
[2] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur, “Librispeech: an asr corpus based on public domain audio books,” in Proc. ICASSP. IEEE, 2015, pp. 5206–5210.
[3] Yizhou Lu, Mingkun Huang, Hao Li, Jiaqi Guo, and Yanmin Qian, “Bi-encoder transformer network for mandarin-english code-switching speech recognition using mixture of experts.,” in Proc.Interspeech. ISCA,2020, pp. 4766–4770.
[4] Zhuai Zhang, Jiangyan Yi, Zhengkun Tian, Jianhua Tao, Yu Ting Yeung, and Liqun Deng, “Reducing language context confusion for end-to-end code-switching automatic speech recognition,” CoRR, vol. abs/2201.12155, 2022[5] Tinchuan Tian, Jianwei Yu, Chunlei Zhang, Chao Weng, Yuexian Zou, and Dong Yu, “Lae: Language-aware encoder for monolingual and multilingual asr,” in Proc.Interspeech. ISCA, 2022, pp. 3178–3182.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
