
创建与个人用户的愿望和偏好紧密结合的个性化视觉表示仍然具有挑战性。这个过程需要用户用可以被模型理解的语言表达他们的想法,这给许多用户带来了困难。在本文中,作者通过利用用户与系统的历史交互来增强用户提示以应对这一问题。基于收集自3115个用户的超过30万条提示的新收集的大规模文生图数据集,作者提出了一种涉及重写用户提示的新方法。作者的重写模型增强了用户提示与其预期视觉输出的表现力和一致性。
题目: Tailored Visions: Enhancing Text-to-Image Generation with Personalized Prompt Rewriting
作者: Zijie Chen, Lichao Zhang, Fangsheng Weng, Lili Pan, Zhenzhong Lan
论文地址: https://arxiv.org/abs/2310.08129
来源:arxiv
代码地址: https://github.com/zzjchen/Tailored-Visions
内容整理:张俸玺
引言
当前,我们正在通过自监督学习的方式来训练越来越强大的基础模型。这些大型预训练模型(LPM)充当高效的压缩器,压缩大量互联网数据。这种压缩使得我们可以通过自然语言描述方便地提取这些模型中编码的知识。尽管还处于起步阶段,但这种方法显示出超越传统搜索引擎的潜力,成为知识和信息获取的优质来源。与改进搜索引擎的查询类似,提供给LPM的提示(Prompt)也必须精心设计。然而,与传统搜索引擎相比,提示的复杂性、模型响应的不可预测性带来了独特的挑战。为了理解LPM如何对各种提示做出反应,一些研究检验了重写提示以提高特异性的可行性。然而,在无法访问用户个人数据和行为的情况下,定制提示以准确满足用户的需求仍然具有挑战性。
本文中,作者通过将用户偏好信息集成到即时重写中来解决这个问题。个性化查询重写的主要障碍是缺乏包含带有个性化信息的文生图提示数据集。为了克服这个问题,作者收集了一个大型数据集,其中包含来自3115位用户的超过30万条文生图的历史记录。尽管对个人信息的访问权限有限,作者还是使用用户的查询历史记录重写了用户提示,为进一步研究留下了空间。另一个重大挑战是评估重写的查询。为了评估其功效,作者开发了一种新的离线方法,该方法使用多个指标来衡量重写模型从ChatGPT缩短版本恢复原始用户查询的效果。
本文的主要贡献有三:1.作者编译了一个大型个性化图像提示数据集(PIP),该数据集将很快开源。2.作者尝试了两种查询(query)重写技术,并提出了一种新的查询评估方法来评估它们的性能。3.作者提出了个性化文本到图像生成的新基准,促进了该领域的标准化。

PIP数据集
数据集收集
个性化图像提示数据集(PIP)是第一个大规模个性化生成的图像文本数据集。原始数据是从作者托管的公共网站收集的,以提供面向用户的开放域文本到图像的生成。为了构建PIP,作者选择了来自3115个用户,使用SD v1-5的内部微调版本构建的30万个图像提示对。数据集仅包含了创建十八个及以上图像或提供至少12个不同提示的用户。
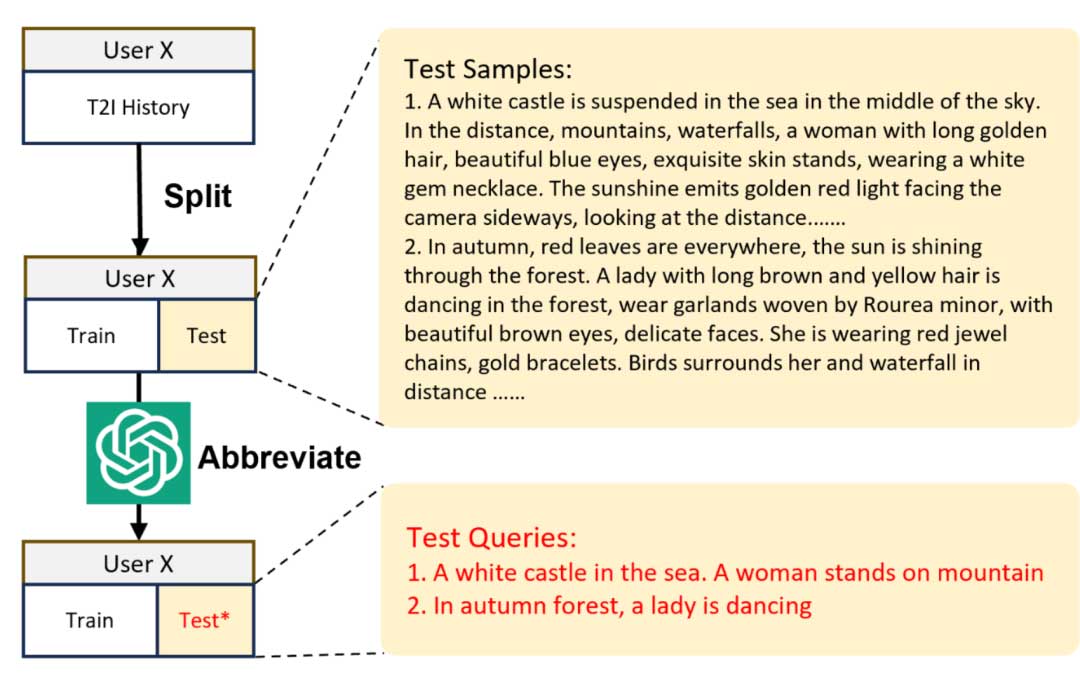
图2说明了创建数据集的过程。对于每个用户,作者随机选择两个提示作为测试提示,其余提示分配为训练提示(历史用户查询)。使用随机选择而不是最近生成的提示的目的是增强本数据集测试数据的多样性。随后,作者使用ChatGPT来压缩测试提示,确保它们仅包含主要对象或场景,如图2所示。作者将提示缩短为三个等级,即分别仅包含名词、名词短语或短句。接下来的实验中,测试集中的每个测试提示将被视为每个用户u的输入提示xt,将原始提示作为反映用户真实偏好的基本事实。剩余的提示则用作训练样本。
PIP数据集由30万个图像提示对组成,根据3115位用户进行个性化分类。这些图像提示对被分为294007个训练样本和6230个测试样本。
用户偏好评估
对于PIP数据集中的每个用户u,作者使用ChatGPT将他们的偏好Pu从其历史提示中总结为五个单词或短语。
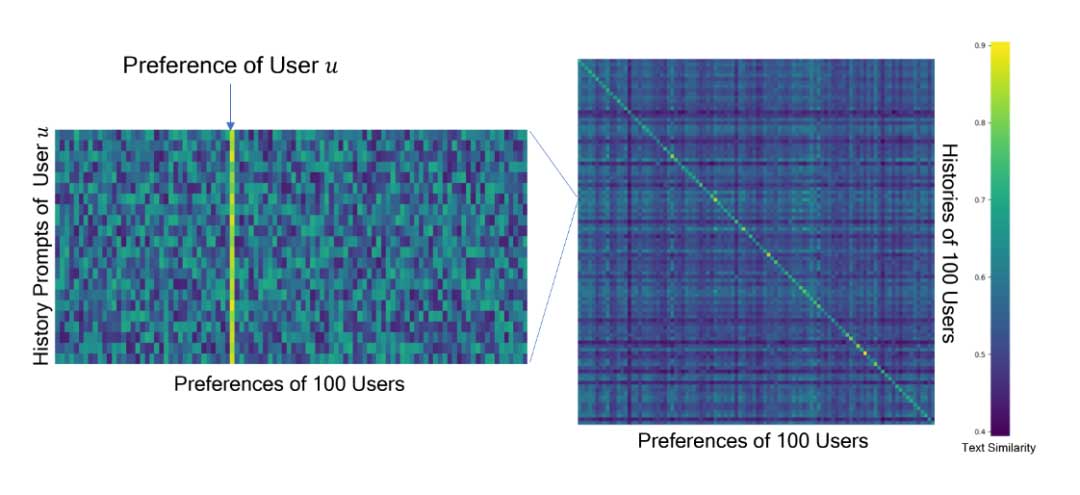
如图3所示,作者可视化了100个用户的历史和偏好之间的文本相似度。对于两个用户u、v,u 的历史和v的偏好的相似度被定义为u的历史提示和的v偏好Pv之间文本相似度的均值。作者使用GTR-T5-large计算文本相似度。此外,图6左侧的图可视化了随即用户的历史提示和100个用户偏好之间的文本相似度。这表明文生图用户具有不同的偏好,并且作者总结的偏好Pu成功地捕获了用户偏好的关键特征。基于这一观察,作者提出了两个指标来评估提示重写方法,即重写结果如何与用户偏好对齐,即偏好匹配分数(PMS)和图像对齐。
偏好匹配分数(PMS):PMS计算生成的图像和用户Pu偏好之间的CLIPScore。它衡量生成的图像如何和用户的偏好保持一致。

图像对齐:它测量生成的图像和真实图像(Ground Truth)之间的相似度。图像对齐量化当前创建的图像与用户真正保存的图像的对齐程度。使用CLIP计算两幅图像之间的相似度。
除了这些指标之外,作者还在实验中采用ROUGE-L来评估即时重写方法。计算重写提示与原始提示之间的ROUGE-L可以衡量提示重写方法恢复原始提示的能力。
个性化提示重写

检索和排序
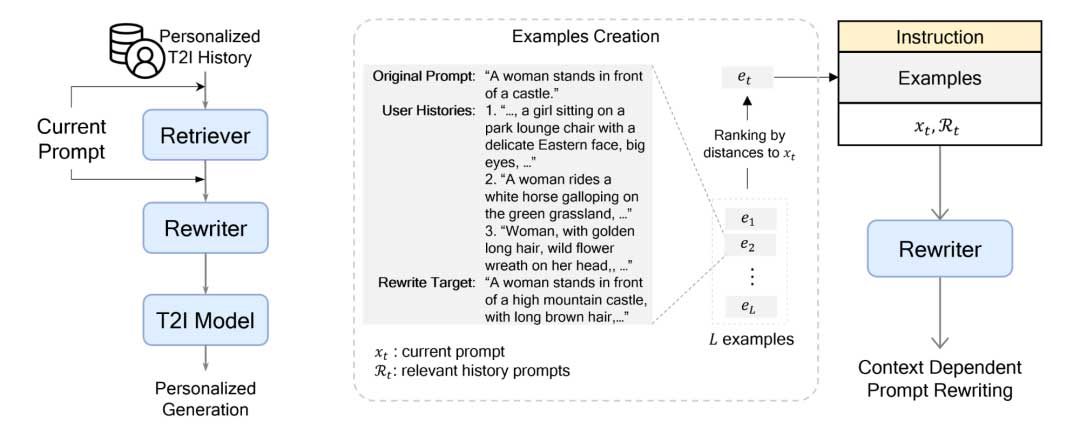
在检索阶段,给定输入提示xt,检索器Ret(xt,Qt)使用xt作为查询从历史提示集Qt中检索相关提示。
通过分析用户提示,作者注意到用户倾向于构建涉及对象、对象属性以及对象之间关系的提示。在先前的研究中,图像检索的查询被定义为包括对象、对象的属性以及对象之间的关系。受此启发,作者怀疑用户有使用属性和某些对象(例如背景)来表达他们的偏好的习惯。为了证实这一点,作者将所有用户的文本提示中出现频率最高的250 个单词的词云可视化,如图5所示。在图5中,作者发现了一些属性,例如“可爱”、“金色”、“美丽”等出现频率较高的提示,以及一些物体,如“山”、“海”、“天空”。直观上,作者可以利用当前提示来定位包含相似属性的相关历史提示。

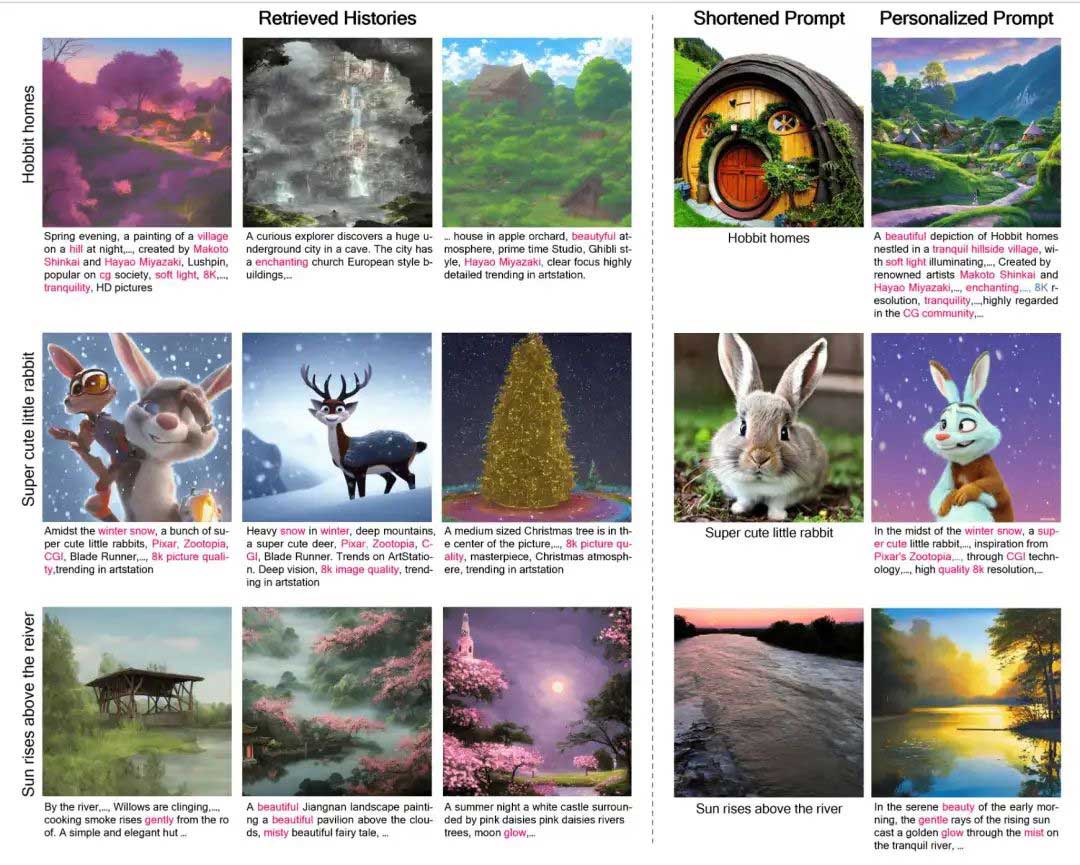
为了定位相关提示,本文使用了两种检索方法:密集和稀疏。在密集检索中,作者选择提示xt并使用CLIP的文本编码器(也是稳定扩散(SD)中的文本编码器)计算其文本嵌入Em(xt)。作者怀疑具有相似视觉属性和对象的提示在文本嵌入空间中会彼此接近。为了证实这一点,作者在图6中可视化了一些检索结果。Em(xt)的三个最近邻居是语义相关的提示。例如,如果输入提示是“霍比特人之家”,则三个最相关的提示将包括单词“村庄”、“城市”和“房屋”。这种密集检索方法也称为基于嵌入的检索(EBR)。在稀疏检索中,作者使用BM25来定位包含相同视觉属性和对象的相关提示。
在上面的检索中,作者根据检索方式对相关提示进行基于EBR或基于BM25的排序。在基于EBR的排序中,作者根据相关提示与查询xt的嵌入相似度对相关提示进行排序。对于相似度测量,作者选择余弦相似度,因为它是嵌入学习中常用的相似度测量。在基于BM25的排序中,BM25分数用于相似性度量。因此,作者可以获得前k个相关用户查询Rt(r1,…,rk)。
重写
与上下文无关的重写过程利用相关查询Rt=(r1,…,rk),采用ChatGPT封装用户偏好并直接重写提示。这些查询Rt根据它们与xt的相关性进行组织。
在上下文相关的场景中,作者首先利用手工设计创建一组演示示例 ε = (r1, . . . , rk)。然后,作者选择这些示例的一小部分作为每个重写任务的演示。考虑到上下文学习中的顺序敏感性问题,作者根据演示示例与输入提示的接近程度按降序排列。本文采用的上下文重写过程如图 4的右侧部分所示。
实验
作者在PIP数据集上进行了快速重写方法的实验。通过离线和在线评估的方法来验证作者所提出方法的有效性。作者进一步分析了历史提示的数量,以便通过消除顶部检索来最好地提取用户的偏好。
对于离线评估,作者使用了上述三个指标:PMS、Image Align和ROUGE-L。对于在线评估,作者对网站上最近活跃的用户进行了单盲实验。收集真实的用户反馈来评估作者所提出的方法。
实现细节
本文提出的个性化提示重写方法的详细信息如下。在检索中,作者选择文本提示编号为 k = 3。作者使用ChatGPT作为重写器。表1显示了与上下文无关的重写的输入模板。对于与上下文有关的重写,作者设置L = 5 并针对每个重写任务随机选择一个演示示例,除非另有规定。
除非另有说明,所有实验均使用EBR检索历史提示,并使用一次性上下文学习来重写缩短的提示。作者使用稳定扩散(SD)v1-5作为所有方法的文本到图像生成模型。SD v1-5使用PNDM调度程序分50个步骤进行采样,并将无分类器指导尺度设置为7.0。

结论
总而言之,本项研究强调了利用用户历史行为构建个性化人工智能内容生成的重要性。作者的策略是通过利用用户与系统以前的交互来完善用户提示。作者引入了一项新技术,该技术需要根据新开发的大规模文生图数据集重新配置用户提示。该数据集包含来自3115个不同用户的超过30万个提示组成。事实证明,这种方法可以增强用户提示的表现力,并确保它们与所需的视觉输出保持一致。实验表明,该模型在离线评估和在线测试方法中较传统方法而言具有优势。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
