
微服务是指一种软件架构风格,其中应用程序被开发为小型独立服务的集合,每个服务都在自己的进程中运行,并与轻量级机制(通常是基于 HTTP 的 API)进行通信。这种方法与传统的整体架构形成鲜明对比,传统的整体架构将应用程序构建为单个统一的单元。微服务变得越来越复杂,给传统的性能监控解决方案带来了新的挑战。一方面,微服务的快速演进给现有分布式追踪框架的使用和维护带来了巨大的负担。另一方面,复杂的基础设施增加了网络性能问题的概率,并在网络侧产生更多盲点。
题目:Network-Centric Distributed Tracing with DeepFlow
来源:ACM SIGCOMM 2023
链接:https://dl.acm.org/doi/abs/10.1145/3603269.3604823
作者:1.Institute for Network Sciences and Cyberspace, Tsinghua University 2.Yunshan Networks 3.Department of Computer Science and Technology, Tsinghua University 4.Zhongguancun Laboratory
内容整理:胡玥麟
任务
本文提出了 DeepFlow,一种以网络为中心的分布式跟踪框架,用于排除微服务故障。DeepFlow 通过以网络为中心的跟踪平面和隐式上下文传播提供开箱即用的跟踪。此外,它消除了网络基础设施中的盲点,以低成本的方式捕获网络指标,并增强了不同组件和层之间的关联性。DeepFlow 能够节省用户数小时的仪器工作,并将故障排除时间从几个小时缩短到几分钟。
动机
大规模在线服务已经脱离了单体应用的阶段。由于解耦,分布式系统比单体系统具有更好的可扩展性、灵活性和可用性。然而,高度脱钩是一把双刃剑。由于组件交互的异构性和复杂性,给分布式系统的运维带来了压力,特别是在微服务架构下开发和部署的分布式系统。为了克服分布式系统中性能调试的挑战,最先进的解决方案,也称为分布式跟踪,尝试通过添加检测代码来获取执行持续时间和因果关系到不同的组件。
现有的框架无法满足微服务带来的新需求。
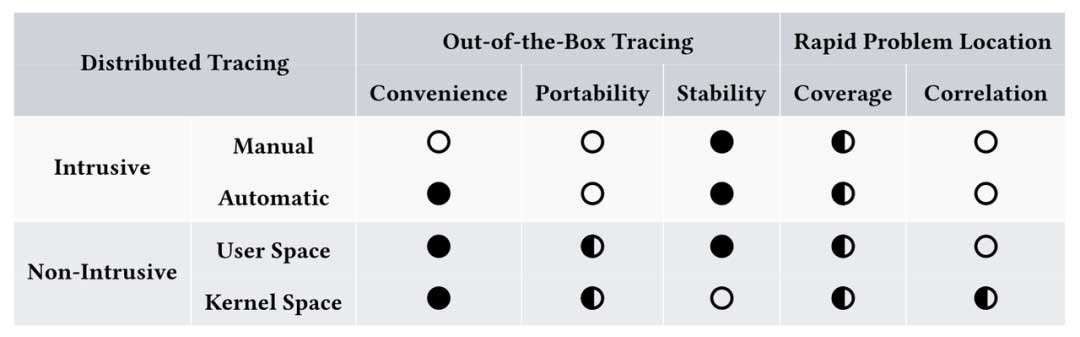
侵入式框架通过修改目标组件的源代码来实现分布式跟踪。尽管侵入式框架具有广泛的跟踪功能,但它们提供的信息不足以定位性能问题。
非侵入式分布式跟踪框架。为了避免修改,通过捕获微服务组件的外部交互接口来实现非侵入式追踪。无法同时提供快速问题定位和即用的跟踪。
综上所述,现有的侵入式或非侵入式框架各有优点,但无法同时提供便利性、可移植性、稳定性、覆盖性和关联性。
挑战
- 现有的传统框架对于快速发展的微服务来说效果不佳、效率低下。
- 传统方法忽略网络信息,只记录应用程序级别的痕迹。
- 现有的跟踪技术忽略了物理或虚拟网络信息,使得在这种情况下根本原因分析变得更加困难。
贡献
本文通过引入 DeepFlow(一种专门针对微服务的分布式跟踪框架)来解决上述挑战。DeepFlow 通过以下设计促进即时的跟踪和快速性能问题定位:
1:基于微服务是由网络通信触发的洞察,DeepFlow 设计了一个以网络为中心的跟踪平面。在其以网络为中心的窄腰检测模型中,预定义的内核挂钩用于执行自动和非侵入式跟踪。DeepFlow 利用特权内核空间来消除闭源组件和网络基础设施造成的盲点。(3.2节)
2:DeepFlow 提出了一种隐式上下文传播技术来实现开箱即用的跟踪并避免将标识符插入数据包。系统自动利用仪器阶段收集的信息来构建组件的使用寿命。之后,我们使用各种网络和系统信息将跨度组装成轨迹。(3.3节)
3:DeepFlow 使用基于标签的相关性来提供指标和跟踪之间的连接。在这些标签的帮助下,用户可以检查与跟踪相关的网络/组件指标,从而加速根本原因分析。(3.4节)
提出方法
DeepFlow的高级设计目标:
- 目标1:使用方便。首先,用户不需要确定在哪里进行检测。其次,用户可以在不直接修改代码的情况下检测目标组件。
- 目标2:维护简单。首先,开发人员不需要为不同的语言或应用程序维护同一框架的多个实现或 SDK。其次,开发人员不需要根据内核更改提供同一接口的多种实现。
- 目标3:高精度和覆盖率。DeepFlow 必须确保彻底且准确的追踪。它应该避免闭源组件、云基础设施和底层网络中的盲点。
- 目标4:跨层和跨组件关联。DeepFlow必须具备有效的跨层信息整合能力来建立关联。另一方面,它必须能够关联不同组件提供的数据属性以进行额外的分析。
- 目标5:高性能。DeepFlow 的检测、传输和处理开销必须可以忽略不计,以便在不降低应用程序性能的情况下提供实时分布式跟踪。
DeepFlow 的架构概述
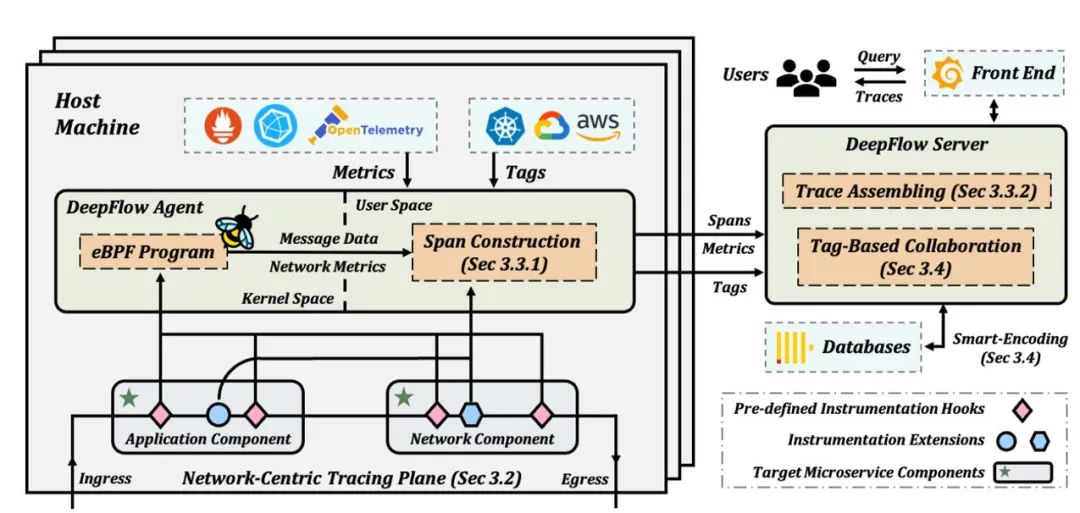
DeepFlow 由两个高级组件组成:代理和服务器。在每个容器节点、虚拟机或物理机中部署代理,以使用预定义的 eBPF 检测挂钩和检测扩展来捕获跟踪数据。此外,Agent还负责集成来自第三方框架或云平台的指标和标签,并将其传输到Server。DeepFlow Server 是一个集群级进程。它负责将 span 存储在数据库中,并在用户查询时将它们组装成trace。
接口级分布式跟踪
选择一组系统调用应用程序二进制接口(ABI)作为基本检测点。选择系统调用ABI而不是库函数使得DeepFlow具有最高程度的开发通用性,即只需要一个框架就可以构建对各种语言和内核版本的支持(目标2)。此外,用户可以通过这些预定义的接口收集主要跟踪数据,而无需适应不同的微服务组件(目标1)。
设计1:具有进出和进出两套功能的窄腰仪表模型
DeepFlow 忽略控制流信息,并将跟踪收集过程基于入口-出口行为。DeepFlow 检测了 10 个系统调用 ABI,并将它们分类为入口或出口。这些 ABI 能够覆盖微服务组件之间的所有数据通信场景(阻塞或非阻塞、同步或异步),同时保持独立于应用程序逻辑和通信协议。

DeepFlow 在进入或退出内核时存储有关每个入口或出口调用的信息。用户空间记录了四类信息以供进一步处理:
- (i) 程序信息,包括进程ID、线程ID、协程ID、程序名称等;
- (ii) 网络信息,包括DeepFlow分配的全局唯一socket ID、五元组、TCP序列等;
- (iii) 追踪信息,包括数据捕获时间戳、入口/出口方向等;
- (iv)系统调用信息,例如读/写数据的总长度、要传输到DeepFlow代理的有效负载等
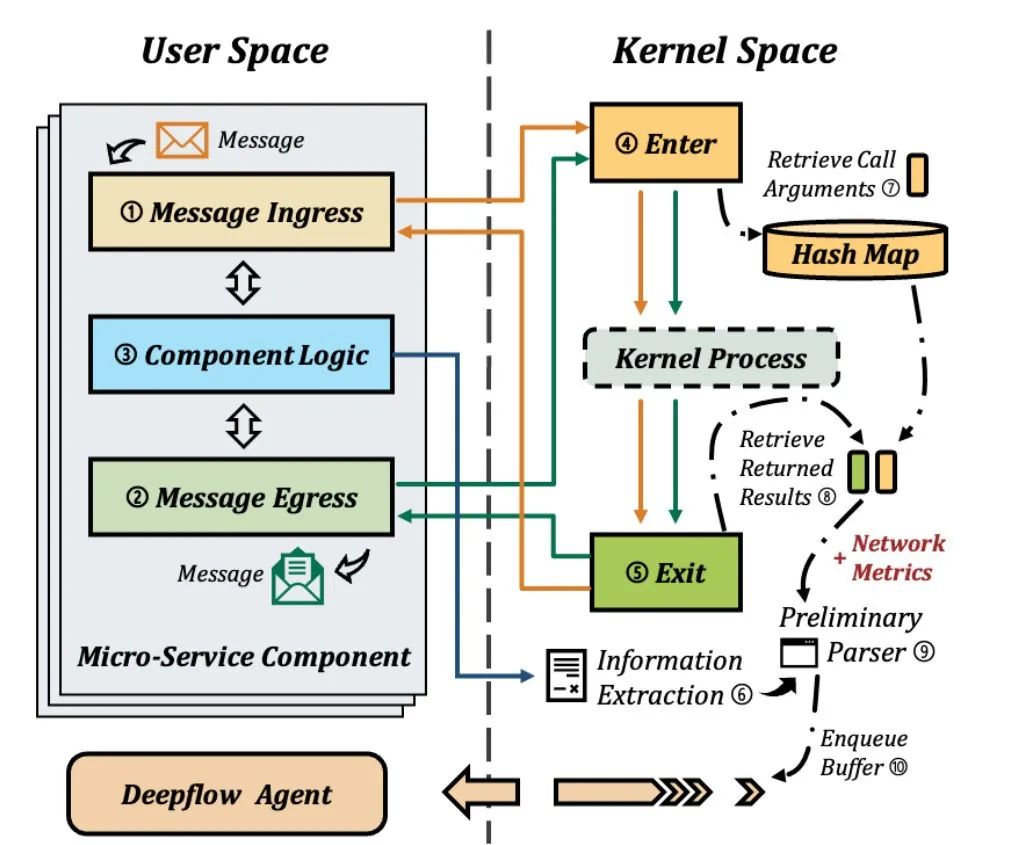
设计 2:基于内核钩的检测(In-kernel hook-based instrumentation)
根据预定义的检测模型,DeepFlow自动注册钩子来收集跟踪数据。对于消息入口(➀)或出口(➁),相应的系统调用将触发注册的kprobe或tracepoint在进入 (➃)和退出(➄)内核时挂钩。跟踪进程将检索参数 (➆),等待内核完成其处理,然后检索返回的结果 (➇)。初步解析器(➈)会将主要数据整合并排队到缓冲区(➉)中,随后将其传输到用户空间进行进一步处理。
隐式上下文传播
DeepFlow 的以网络为中心的跟踪平面可以记录大量监控信息,并消除网络基础设施中的盲点。
设计 3:具有分层聚合的隐式上下文传播。
DeepFlow 通过以下两个阶段将独立的、碎片化的和原始的测量组合成面向请求的跟踪,其中包含精确的因果相关性:
- 从仪器数据构建跨度。
- 使用隐式因果关系从跨度组装跟踪。
DeepFlow 生成的跨度始终以请求开始并以响应结束。DeepFlow 将任何丢失的响应视为意外执行终止导致的结果。
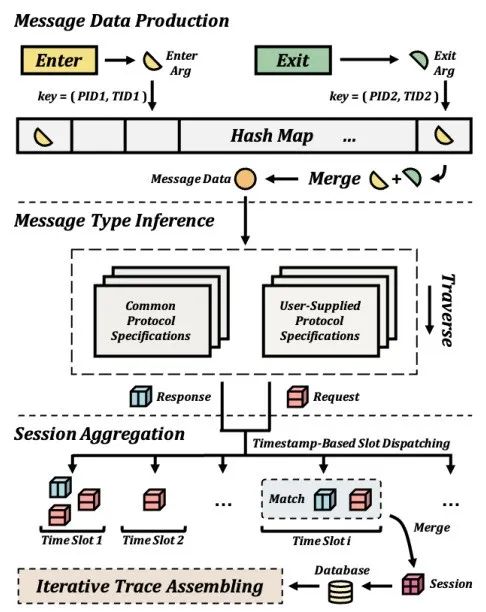
跨度构建过程的三个阶段:消息数据生成、消息类型推断和会话聚合。
首先,DeepFlow 使用Process ID 和Thread ID 将同一系统调用的进入和退出期间捕获的信息关联起来(图 4 中的➆ 和 ➇)。于给定的(Process ID、Thread ID),内核只能同时处理一个选定的系统调用(图3 中列出)。在第二阶段,DeepFlow执行消息协议推理,并使用相关网络信息解析消息及其原始语义。最后DeepFlow 将尝试将同一流中的一个请求和一个响应聚合到会话中。
Trace Assembling 跟踪组装
“span” 指的是在分布式系统追踪中一个特定的操作或任务的执行时间段。DeepFlow 通过利用检测过程中保存的不同网络层的信息来确定跨度span之间的关系。DeepFlow以用户查询的span为起点,合并关联的span。
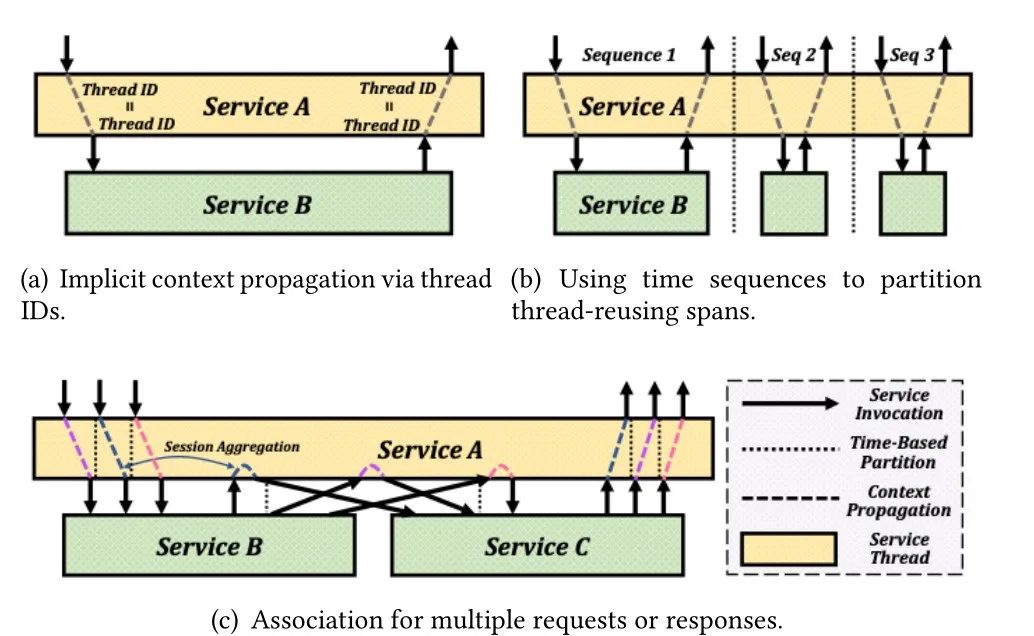
DeepFlow 使用线程 ID 将同一线程内的跨度关联起来(图 6(a))。由于基于线程的微服务组件中内核线程和用户线程之间是1:1的关系,所以这种关联可以在内核中进行。DeepFlow还可以通过跟踪执行过程中协程之间的调用关系来进行关联。其次,当线程被重用时,跟踪将根据时间顺序进行分区(图6(b))。最后,DeepFlow 需要处理多个请求或响应(图 6(c))。
组件内关联
DeepFlow 通常使用线程 ID、时间信息和调度洞察来识别跨度之间的组件内因果关系。相同的 systrace_id 被分配给拥有因果关联的两个范围,用作全局唯一标识符。
DeepFlow计算并记录内核中每个消息的 TCP 序列。然后,它用于区分和维护同一流内跨度的组件间关联。
第三方跨度集成
DeepFlow 可以合并从用户定义的分布式跟踪框架生成的跨度。
自下而上的跟踪组装
DeepFlow并未考虑多个消息缓存在单个数据结构中的场景,从而显着简化了系统调用到消息数据的映射。
使用先前注入的单线程组件内信息(systrace_ids 和伪线程 ID)、跨线程组件内信息(X-Request-ID)、组件间信息迭代聚合跨度信息(TCP 序列)和第三方信息(跟踪 ID)以生成跟踪。

在算法的第一部分,DeepFlow 使用用户指定的迭代次数(默认为 30)搜索数据库。算法的第二阶段跨度集并设置父跨度。
设计4:基于分阶段标签注入的智能编码
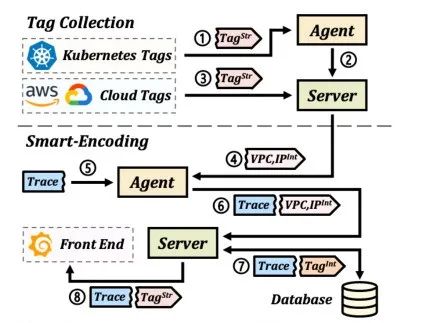
如图 8 所示,DeepFlow 将标签注入过程分为两个阶段:标签收集和智能编码。在标签收集阶段,集群内的 DeepFlow Agent 会收集 Kubernetes 标签 (➀) 并将其发送到服务器 (➁),而云资源标签则由服务器直接收集 (➂)。在智能编码阶段,DeepFlow 仅将 Int 格式的 Virtual Private Cloud (VPC) 标签和 IP 标签注入到迹线中 (➃-➅)。然后,服务器根据 VPC/IP 标签将 Int 格式的资源标签注入到跟踪中,并将其存储在数据库中 (➆)。在查询时,DeepFlow Server 确定自定义标签和资源标签之间的关系,将自定义标签注入到迹线中,然后将带有所有标签的迹线上传到前端(➇)。通过划分标签注入阶段,DeepFlow 减少了计算、传输和存储开销。
实验设计与验证
跟踪收集开销
图 9 显示,预定义 ABI 中引入了范围从 277ns到 889ns 的额外延迟。
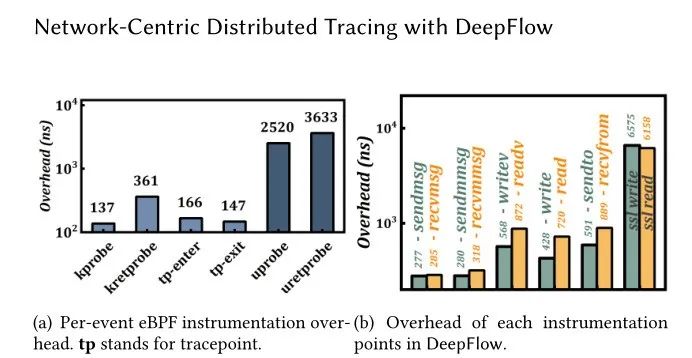
sl_read、uprobe 和 uretprobe 等扩展钩本身会产生 6153ns的延迟。相比之下,DeepFlow 的额外延迟保持在 423 ns以下。
智能编码的有效性
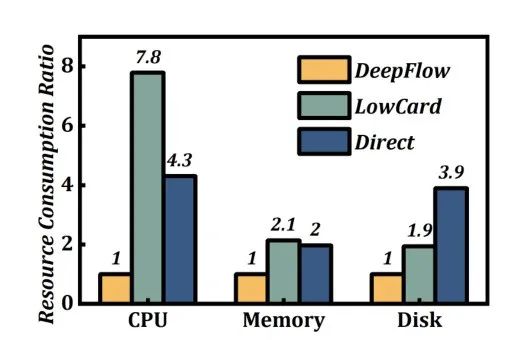
结果如图 10 所示。智能编码使 DeepFlow 在存储过程中仅利用 0.11 个 CPU 核心、1.39% 的主机 RAM(约 800 MB)以及大约 1.4 GB 的磁盘空间。
查询延迟
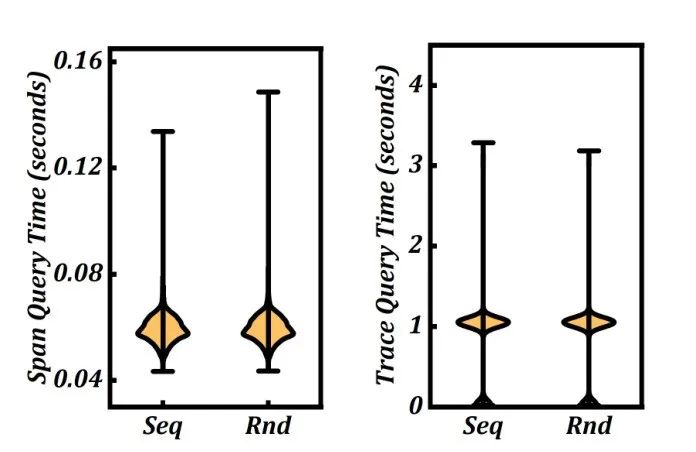
本实验的目的是评估跟踪组装过程的性能。图 11 展示了结果。DeepFlow 可以在大约 1 秒内查询单个迹线,并在大约 0.06 秒内搜索 15 分钟跨度列表。
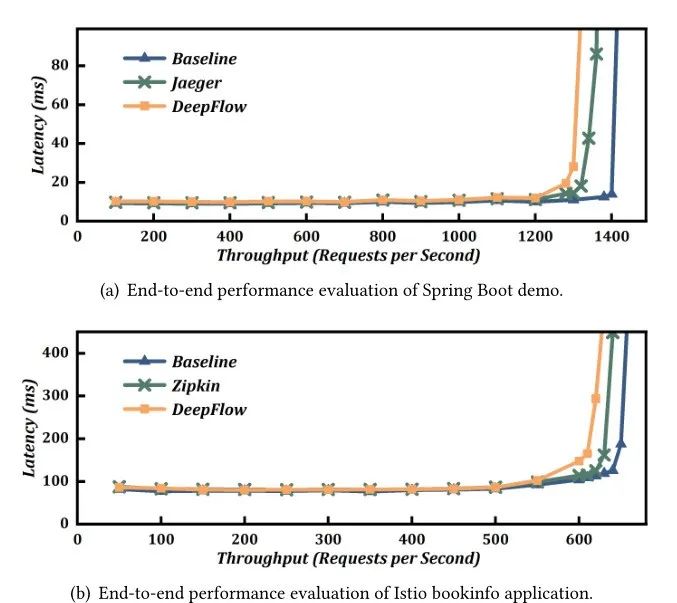
端到端性能
端到端测试的目的是评估 DeepFlow 对现实微服务的性能影响。结果如图 12 所示。在不部署跟踪工具的情况下,Spring Boot 演示的吞吐量约为每秒 1420 个请求 (RPS)。部署 Jaeger 和 DeepFlow 后,吞吐量分别降至 1, 360 RPS 和 1320 RPS,开销分别增加了 4% 和 7%。
启发
DeepFlow,一个面向微服务场景的以网络为中心的分布式追踪架,DeepFlow在内核中使用eBPF建立了一个以网络为中心的跟踪平面。1. 跨多个层收集网络指标,并消除网络基础设施和闭源组件中的盲点。2. 与基于hook的检测方法相结合,使用户能够以零代码执行分布式跟踪。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
