
本文主要讨论了在生成视频模型中数据选择的重要性以及数据筛选对模型性能的影响。文章指出,虽然在视频建模方面的研究主要集中在空间和时间层的排列上,但对于数据选择的影响却鲜有研究,文章通过固定架构和训练方案,对比了不同数据筛选方式对模型性能的影响,并发现预训练在经过精心筛选的数据集上可以显著提高性能。同时文章介绍了一个系统的数据筛选工作流程,将一个大规模的未筛选视频集合转化为适用于生成视频建模的高质量数据集,还提出了一种基于预训练视频扩散模型的多视角生成方法,并与其他专门的新视角合成方法进行了比较。最后,文章探讨了模型的运动和三维理解能力,并进行了相关实验。
来源:Arxiv
论文题目:Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
论文链接:https://arxiv.org/abs/2311.15127
论文作者:Andreas Blattmann,Tim Dockhorn,Sumith Kulal,Daniel Mendelevitch,Maciej Kilian,Dominik Lorenz,Yam Levi,Zion English,Vikram Voleti,Adam Letts,Varun Jampani,Robin Rombach
内容整理:黄海涛
介绍
在图像生成模型技术的推动下,视频生成模型在研究和应用领域取得了显著进展。这些模型通常通过从头开始训练或对预训练图像模型插入额外的时间层进行微调来实现。训练通常在混合的图像和视频数据集上进行。尽管视频建模的改进研究主要关注空间和时间层的排列方式,但先前的工作没有探究数据选择的影响。然而,训练数据分布对生成模型的影响是不可忽视的。此外,对于生成式图像建模,已经知道在大型和多样化的数据集上进行预训练,然后在小型但质量更高的数据集上进行微调,可以显著提高性能。然而,之前的视频建模方法往往借鉴了来自图像领域的技术,而对于数据和训练策略的影响,即在低分辨率视频上进行预训练再在高质量数据集上微调,还需要进一步研究。
本文的研究解决了这些未知领域中的问题。作者认为,尽管数据选择对于大规模训练视频模型的重要贡献已被广泛接受,但其代表性仍存在严重不足。因此,与以前的工作相比,本文使用了简单的潜在视频扩散基线,并对其架构和训练方案进行了修复,同时评估了数据筛选的效果。为此,作者首先确定了三个重要的视频训练阶段,即文本到图像的预训练、低分辨率大数据集上的视频预训练以及高分辨率视频微调在小且高质量数据集上。借鉴大规模图像模型训练的方法,作者引入了一种系统化的视频数据管理方法,并实证研究了其在视频预训练中的效果。
本文主要研究结果表明,在精心选择的数据集上进行预训练可以显著提升性能,并且在经过高质量微调后仍然有效。基于这些发现,作者将策展方案应用于一个包含约6亿个样本的大型视频数据集,并训练了一个强大的预训练文本到视频基础模型,该模型提供了通用的运动表示。利用这一点,作者在较小的高质量数据集上微调基础模型,用于高分辨率下游任务,如文本到视频和图像到视频,其中作者从单个条件反射图像中预测一系列帧。人类偏好研究显示,本文的模型优于先进的图像到视频模型。此外,还证明了模型提供了强大的多视图先验,可作为微调多视图扩散模型的基础,并且优于专门的新颖视图合成方法。最后,本文的模型允许显式的运动控制,通过特定的运动提示时间层,并通过在类似特定运动的数据集上训练 lora 模块来有效地将其插入模型中。
为高质量视频合成策划数据
作者介绍了在大型视频数据集上训练最先进的视频扩散模型的一般策略。
第一阶段:图像预训练,即2D文本到图像的扩散模型
第二阶段:视频预训练,在大量视频上进行训练。
第三阶段:视频微调,以更高分辨率在一小部分高质量视频上对模型进行细化。
数据处理和注释
作者收集了一个长视频的初始数据集,用作视频预训练的基础数据。为了避免将切割和淡出的部分泄漏到合成视频中,使用了切割检测管道对数据集进行处理。通过应用切割检测管道,获得了更高数量的视频剪辑,表明未处理数据集中的许多视频剪辑包含了来自元数据之外的剪辑。然后,通过对每个片段使用三种不同的合成字幕方法进行了注释,并生成了剪辑的说明。最终形成的初始数据集被称为大型视频数据集(LVD),由580M个带注释的视频片段组成,覆盖了212年的内容。
然而,进一步的调查表明,结果数据集中的一些示例可能会降低最终视频模型的性能,如运动较少的片段、过多的文本存在或普遍较低的审美价值。因此,额外使用密集光流注释了数据集,并通过过滤掉静态场景中任何平均光流幅度低于某一阈值的视频来进行处理。通过考虑数据集中片段的运动分布,识别了一个接近静态的子集。此外,作者还应用了光学字符识别来排除包含大量文字的片段,使用CLIP嵌入和美学分数以及文本-图像相似性对每个片段的第一帧、中间帧和最后帧进行了注释。文章提供了数据集的统计数据,包括剪辑的总大小和平均持续时间。
第一阶段:图像预训练
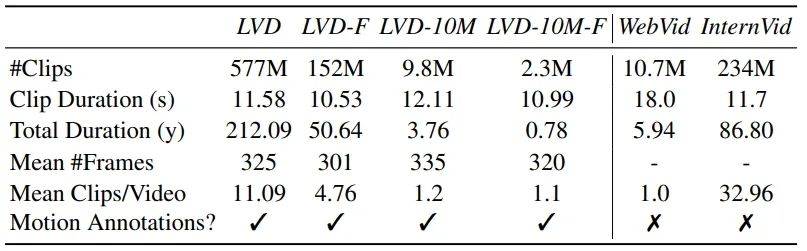
文章将图像预训练作为训练管道中的第一阶段。因此,使用一个预训练的图像扩散模型(即 Stable Diffusion 2.1)作为初始模型,以给它提供强大的视觉表达能力。为了分析图像预训练的效果,作者在LVD的一个1000万子集上训练和比较了两个相同的视频模型,一个使用预训练的空间权重,一个不使用,通过人类偏好研究对这些模型进行了比较,如图清楚地表明图像预训练的模型在质量和迅速跟随方面更受人们的偏好。
第二阶段:策划一个视频预训练数据集
作者通过系统性地策划视频数据集来改进视频扩散模型的训练效果。在多模态图像建模中,数据策划是许多强大模型的关键要素。但在视频领域,没有一种顺畅的方法来过滤掉不需要的示例。因此,需要依赖人们的偏好来创建适合的预训练数据集。具体而言,通过使用多种方法对LVD数据集的子集进行筛选,并根据人类偏好对预训练数据集进行排序。
首先,根据CLIP(分数、美学分数、OCR检测率、合成字幕和光流分数进行策划,从未经筛选的LVD-10M子集开始,系统性地移除底部百分之12.5、25和50的示例。对于合成字幕,使用Elo排名方法进行筛选。通过比较相同类别的所有模型的人类偏好投票结果,选择每种注释类型的最佳筛选阈值。
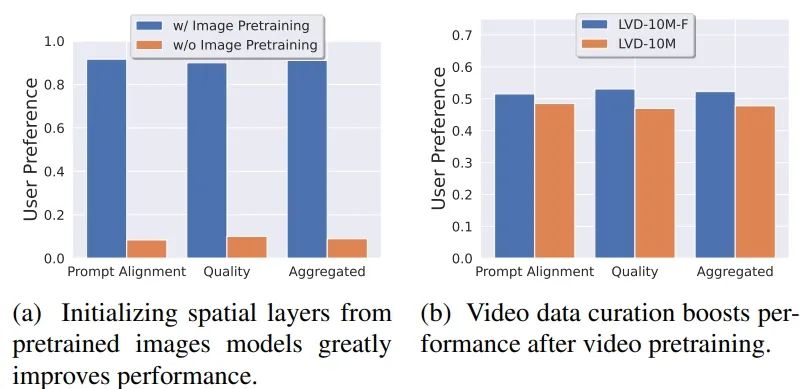
经过筛选后,得到了一个152M个训练示例的预训练数据集,称为LVD-F。这样的筛选方法使得训练模型更受偏好。通过比较在LVD-10M-F和未经筛选的LVD-10M上训练的模型的视觉质量和迅速视频对齐的偏好分数来验证策划的有效性。结果表明,经过策划的模型更受偏好。
最后,作者还发现数据集的大小在训练策划数据时也起到关键作用。使用LVD-50M-F样本训练的模型相比于使用相同步骤数训练的LVD-10M-F模型,在视觉质量和对齐度方面表现更好。

第三阶段:高质量微调
为了分析视频预训练对最后阶段的影响,作者微调三个完全相同的模型,它们只在初始化时有所不同。将第一个模型的权重初始化为预训练的图像模型,并跳过视频预训练,这是最近许多视频建模方法中常见的选择。剩下的两个模型使用前一节中基于50M经过策划和未策划的视频剪辑训练的潜在视频模型的权重进行初始化。作者将所有模型微调50K个步骤,并在微调早期(10K个步骤)和最后评估人类偏好排序,以衡量性能差距在微调过程中的进展。上图(e)展示了所得结果,其中绘制了相对于以图像模型初始化的最后一个排名模型的用户偏好的Elo改进。此外,基于经过策划的预训练权重的微调始终比基于未经策划训练的视频权重进行初始化的模型排名更高。
根据这些结果可以得出以下结论:
(i)在视频预训练和视频微调中分离视频模型训练对微调后的最终模型性能有益。
(ii)视频预训练应该在大规模的经过筛选的数据集上进行,因为预训练后的性能差异在微调后仍然存在。
大规模训练视频模型
高分辨率文本到视频模型
将基础的文本到视频模型微调在一个高质量的视频数据集上,该数据集包含大约1M个样本。数据集中的样本通常包含大量的物体运动、稳定的相机运动和对齐良好的字幕,并且视觉质量较高。作者将基础模型在分辨率为576×1024的情况下进行了50k次迭代的微调。

高分辨率图像到视频模型
除了文本到视频之外,作者还对基础模型进行了图像到视频生成的微调,其中视频模型接收静止的输入图像作为条件。因此,将输入到基础模型的文本嵌入替换为条件图像的CLIP图像嵌入。

相机运动的Lora
为了在图像到视频生成中实现可控制的相机运动,作者在模型的时间注意力块中训练了各种相机运动的LoRAs参数,使用一个包含丰富相机运动元数据的小数据集来训练这些额外的参数。具体而言,作者使用了三个数据子集,其中相机运动被归类为”水平移动”、”缩放”和”静止”。

多视角生成
为了同时获取对象的多个新视角,作者在多视角数据集上微调了图像到视频的SVD模型。
数据集: 作者在两个数据集上微调了SVD模型,其中SVD模型接收一张单独的图像并输出一系列的多视角图像:(i) Obja verse的一个子集,包含了来自原始数据集的150k个经筛选和CC许可的合成3D对象。对于每个对象,使用随机采样的HDRI环境贴图和仰角在[-5°,30°]之间渲染了21帧的360°轨道视频。在一个未见过的测试数据集上评估生成的模型,该测试数据集由来自Google扫描对象(GSO)数据集的50个样本对象组成。以及(ii) MVImgNet,其中包含了随意拍摄的一般家用物品的多视角视频。将视频分割为约200k个训练视频和900个测试视频。
模型: 作者将微调后的多视角模型称为SVD-MV。对SVD的视频先验在多视角生成中的重要性进行了消融研究。为此,将SVD-MV的结果与从图像先验微调的文本到图像模型SD2.1(SD2.1-MV)以及没有先验的随机初始化训练的模型(Scratch-MV)进行了比较。此外,作者还将其与当前最先进的多视角生成模型Zero123、Zero123XL和SyncDreamer进行了比较。
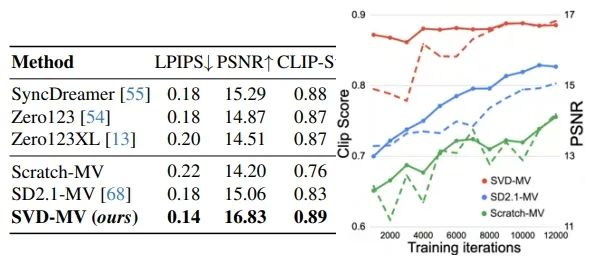
度量标准: 在50个GSO测试物体上使用峰值信噪比(PSNR)、LPIPS和CLIP-S作为地面真实帧和生成帧之间对应对的标准度量指标。
下图显示了在GSO测试物体上进行多视角生成的定性比较结果和在MVImgNet测试物体上进行多视角生成的结果。正如可以看到的那样,生成的帧具有多视角的一致性和逼真性。


总结
本文提出了稳定视频扩散模型(SVD),这是一个用于高分辨率、最先进的文本到视频和图像到视频综合的潜在视频扩散模型。为了构建其预训练数据集,作者进行了系统性的数据选择和缩放研究,并提出了一种方法来策划大量的视频数据,将大而嘈杂的视频收藏转化为适合生成视频模型的数据集。此外,引入了视频模型训练的三个不同阶段,通过分别进行分析,评估了它们对最终模型性能的影响。SVD模型提供了一个强大的视频表示,通过微调视频模型可以实现最先进的图像到视频综合以及其他非常相关的应用,如用于相机控制的LoRAs。最后,本文对视频扩散模型的多视角微调进行了开创性的研究,并表明SVD构成了一个强大的三维先验,在多视角综合方面取得了最先进的结果,而只使用了之前方法的一小部分计算资源。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
