
01 背景介绍
B站的 CDN 下行边缘节点过去是非集群化架构。这种架构下有几个弊端:
- 增加调度逻辑复杂性;
- 同机房流量/负载难以均衡;
- 暴露过多的公网IP,增加安全隐患 (盗链等);
- 灰度流量比例分配粒度大;
针对以上问题,我们调研了常见的四层负载均衡器, 传统的 SLB,LVS,DPVS 这类四层负载均衡器,在功能上也能满足我们现有的需求。但是以上几个负载均衡器均需要独占机器,进而造成成本升高,资源浪费。
有没有一种既不增加成本,又能解决边缘节点四层负载需求的方案呢?由 Cloudflare 提出的基于 Express Data Path (XDP) 的高性能四层负载均衡器 Unimog[1]性能优异,并且可以和后端服务同机部署,在性能上也完全满足我们边缘场景的要求。所以我们参考 Cloudflare Unimog 的思想,在其基础上自研了适用于B站的边缘四层负载均衡器 Nickel (以下简称 Ni) 。
- 与业务服务同机部署,更划算;
- 只保留业务需要功能,更轻量;
- 可针对业务特点优化,更灵活;
目前已部署在自建动态加速,及自建点直播 CDN 集群化生产环境中。其支持与后端服务同机部署,底层使用 XDP、Traffic Control (TC) 进行包粒度转发,支持 Direct Server Return (DSR) 模式,支持根据 CPU/QPS (或其他业务维度) 动态调整流量分配。
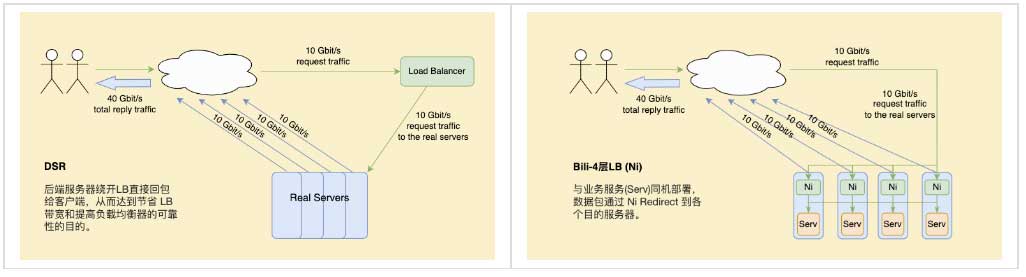
下面左图为传统 DSR 模式,右图为自研负载均衡器 Ni 的 DSR 模式,不需独占资源,支持与服务同机部署,更符合边缘场景。
02 架构设计
2.1 总体设计
四层负载均衡器 Ni 由两部分组成,控制面和数据面。控制面主要负责服务发现、配置管理、数据上报,及LB规则的动态维护等。数据面主要由 LoadBalance (XDP) , Redirect (TC Traffic Control) 等模块组成,主要用来负责数据包的转发。控制面和数据面根据预定义的接口传输数据。
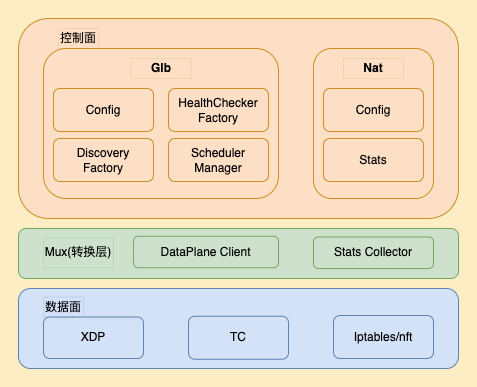
开始介绍之前先明确几个下文中用的到名词及其意义:
- VIP (virtual IP) :用于统一接受用户请求,代表当前集群流量入口,下文中VIP指LB所在机器的IP(目前边缘没有支持真正虚拟IP的建设)。
- DIP (direct IP) :业务服务所在机器的 IP。
2.2 控制面
控制面基于开源框架 kglb[2] 结合边缘网络特点做的改造和开发,其核心为生成和维护供数据面使用的转发表。为了保证转发表的数据的正确性、实时性、高效性,控制面使用以下几个功能和模块更新信息:
- 服务发现、管理
Ni 控制面需要维护同集群边缘节点的所有服务器信息 (VIP,DIP,Hostname,运营商,权重等),以及需要感知当前边缘机房内机器或者服务的状态变化,如标记为下线的机器不再接受新的连接请求,但是需要维护当前已经建立的连接直至其主动断开;
- 健康检查
处于异常状态的服务在确认其不可用后应该尽快从转发表中删除,避免影响范围扩大。因此机房内需要有服务器级别的健康状态检查。目前 Ni 提供多种协议类型的健康检查方式,如 Http、Tcp 等。以下为 Http 健康检查的相关配置字段:
{
"checker": {
"http": {
"scheme": "http",
"uri": "/",
"check_port": 9080,
"codes": [
200
]
}
},
"fall_count": 2,
"interval_ms": 2000,
"rise_count": 2
}- 支持基于机器使用率/QPS等做负载均衡
Ni定期收集机房内各服务器的资源使用情况,以便于根据资源使用率做动态调整。使用收集的信息计算机房内机器负载,让负载偏低的服务分配更多的连接,偏高则反之,从而保证一个边缘机房内所有服务器的负载收敛。QPS类似。
- 基于转发表Beamer[3]的负载均衡
第一步首先需要一个稳定高效的 Hash 计算方法,输入四元组 (源 IP、源 port、目的 IP、目的 port) 后得到对应的 Hash 索引值,第二步使用索引值转换为 DIP。
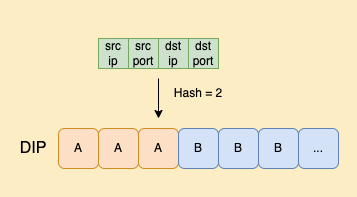
支持按照配置的 DIP 权重做负载均衡,也可以动态根据 DIP 所在机器的CPU进行实时的权重调整,也就是调整 Hash 值在整个转发表中的比例。
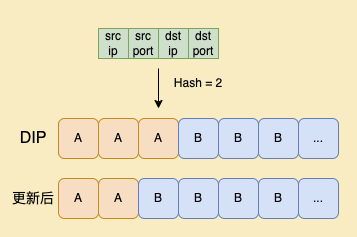
如图所示,比例变化后 Hash 值对应的DIP也会改变。原本应该发往 DIP A 的数据包,发给了 DIP B。如果这和数据包是发起建连的 (TCP SYN) ,则B服务器与该数据包的 Client 端三次握手建立新连接。但如果数据包属于之前与 A 服务器建立连接的 Client,因为 B 服务器没有对应的 TCP socket,会向 Client 发送 RST 断开连接。
要解决这个问题,需要 B 服务器收到的数据包不属于自己的 socket 后,将这类数据包二次转发给A服务器。也就是说 B 服务器需要知道二次转发的数据包应该发给谁,如果把这个信息存下来,A 服务器与 Client 的连接就可以继续保持。
为了实现这一点,我们扩展了转发表。使用四元组 Hash 之后的值,对应两个 DIP,动态更新后的称为第一跳,动态更新前的称为第二跳。
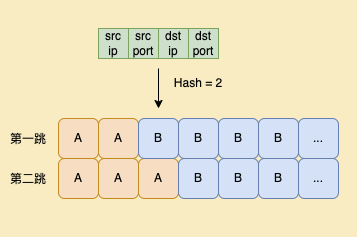
如果第一跳和第二跳的DIP是一样的,即使在判断后发现数据包不属于第一跳服务器,也不需要做第二跳的判断和转发,因此实际我们只需要保留发生变化的部分。
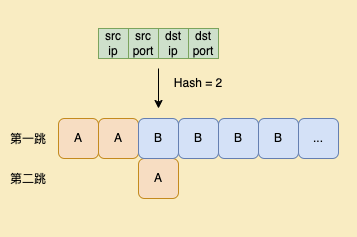
关于二次转发的逻辑,主要分为以下三个部分:
- 如果数据包是 SYN,则在第一跳服务器上新建一个连接,保证新连接的数据包都在第一跳服务器上处理。
- 非SYN的数据包,需要检查第一跳服务器上是否存在相应的 socket。如果存在,则交由第一跳服务器处理。
- 第一跳不存在对应的 socket,则将该数据包转发给第二跳服务器。如果发现第二跳为空则将该数据包丢弃。
如果出现需要转发到第二跳的情况,因为多转发了一次数据包,所以在一定程度上会造成带宽的增大。但是随着新连接的建立,老连接的断开,需要二次转发的数据包比例会很快降低。
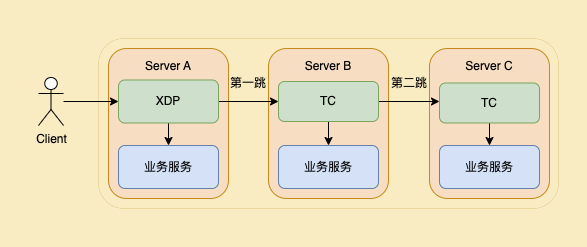
同时从理论上来说,只要某个 Client 的连接时间足够长,经过多次转发表动态调整,比如第一跳和第二跳都不是A服务器,那么这个 Client 会因为收到 RST 而断开。基于当前的调整策略,这种情况是不可避免的。对此我们在调整频率和调整策略上都做了以下优化:
- 控制最快调整时间间隔;
- 优先选择通过第一跳和第二跳对换即可实现调整目标的桶;
- 优先选择最近调整次数最少的桶;
- 避免表项大规模调整,小步迭代;
- 尽可能保证表项连续性,减少碎片等;
2.3 数据面
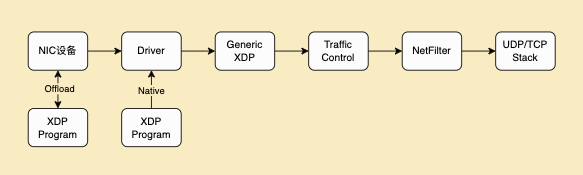
控制面维护的转发表是来指导底层做数据转发的,我们的数据转发模块使用 XDP 来实现,XDP之前在 QUIC 使用其做性能收发包优化[4]时也有介绍,它是 Linux 内核网络栈的最底层集成的数据包处理器。当网络包到达内核时,XDP 程序会在早期被执行 ,跳过了内核协议栈,提高了包处理的效率,XDP 共有3种模式:
- Offload:XDP 的 eBPF 程序直接 hook 到可编程网卡硬件设备上,而不是在主机 CPU 上执行。因为该模式将执行从 CPU 上移出,并且处于数据链路的最前端,过滤效率与性能最高。
- Native:XDP的 eBPF 程序在网络驱动程序的早期接收路径之外直接运行。
- Generic:可以在没有硬件或驱动程序支持的主机上执行上执行 XDP 的 eBPF 程序。缺点:仿真执行,需要分配额外的套接字缓冲区,导致性能下降。
Offload 模式虽性能最优但需要特定硬件的支持,Native 模式为最常用的模式,挂载在驱动路径上,需要驱动的支持,Generic 模式是内核模拟出的一种模式,不依赖于网卡驱动,不过挂载点靠后,性能在三种模式种最差。综合边缘节点机器网卡、系统等因素,我们在生产环境选用Native 模式。
控制面维护的转发表,传递到XDP模块时,其本身是一个类型为 map in map 的 eBPF map。外侧的 map key 为用户访问的服务二元组,即服务的 IP 和 Port,外侧的 map value 对应内侧的 eBPF map对象;内侧的 map key 为桶的编号,即 Hash 的索引值,value 为一个 simple C struct, 内部存储了第一跳和第二跳的IP地址。数据面在进行相应的 hash value calculation 之后,找到一对 Hop IPs,将用户的原始数据包封入由该 Hop IPs 组成的 GUE header 中。
GUE header[5] 为 Github LB 使用的一个私有头格式,详细见下图。在封包完成后,XDP 将该数据包传输给对应机器,在该机器上,由 TC 通过四元组判断该连接是否已存在;如果存在,则将该数据包解封并传输给上层;如果不存在,则根据 GUE header 转发给下一跳。
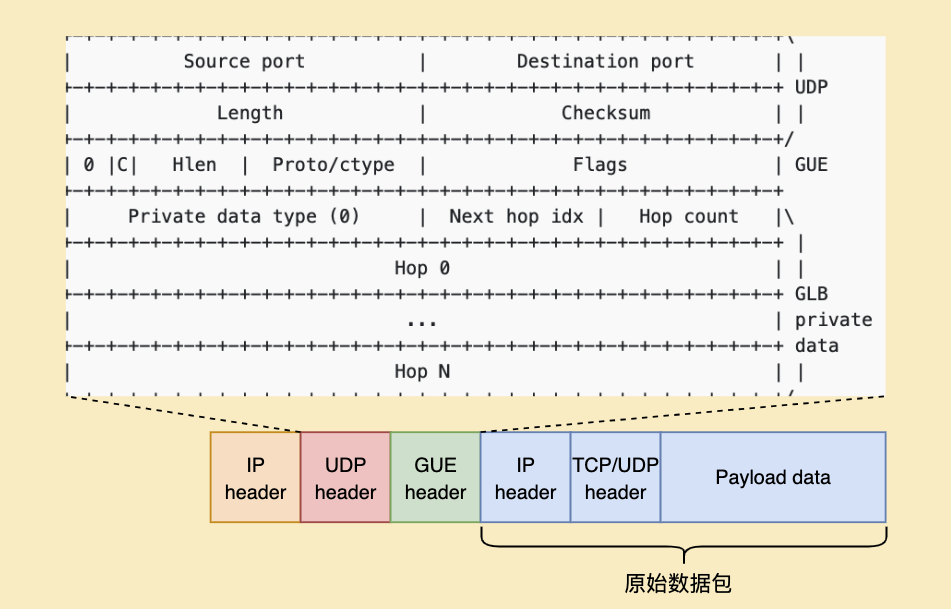
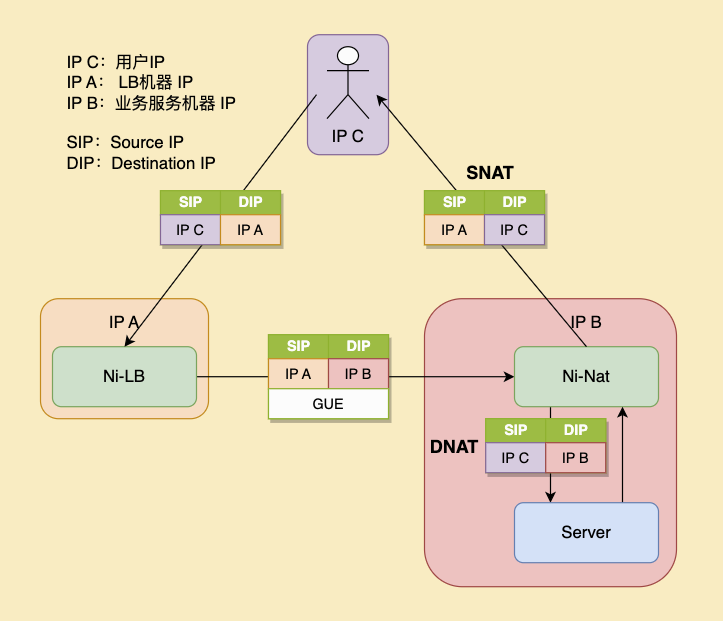
在 TC 解封完成后,如果此边缘集群支持 VIP,并且服务监听了该 VIP,其已经可以正常通过 Linux 网络协议栈的 Socket 拿到数据包,由于目前我司边缘集群尚不支持 VIP,除非通过 ip_transparent 等特殊手段,否则后端服务器上的服务无法监听作为 LB 的机器的 IP。为了使后端服务无感,我们选择使用过渡手段的 netfilter conntrack 对 ingress 数据包进行 SNAT (Source Network Address Translation) ,并对 egress 数据包进行 DNAT (Destination NAT) 。由于 conntrack 本身的性能瓶颈,会限制 Ni 作为 LB 的能力。不过在当前线上的业务场景下,并不会达到 conntrack 的性能瓶颈,边缘节点支持 VIP 也在和相关部门推进中,未来支持后,去掉 NAT 转换 Ni 的性能会进一步提高。
03 应用场景
3.1 动态加速的应用
动态加速是在传统 CDN 基础上实现的对数据网络加速进一步优化的智能管理服务,通过全方位的 CDN 质量监控,以及智能易用的节点调度等功能,提供稳定快速的网络访问服务。
动态加速的节点分布在全国的各个地区,每个节点都由多台机器组成。如果将节点内所有机器全都对外暴露,可能会有以下问题:
- 增加动态智能选路服务的运算量,一定程度上增加排查问题的复杂度;
- 如果单台机器不可用时需要通过远端探测发现并反馈到选路服务,进而计算新的路并下发,流程较长,造成路径切换变慢;
- 动态加速机房多为过保机器,存在硬件配置残次不齐的情况,性能好的机器应该处理更多的业务请求;
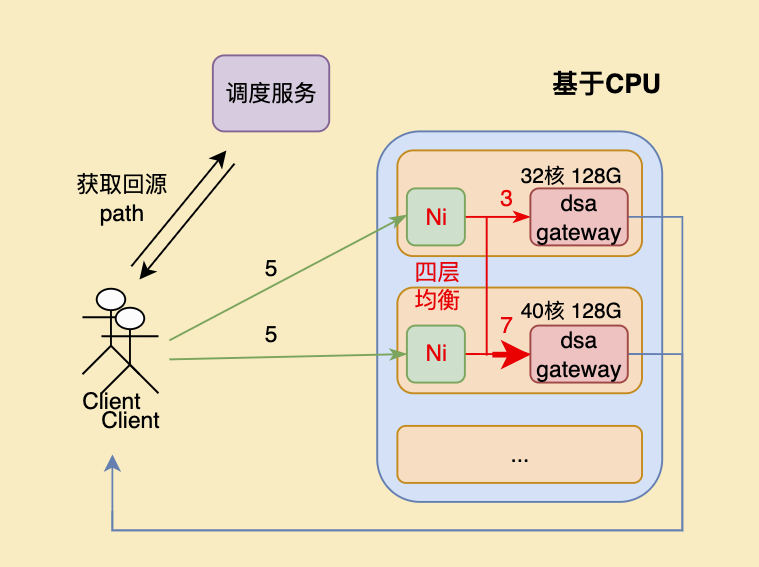
部署Ni之后
- 将机房内机器组成一个集群,收敛流量入口;
- 通过主动健康检查实时将不可用服务摘流,集群外部无感,服务恢复后自动加回;
- 检查集群内机器的 CPU 使用情况,并根据配置参数做出实时调整;
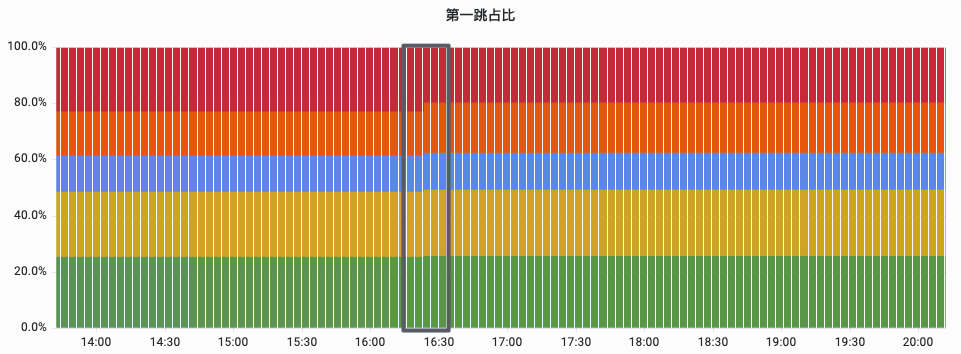
下图为红色部分代表机器 CPU 升高超出阈值后,自动将该机器接流占比减小的监控。
3.2 点直播CDN集群化场景的应用
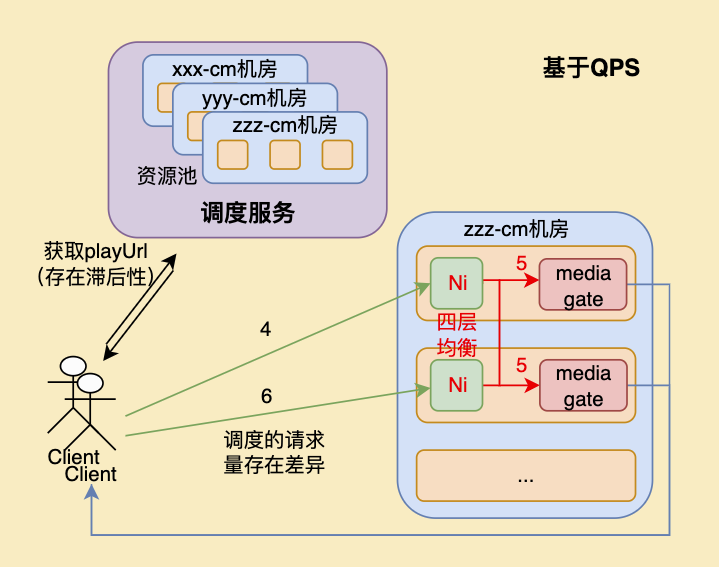
单个点直播集群内可能有几台或几十台机器,调度服务从感知资源池内机器状态变化到对用户的请求做出反应,可能会有分钟级的延迟,存在一定的滞后性。且在多机房、多机器的调度场景下,基于调度服务的负载均衡也难以完全将流量打均。将负载均衡能力下沉到机房内之后,反应时间可以降低到秒级,灵敏度更高。同时流量调度的的控制粒度也可以做到更加精细,更有利于提升边缘集群的利用率。
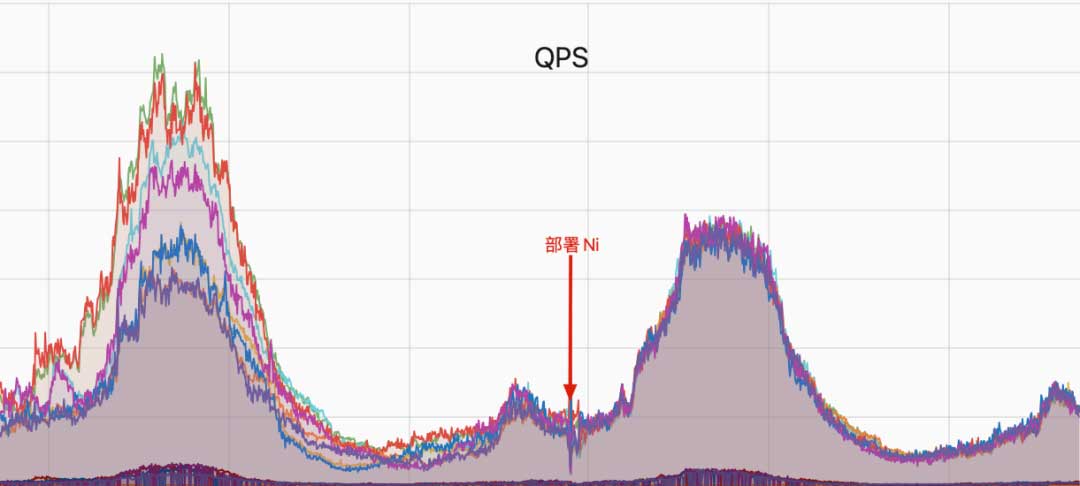
下图为某机房部分机器部署Ni前后48小时的的 QPS 对比,可以看到部署之后可以将请求平均分配到各机器,进而平衡 CPU 使用率。
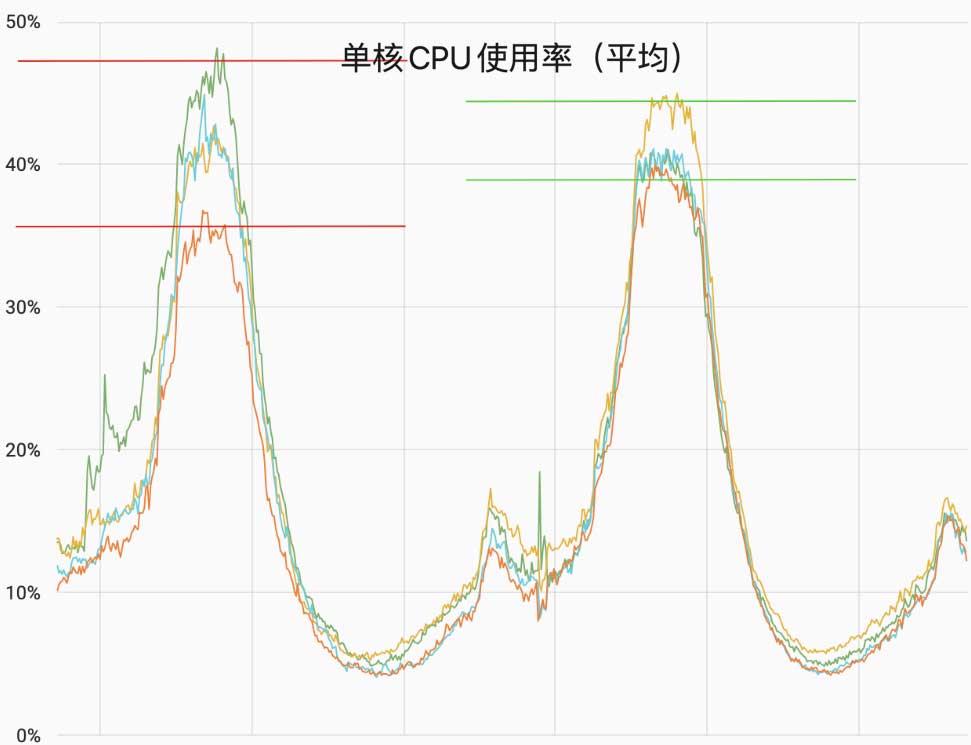
说明:因业务特性未开启根据负载动态调整功能。在均衡请求量相同的情况下,因视频资源不同等因素,CPU 会存在一定的差异。
04 未来展望
目前 Ni 已在动态加速大节点及点直播 CDN 集群化场景全量。稳定运行保障S13 直播赛事。不过仍有需要补齐和优化的地方。
- 支持黑白名单,通过 XDP 过滤边缘的攻击;
- 支持 RFC QUIC-LB 定义的规则;
- 支持基于 VIP 的 DSR 模式,消除因Conntrack造成的限制,进一步降低负载;
参考链接:
[1] https://blog.cloudflare.com/unimog-cloudflares-edge-load-balancer/
[2] https://github.com/dropbox/kglb
[3] https://www.usenix.org/system/files/conference/nsdi18/nsdi18-olteanu.pdf
[4] https://mp.weixin.qq.com/s/uPHVo-4rGZNvPXLKHPq9QQ
[5] https://github.com/github/glb-director/blob/master/docs/development/gue-header.md
作者简介
李宇星:哔哩哔哩资深开发工程师
冯学铭:哔哩哔哩高级开发工程师
刘宏强:哔哩哔哩资深开发工程师
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
