
空间音频算法现状
什么是空间音频/3D音频

区别于传统单通道和立体声音频,3D音频是一种带来三维沉浸式音频体验的新范式,其在制作、传输分发、端侧渲染端到端全链条都引入了更复杂的音频数据存储格式、编解码策略以及音效算法,继而为消费者带来了更身临其境的音频体验感以及空气感(eg:戴上耳机听音频,感觉就像没戴耳机且听到身边真实三维世界的声音一样),极有潜力成为未来交互式社交、沉浸式多媒体创作&娱乐、XR等产业的技术底座。
空间音频算法端到端链路
以audio vivid为例,空间音频的生产流程从技术环节来说,可以分为三个环节,生产制作,传输,以及渲染,如下图。
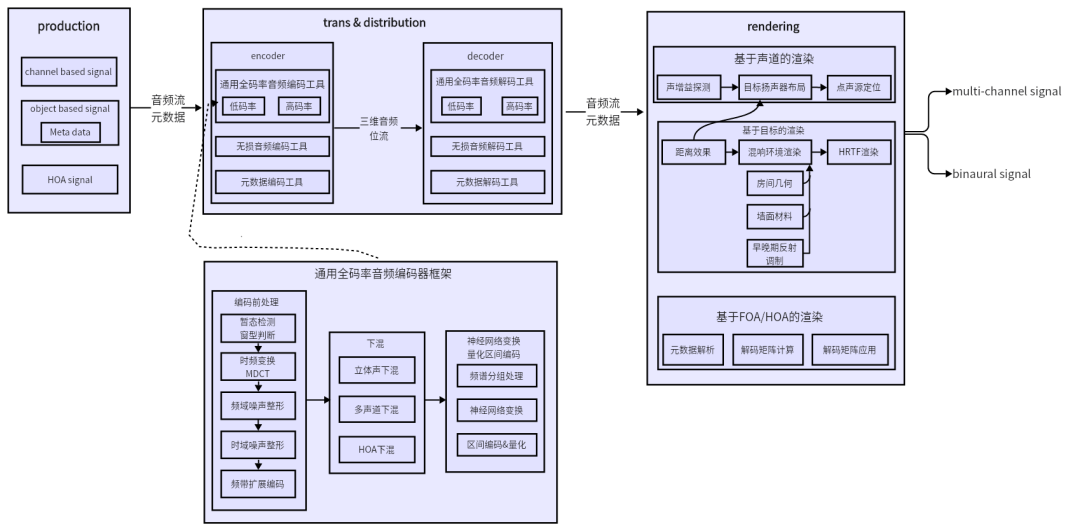
音频渲染的主要任务是将音频解码后的输出渲染至具体的音频回放设备中去,因而空间音频渲染主要是解决呈现效果的重任。
当前主流的受支持的空间音频信号的空间音频编解码技术可以分为三种类型:
- 基于场景的音频表示信号:是基于球面谐波变换的高阶精度系数来表示三维空间所有点的压力值, 在实际播放时,需要对 HOA 系数进行虚拟扬声器映射(称之为 HOA解码)得到声道信号,然后进行播放。
- 基于声道的音频表示信号:在录音时预先设定好声道与扬声器的位置映射,录音获得相应的声道录音信号,播放时,按照扬声器位置映射将相应的声道输入至该扬声器进行播放。这种方式为基于声道的信号表示方式。
- 基于对象的音频表示信号:对象对应于不同的声音个体,在具体表示是,声音对象可以携带声音的音频特性,空间位置,语言类型甚至元数据交互的功能。在播放时,对所有的对象进行渲染播放。和前两种相比,可以更灵活、自然的表达音频信号,更适用于虚实结合交互更多的XR场景。
除此之外还有解码后的元数据。音频渲染预处理模块的主要任务是识别解码输出后的信号属于上述哪一种信号,进而根据信号种类将解码后的格式数据统一成为系统约束的格式,为接下来的空间信息处理模块调用正确的空间信息解析器做准备。
空间音频特性对音频质量评测系统的挑战
3D音频在传统一维空间基础上,带来了更复杂的编码器、卷入了更大的上下行数据带宽、引入了更多空间信息,因此也给音频评价算法与系统带来了新的挑战:
- 需要对多维空间音频信息的准确度、还原度做评测;
- 需要考虑新编解码器带来的性能开销与效果的平衡是否合理。
其中,为什么对多维空间声学信息做评测会带来更大挑战?这就需要先解释一下我们传统的单通道音频评价方案&算法的特点,以及在空间音频范式下引入的评测瓶颈:
- 典型的音频评价信号处理类算法,例如对音质的评价算法polqa、pesq等仅支持单通道的输入,暂不支持双通道or多通道或者ambisonic格式的源信号;
- 对于当前使用神经网络算法实现的音频评价模型,主流的训练集以及推理场景都限于单通道音频;即使网络结构支持多通道数据,例如可以通过将多个通道的数据concat成同一个输入信号做训练,但是数据标签中的关键维度如音质等缺少专业的标注数据集,因此多通道的特征-标签对的数据稀缺也为空间音频的评价蒙上了一层阴影。
进一步的,或许有读者会产生疑惑,如果以双耳渲染的空间音频范式为例,能否直接对两个通道分别做评价,然后对结果做一定程度的平均?
答案是否定的,此时需要打开人耳的听觉外周结构链路,来进一步解释空间音频的效果作用生理学逻辑。
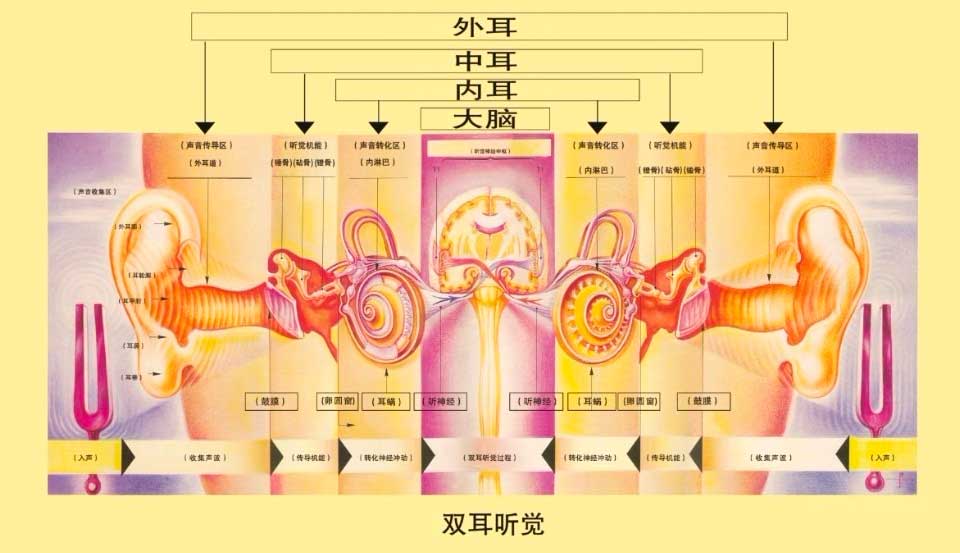
如上图所示,当音源(音叉)产生的震动声波信号经由空气传播通过耳廓、外耳道到耳膜处,进一步由听小骨传到振动信号至耳蜗;后者由基底膜作为底座,外毛细胞和内毛细胞作为转化关键介质,将声音震动信号转化为神经细胞信号,进一步向后续的听神经以及端侧大脑传导外界声波刺激。此时左侧or右侧的大脑听觉区在同时接收两侧的听神经信号,也就是说,最终产生的左侧大脑皮层刺激中,会同时包含左右侧两路声学刺激信号,因此将两路单通道信号分别处理后做加权平均的思路和人的主观感知过程是完全不同的。而对于右侧大脑皮层,刺激过程也是类似的。
基于上面的讨论,抖音多媒体评测实验室也在人耳的听觉链路编码器领域做了一些尝试和探索,希望通过拟合更趋近于人耳主观感知的编码器,来替换传统的声学特征(eg:MFCC/Mel/时频谱),从而更能表征人的听觉外周实际听感。
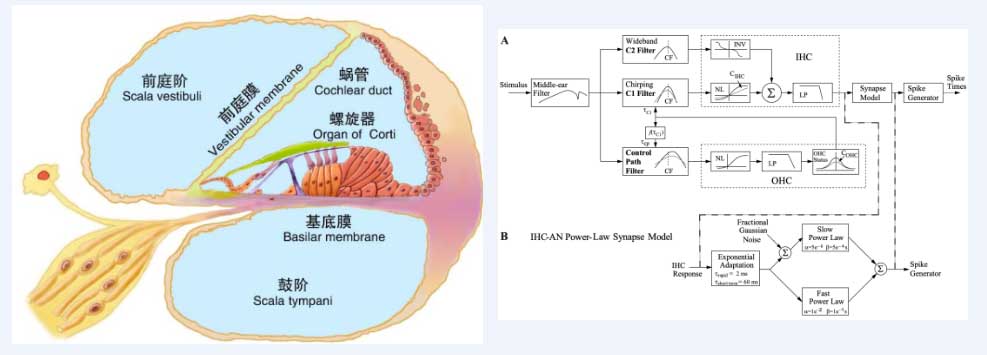
如下图所示,左侧是听觉外周关键部位-耳蜗的生理学结构,右侧是通过滤波器组合的链路来对内毛细胞、外毛细胞、基底膜以及听神经细胞的信号传递过程模拟[1]。
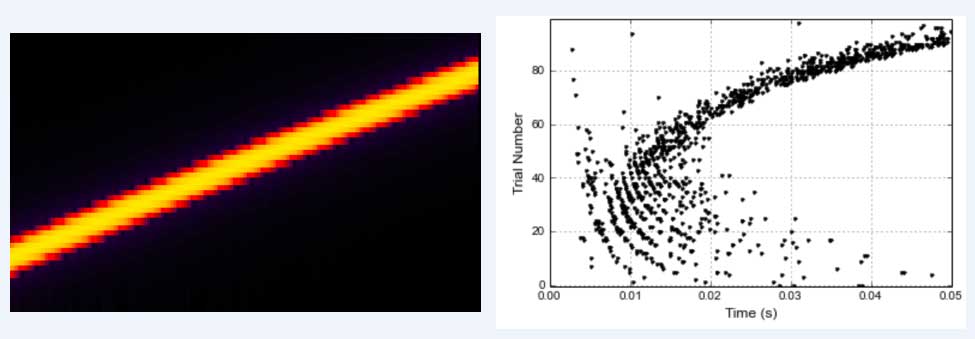
如下图所示,左侧是扫频信号的时频谱,右侧是使用听觉外周仿真链路输出的听觉外周电信号谱,可以看到人实际听到的信号除了左下到右上的直线特征以外,还有很多反向的衍射条纹信息。该条纹中的空间音频信息、以及双耳信号融合信息有待后续进一步分析。
空间音频评价维度
当前主流的空间音频评价维度如下:
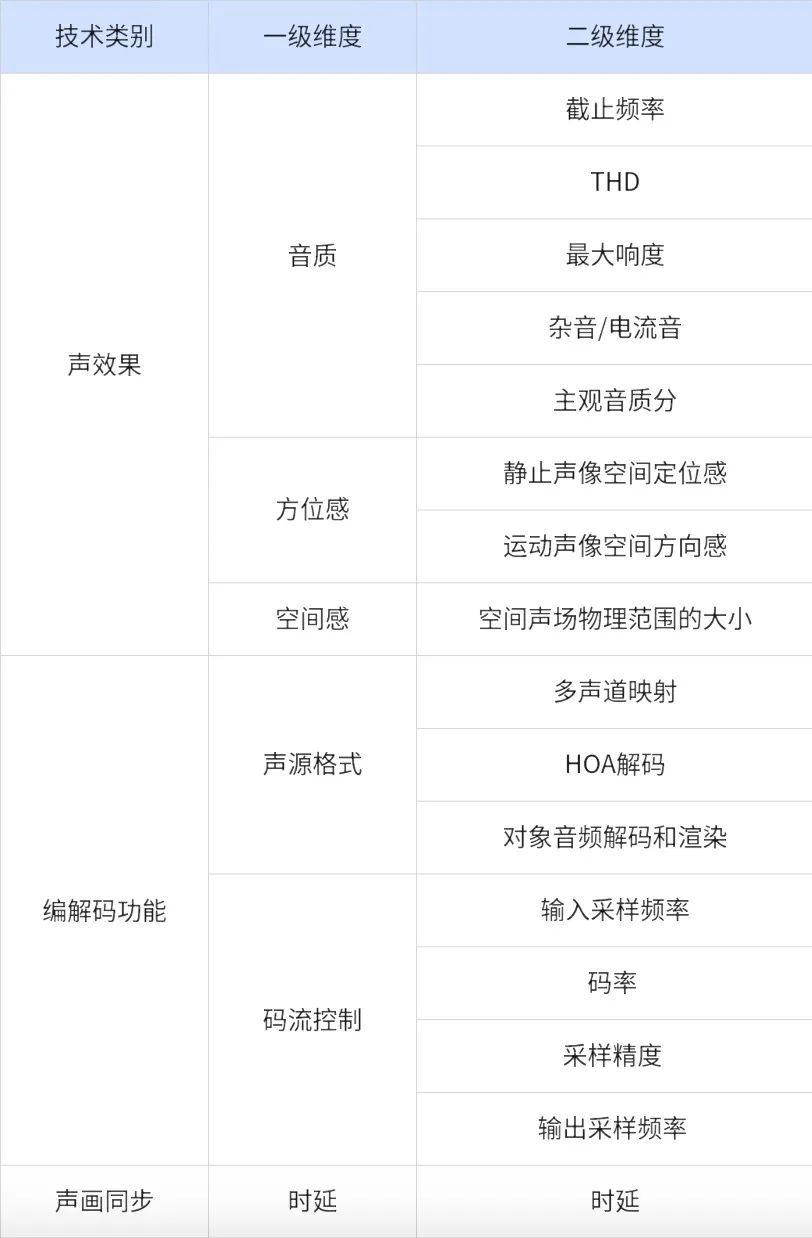
空间音频评价算法
当前抖音多媒体评测实验室在空间音频评价算法的评价领域,探索如下:
无参考音质客观评价算法
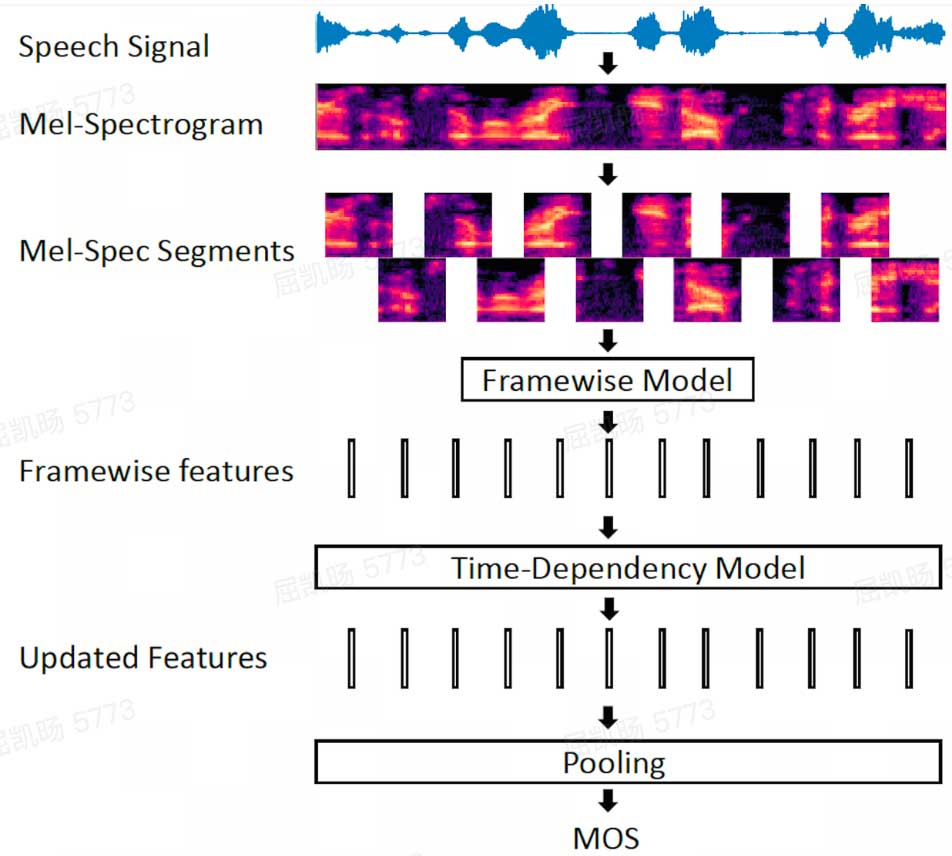
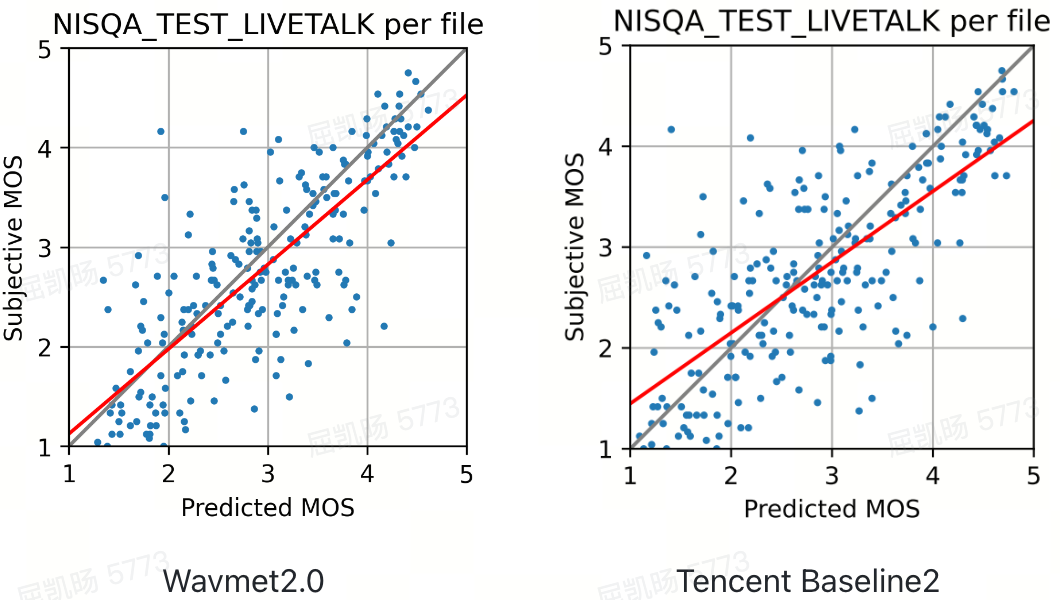
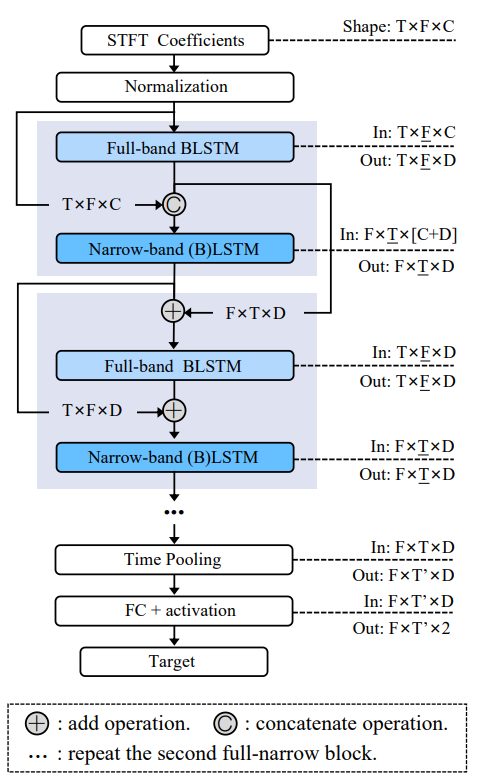
使用评测实验室自研无参评测算法wavmet进行客观打分,对应打分准确度高于业界无源算法标杆,具体验证结果与模型结构如下:

无参考方位感客观评价算法
基于上文的讨论,传统的空间方位信息(eg:ITD、ILD)无法反应人耳的实际听觉链路输入,因此考虑通过深度神经网络获取双通道音频特征(eg:听觉编码器谱、STFT、MFCC)与DOA之间的映射关系
无参考空间感客观评价算法
使用深度学习网络做音频序列与对应空间大小标签(eg:RT60)的映射
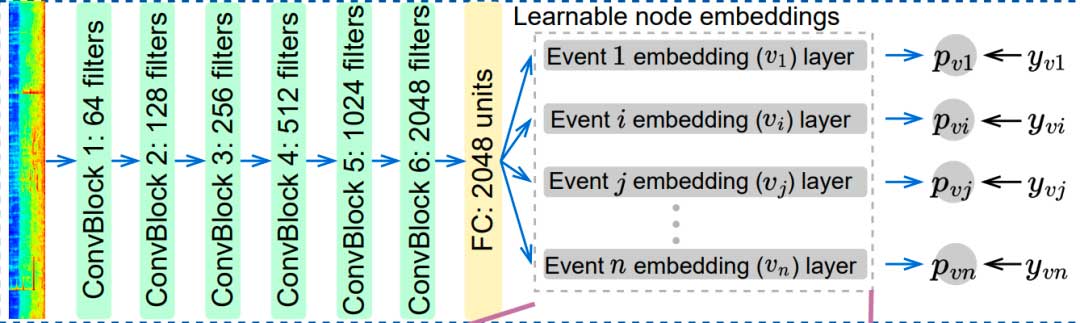
有参考编解码效果质量评价算法
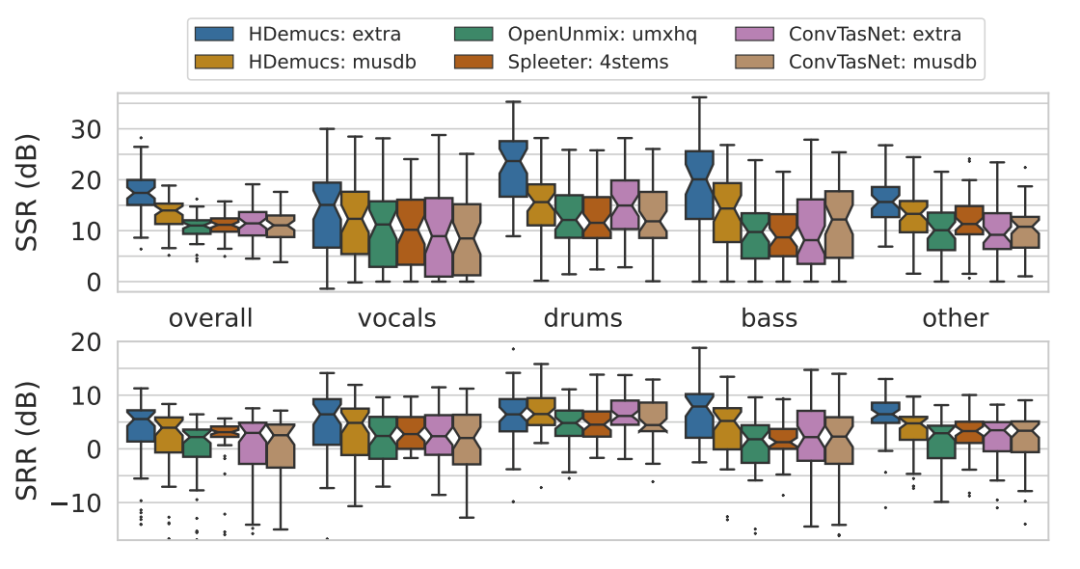
使用 Signal to Spatial Distortion Ratio (SSR)和 Signal to Residual Distortion Ratio (SRR)两个指标来客观表征空间算法渲染之后的信号劣化情况,基于传统信号处理的方式来做多通道的信号相关性分析。
SSR和SRR可以用于评估音频编码和分离算法的质量。对于音频编码算法,可以通过计算不同比特率下的SSR和SRR来评估其对音频空间信息和非空间信息的保留情况。例如,对于AAC和Opus编码器,可以通过计算它们在不同比特率下的SSR和SRR来评估它们的编码质量。
参考文献
[1]Zilany, Muhammad SA, and Laurel H. Carney. “Power-law dynamics in an auditory-nerve model can account for neural adaptation to sound-level statistics.” Journal of Neuroscience 30.31 (2010): 10380-10390.
(以上部分资料来自网络,侵删)
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
