
本文提出了一种提出了一种像素感知的稳定扩散( PASD )网络,以实现鲁棒的真实图像超分和个性化的风格化。引入像素感知的交叉注意力模块,使扩散模型能够在像素级别感知图像局部结构,而退化去除模块用于提取退化不敏感特征,与图像High-level信息一起指导扩散过程。通过简单地将基扩散模型替换为个性化模型,本文的方法可以生成多样化的风格化图像,而不需要收集成对的训练数据。
题目:Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalized Stylization
论文地址:https://arxiv.org/pdf/2308.14469.pdf
项目地址:https://github.com/yangxy/PASD
作者:Tao Yang, Peiran Ren等
内容整理:王寒
简介
图片在采集过程中经常面临着多重混合退化,例如低分辨率、模糊和噪声等。过去的深度学习模型因为模型设计时对忠实度的要求常常会给出过度平滑的结果。基于GAN的算法广泛应用于超分任务中,但是基于GAN的方法常常会产生伪影,无法生成丰富逼真的图像细节。DDPM在图像生成、图像转译领域取得了出色的成果,是GAN的有力替代品。基于DDPM/DDIM的文生图、文生视频先验被广泛应用于下游任务中。预训练的文生图稳定扩散模型能生成高分辨率高质量的自然图片,ControlNet使多类型的条件控制被应用到稳定扩散先验中。但是ControlNet不适用于像素感知的任务,直接使用会产生不一致的结果。也有一些基于Controlnet的超分辨率算法,但它们需要跳跃连接来提供像素级的信息,需要额外的训练。
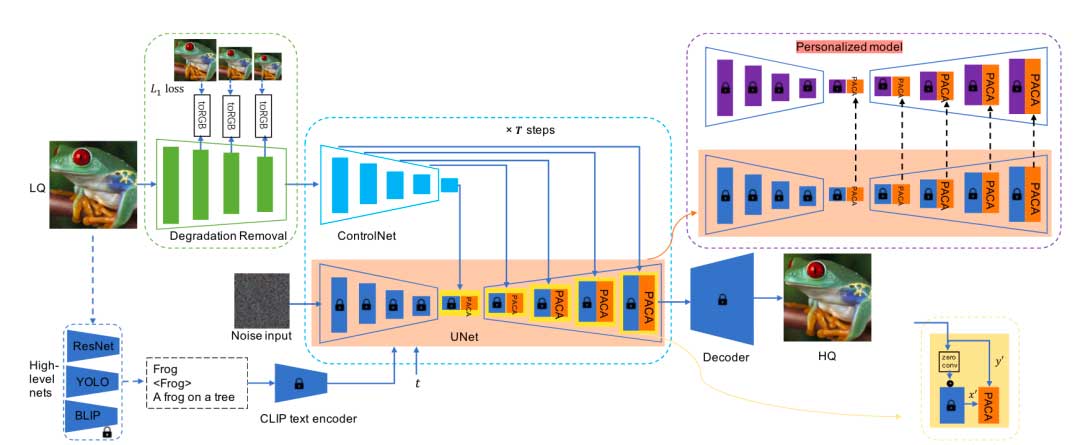
本文提出的方法利用稳定扩散的先验知识,致力于在图像超分辨率问题上重建真实感结构和纹理。本文在扩散过程中引入像素感知的条件控制,从而获得鲁棒的、具有感知真实感的Real-ISR结果。为此,提出了一个像素感知的交叉注意力( PACA )模块来感知像素级别的信息,而不使用任何跳跃连接。使用退化去除模块来减少未知图像退化的影响,减轻扩散模块处理真实世界低质量图像的负担。还证明了从输入图像中提取的高层分类/检测/描述信息可以进一步提升Real-ISR性能。最后,本文提出的像素感知稳定扩散( pixel-aware stable diffusion,PASD )网络可以通过简单地将基础模型转移到进行个性化风格化任务。
退化去除模块
真实世界的低质量(LQ)图像通常会遭受复杂和未知的退化。因此,本文使用退化去除模块来减少退化的影响,并从低质图像中提取”干净”的特征来控制扩散过程。如图左上角的绿色部分所示,采用金字塔网络来提取输入LQ图像的1 / 2,1 / 4和1 / 8比例分辨率的多尺度特征图。期望这些特征能够在相应尺度上尽可能地逼近高质(HQ)图像,以便后续的扩散模块能够专注于恢复真实的图像细节,减轻了区分图像退化的负担。引入了一个中间监督,通过一个卷积层toRGB将每个单尺度的特征图转换到高分辨率RGB图像空间。在每个分辨率尺度上施加一个L1损失,以迫使该尺度上的重建接近HQ图像的金字塔分解:
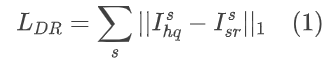
像素感知的交叉注意力(PACA)模块
利用预训练的 T2I 扩散先验进行图像复原任务的主要挑战在于如何使扩散过程能够感知像素级别的图像细节和纹理。ControlNet 网络可以很好地支持任务特定的条件(例如,边缘,分割掩码),但不能用于像素级控制。在U – Net中给定一个特征图 x ϵ Rh x w x c,其中{ h,w,c }为特征高度、宽度和通道数,在网络中给定一个skip特征图y ϵ Rh x w x c,ControlNet提出了一种称为”零卷积”的独特类型的卷积层Z来连接它们:

高阶语义信息
本文的方法是基于预训练的SD模型,其中文本作为输入,而Real – ISR通常以LQ图像作为输入。虽然一些基于SD的Real – ISR方法使用了空文本提示,但已经证明了内容相关的字幕可以改善合成结果。我们使用预训练的Res Net、YOLO和BLIP网络从LQ输入中提取图像分类、目标检测和图像描述信息,并使用CLIP 编码器将文本信息转换为图像级特征,提供额外的语义信号来控制扩散过程。同时,classifier- free技术也被引入:
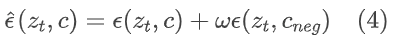
其中c是积极条件,cneg是消极条件。
个性化风格化
可以在的推理过程中用个性化模型替换PASD网络的基础模型,使其能够产生风格化结果。与之前的方法通过使用对抗训练学习像素到像素的映射函数来实现风格化能力不同,本文的PASD方法解耦了风格化生成和像素到像素的映射,为图像风格化打开了一扇新的大门。通过使用一批风格图像微调个性化SD模型或从在线社区下载不同的个性化模型,PASD方法可以很容易地生成各种风格化的结果。
实验
训练细节
给定一幅HQ图像,我们首先得到它的隐表示zo。扩散算法对隐层图像逐步添加噪声,并产生一个含噪的隐空间编码zt,其中t为扩散步长,随机采样。给定一些条件,包括扩散步长t,LQ输入Ilq和文本提示c,我们学习一个PASD网络εθ来预测添加到含噪隐变量zt中的噪声。扩散模型的优化目标是:
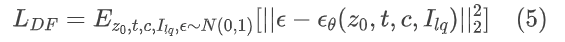
在Real – ISR模型的训练过程中,联合更新退化去除模块。总损失为:
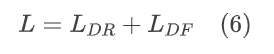
将稳定扩散模型的所有参数冻结,只对新增的模块进行训练,包括降解去除模块、controlnet网络和PACA。用于高层信息提取的Res Net、YOLO和BLIP、CLIP网络也是固定的。在训练过程中,随机将50 %的文本提示替换为空文本提示。这促使我们的PASD模型从输入的LQ图像中感知语义内容,作为文本提示的替代。
本实验采用Adam优化器训练批大小为4的PASD。学习率固定为5 x 10-5。使用8个NVIDIA Tesla 32G-V100 GPU对模型进行500K次迭代更新。
在DIV2K ,Flickr2K ,OST 和FFHQ 的前10000张人脸图像上训练PASD。我们使用Real-ESRGAN的退化来合成LQ-HQ训练对。
在合成数据集和真实数据集上评估了我们的方法。合成数据集是根据Real – ESRGAN 的退化过程从DIV2K验证集中生成的。对于真实的测试数据集,我们使用了RealSR和DRealSR两个基准测试集。
对于个性化风格化任务,我们对来自FFHQ的前100张人脸图像和来自Flicker2K的前100张图像进行了比较。
定量实验
定量实验选择FID、CLIP—FID和MUSIQ指标进行评价。实验结果如下表所示。

定性实验
下图展示了一些通过不同的方法对测试图像进行真实感图像超分辨率重建的结果。

下图展示了通过不同的方法对现实世界的图像进行风格化的结果。

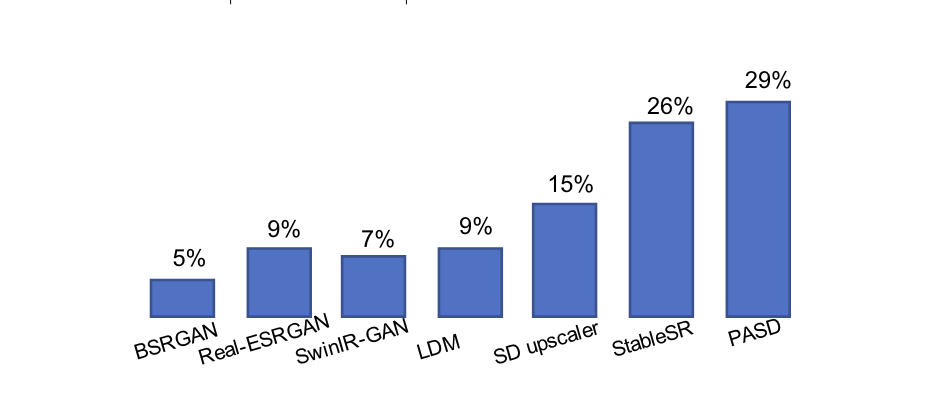
用户实验
下图展示了不同超分辨率算法的用户实验结果。本文提出的方法收到最多用户的喜爱。
消融实验
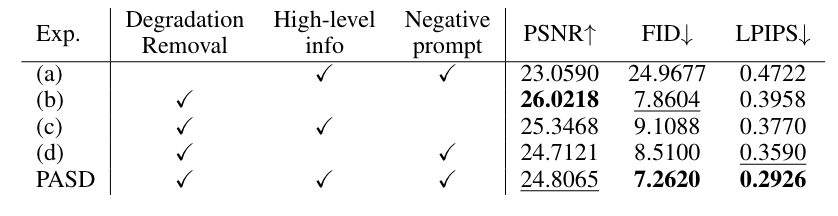
针对PACA模块、退化去除模块、高阶语义信息模块分别进行了消融实验,定量实验结果如上表所示,生成图片结果如下图所示。

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
