
前几个月里,有幸负责了一块高并发的实时计算功能,期间接触到了flink和kafka。既然工作中接触到了kafka,不如就深入了解下其内部的原理。那么kafka的内部到底有哪些优秀的设计思路,促使其具备高性能特性,今天我们来一起梳理下其底层的具体实现:
消息批处理
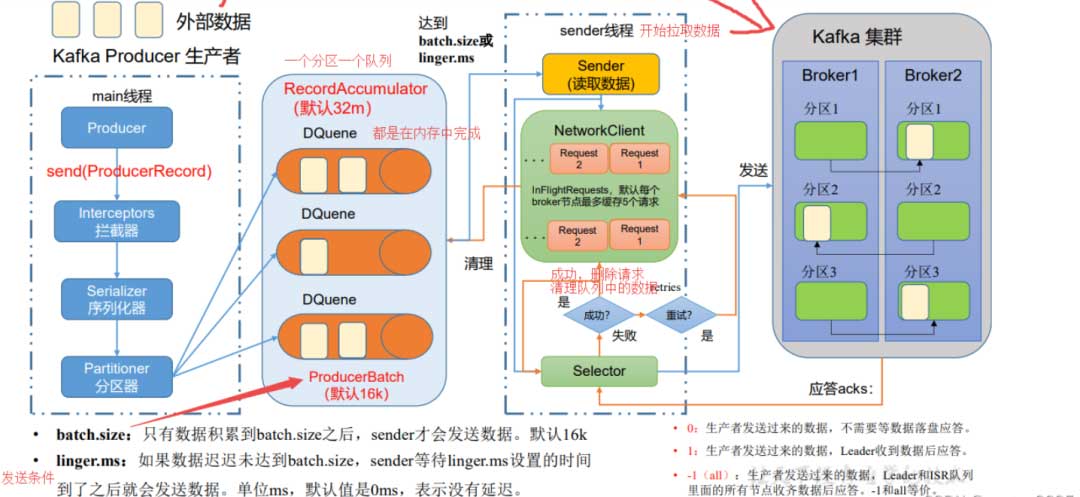
kafka的底层对于消息的发送采用了一种批量推送的功能。虽然我们在使用kafka的时候,api提供了一个叫做send的函数,但是该函数其实底层并不是每次调用就会立马发送消息给到broker那边。而是会有一个批量发送的设计思路。
发送端其实在底层会有一个专门的队列,当我们从api调用了send函数之后,该方法会将传入的message对象先往本地内存的一条队列中写入,然后会有一个专门的线程从队列中提取出元素,批量地往broker端发送。这样成批地发送数据,可以大大减少单条消息挨个发送所带来的网络额外开销。
Kafka 提供了以下几个参数来控制发送端的批处理策略:
- batch.size:指定每个批次可以收集的消息数量的最大值。默认是 16KB。
- buffer.memory:指定每个 Producer 可以使用的缓冲区内存的总量。默认是 32MB。
- linger.ms:指定每个批次可以等待的时间的最大值。默认是 0ms。
- compression.type:指定是否对每个批次进行压缩,以及使用哪种压缩算法。默认是 none。
而在broker端,面对批量发送过来的消息数据,broker不会将其拆解开来,而是直接写入。这里的批量写入是写入了文件内存映射的地址,kafka底层运用了mmap技术,提升了写入磁盘的速率,这样子写磁盘的速度接近于写内存速度一样快,提升了写入的速率。
对于消费端来说,消费者每次会拉取一批的消息到本地进行消费,这种批量消费可以提升消费者的速率。
Kafka 提供了以下几个参数来控制消费端的批处理策略:
- fetch.min.bytes:指定每次拉取请求至少要获取多少字节的数据。默认是 1B。
- fetch.max.bytes:指定每次拉取请求最多能获取多少字节的数据。默认是 50MB。
- fetch.max.wait.ms:指定每次拉取请求最多能等待多长时间。默认是 500ms。
- max.partition.fetch.bytes:指定每个分区每次拉取请求最多能获取多少字节的数据。默认是 1MB。
整体细节流程图如下所示:

消息压缩
如果我们考虑将发送的消息进行压缩,那么是不是可能会降低网络传输的消息成本呢?哈哈哈,kafka的设计者也想到了这一点,所以对Kafka内部的消息传输引入了压缩算法一说。
生产者可配置 props.put(“compression.type”, “gzip”); 即可开启 gzip 压缩。另外,除了Gzip以外,kafka支持配置snappy,lz4压缩算法。
一般来说我们的消息都会在发送端进行压缩,那么broker上存储的数据内容就是压缩后的数据,只有当消费者拉取这部分数据进行消费的时候,数据才会被解压。
另外,虽然网上有些文章提到过broker端可以做消息的压缩和解压操作,但是这类做法其实并不是很恰当,因为它是一个高计算性的行为,必定在高并发情况下会大量占用cpu的时间片。所以不是很推荐在broker做这块操作。
下面这张表是 Facebook Zstandard 官网提供的一份压缩算法 benchmark 比较结果:
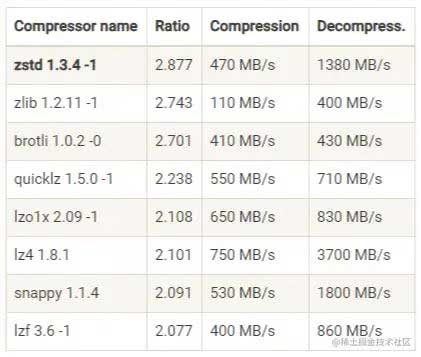
- 吞吐量方面:LZ4 > Snappy > zstd 和 GZIP
- 压缩比方面:zstd > LZ4 > GZIP > Snappy
- 网络带宽:使用 Snappy 算法占用的网络带宽最多,zstd 最少
- CPU使用率:压缩时 Snappy 算法使用的 CPU 较多一些,而在解压缩时 GZIP 算法则可能使用更多的 CPU。
固化内存池
Producer 发送消息是批 量的, 因此消息都 会先写入 Producer 的 内存 中 进行缓冲, 直到多条消息 组成了一 个 Batch,才会 通过网络 把 Batch 发给 Broker。
当这个 Batch 发送完毕后,显然这部分数据还会在 Producer 端的 JVM 内存中,由于不存在引用了,它是可以被 JVM 回收掉的。但是大家都知道,JVM GC 时一定会存在 Stop The World 的过程,即使采用最先进的垃圾回收器,也势必会导致工作线程的短暂停顿,这对于 Kafka 这种高并发场景肯定会带来性能上的影响。
有了这个背景,便引出了 Kafka 非常优秀的内存池机制,它和连接池、线程池的本质一样,都是为了提高复用,减少频繁的创建和释放。
具体是如何实现的呢?其实很简单:Producer 一上来就会占用一个固定大小的内存块,比如 64MB,然后将 64 MB 划分成 M 个小内存块(比如一个小内存块大小是 16KB)。
当需要创建一个新的 Batch 时,直接从内存池中取出一个 16 KB 的内存块即可,然后往里面不断写入消息,但最大写入量就是 16 KB,接着将 Batch 发送给 Broker ,此时该内存块就可以还回到缓冲池中继续复用了,根本不涉及垃圾回收。
合适的GC算法配置
GC 算法是 JVM 用来回收无用对象占用的堆内存空间的方法,它会影响 Kafka 的停顿时间和吞吐量。GC 算法有多种选择,例如串行 GC、并行 GC、CMS GC、G1 GC 等。
不同的 GC 算法有不同的优缺点和适用场景,例如串行 GC 适合小型应用和低延迟场景;并行 GC 适合大型应用和高吞吐量场景;CMS GC 适合大型应用和低停顿时间场景;G1 GC 适合大型应用和平衡停顿时间和吞吐量场景等。
通常来说,Kafka 建议使用 G1 GC 作为默认的 GC 算法,因为它可以在保证较高吞吐量的同时,控制停顿时间在 200ms 以内。同时,Kafka 还建议根据具体情况调整一些 GC 参数,例如:
- -XX:MaxGCPauseMillis:指定最大停顿时间目标,默认是 200ms。
- -XX:InitiatingHeapOccupancyPercent:指定触发并发标记周期的堆占用百分比,默认是 45%。
- -XX:G1ReservePercent:指定为拷贝存活对象预留的空间百分比,默认是 10%。
- -XX:G1HeapRegionSize:指定每个堆区域的大小,默认是 2MB。
Partition和LogSegment模块
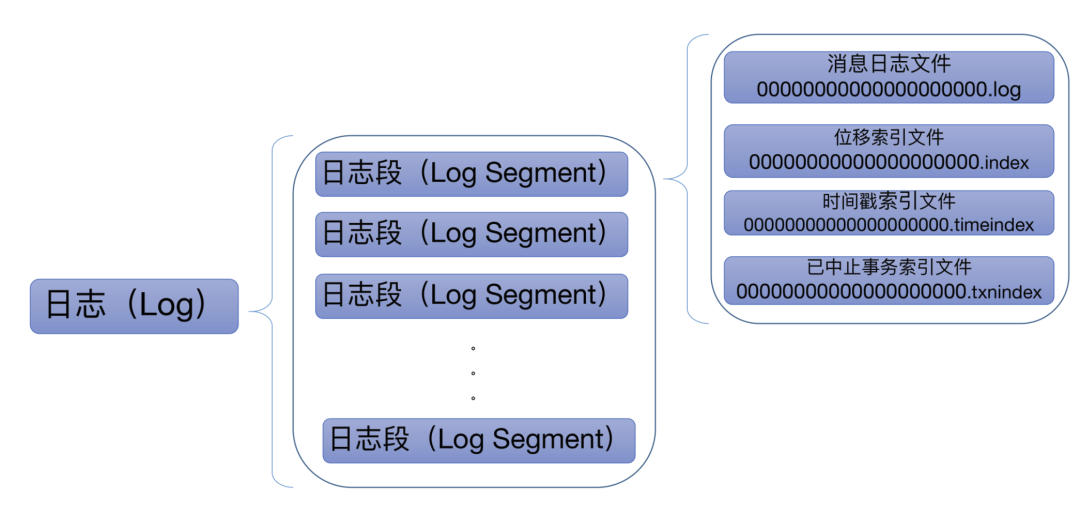
每个topic的消息都会被写入到Partition当中,有了Partition会被分配到不同的机器上,保证我们的消息存储压力可以被分散到不同的机器上。每个Partition底层其实就是很多个LogSegment日志文件的组成。
Kafka 日志对象由多个日志段对象组成,而每个日志段对象会在磁盘上创建一组文件,包括消息日志文件(.log)、位移索引文件(.index)、时间戳索引文件(.timeindex)以及已中止(Aborted)事务的索引文件(.txnindex)。当然,如果你没有使用 Kafka 事务,已中止事务的索引文件是不会被创建出来的。
作者: Idea的技术分享
原文:https://mp.weixin.qq.com/s/DAzGWZwOOoc0OyjMp77TUg
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。