
大量分布式应用部署在跨数据中心网络(Cross-DC)中。在Cross-DC中,分布在不同地理位置的数据中心DC(DataCenter)通过广域网 WAN (Wide Area Network)连接在一起。这些Cross-DC应用会产生数据中心内和数据中心间的流量,每种流量都有不同的需求和特点。我们发现,现有的组合拥塞控制方案忽略了这两种流量的交互作用,混合拥塞控制方案无法准确估计跨数据中心网络的拥塞程度。在本文中,我们提出了基于延迟的拥塞控制方案IDCC(INT and Delay based Congestion Control),利用延迟来分别处理 DC 内部和广域网中的拥塞。我们分别利用带内网络遥测 INT(In-band network telemetry)和往返时间RTT (Round Trip Time) 来测量 DC内部和广域网中的排队延迟,并通过比例积分微分 PID (Proportional Integral Differentiation)来保证算法的稳定性。我们在仿真平台上实现了 IDCC,并进行了广泛的大规模仿真评估。
研究背景
许多云服务 (如网络搜索、社交网络、推荐系统)已经部署到地理位置分散的数据中心,为客户提供服务。跨数据中心网络由数据中心内和数据中心间网络组成,数据中心内与数据中心间的流量比例约为 6:1[2]。目前,数据中心内部和数据中心之间的流量共享数据中心网络,它们对网络的需求也不断变化。数据中心间流量对延迟敏感性较低,需要高带宽。相比之下,数据中心内的大多数流量都很短,需要较低的延迟。DC间流量和DC内流量会相互影响,从而降低应用性能。目前,有两种主要的拥塞控制算法来优化Cross-DC的传输性能。
类型1:组合拥塞控制。这类方法采用数据中心拥塞控制方法(如 DCTCP[3])和广域网拥塞控制方法(例如,BBR[5]、Cubic[6])的组合来分别优化DC内和DC间的流量。这些方法虽然简单,但忽略了流量交互,可能会导致应用程序性能不佳。实际上,广域网拥塞控制方法过于激进,往返时间(RTT)较长,这意味着DC间流量往往会在数据中心交换机内产生深队列,甚至缓冲区溢出。因此,数据中心内的流量可能会出现严重的延迟或数据包丢失,导致数据中心内的应用性能低下。
类型 2:混合拥塞控制。这类方法(如 Gemini [2]、Annulus [1]、GTCP [7])使用混合信号来估计DC内和DC间的网络状况,并根据这些信息实施拥塞控制。例如,Gemini[2] 利用 ECN(Explicit Congestion Notification) 信号估计DC内拥塞情况,利用延迟估计DC间拥塞情况。虽然混合拥塞控制方案可以缓解流量交互造成的性能下降,但要精确平衡DC内和DC间的拥塞信号是一项挑战。因此,DC内或DC间应用都可能出现性能缺陷。
研究动机
为了验证现存方法的不足,我们在 ns-3中,进行了一个简单的实验,以证明组合拥塞控制方法和混合拥塞控制方法在满足数据中心内和数据中心间应用需求方面的缺点。拓扑结构如图 1所示,其中两个小型数据中心站点由一条容量为 500 Mbps、传播延迟为 5ms 的广域网链路连接。数据中心的每个链路容量为 1Gbps,传播延迟为 2us。DC1 中的 S2 运行网络搜索流量来模拟数据中心内的应用,S1 运行长流量来模拟数据中心间的应用。我们选择 DCBR (DCTCP 用于DC内流量,BBR 用于DC间流量)和 L2BR (L2DCT用于DC内流量,BBR 用于DC间流量)作为组合方案的基本方案。我们将 GEMINI[2]和 Annulus[1]作为混合方案的基准。
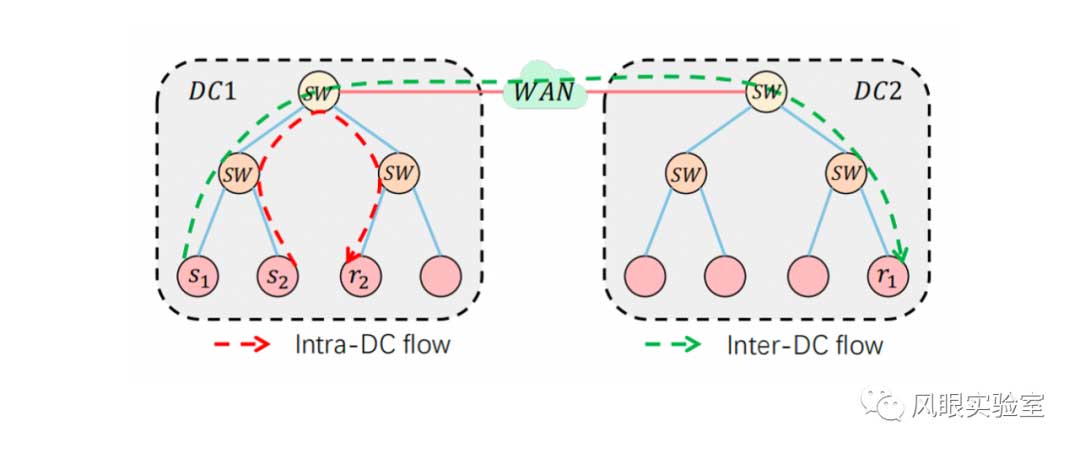
图2展示的结果表明,尽管这两种方案都能优化应用性能,但它们仍然存在以下两个缺点:
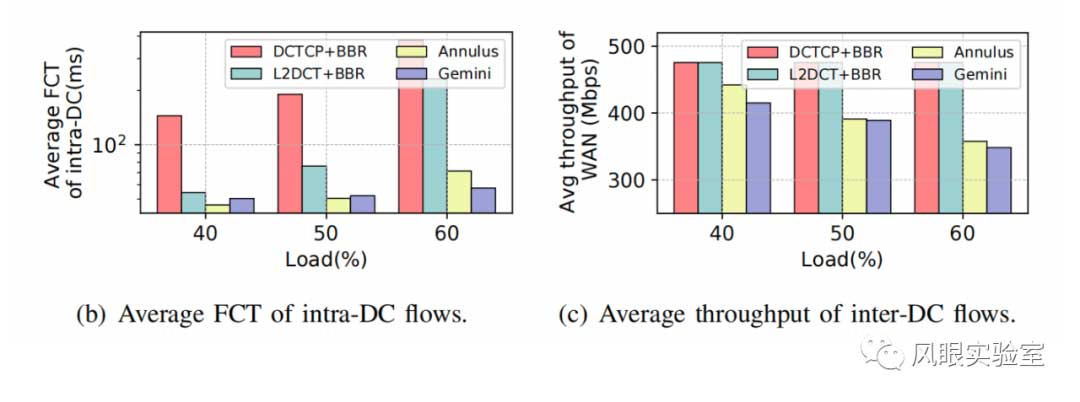
首先,组合方案可能会导致数据中心内的短流量出现较大的平均FCT。在现代数据中心网络中,90% 以上的流量都很短(小于 100 KB),而DC内交换机缓冲区总是很浅。组合方案主张独立优化流量,这可能会导致数据中心间的流量占用交换机缓冲区,因为它们对拥塞的响应慢,容易产生深排队,影响短流性能。图 2(b)所示的结果也证明了这一点,因为 DCBR 和L2BR 下DC内短流量的平均 FCT 可能是混合方案的 3 倍以上。
其次,混合方案无法准确估计网络拥塞程度。混合方案主张使用不同的DC内信号和DC间信号,然后根据混合拥塞信号进行拥塞控制。虽然混合方案考虑到了网络的异质性,但很难精确平衡两种信号,从而限制了它们的实用性。此外,大多数方案都忽略了DC内部的短流量。图2(c)中的结果同样与此相符,由于缺乏精确的拥塞平衡,混合方法表现出较低的广域网带宽利用率。
基于延迟的Cross-DC设计
针对上述算法的局限性,我们提出了一种名为 IDCC的基于延迟的拥塞控制方案。该算法采用乘法递增和乘法递减(MIMD)机制来调整主机的拥塞窗口。IDCC 使用 PID 算法来控制数据中心(DC)和广域网(WAN)的排队深度。这是通过获取DC内部交换机的队列长度和 WAN的RTT 实现的。我们用INT 获取队列长度信号来解决DC内部的拥塞问题,满足DC内部浅缓存的严格队列要求。另一方面,RTT 负责广域网的带宽利用,因为广域网可能不支持 INT。IDCC 的伪代码如图3所示。

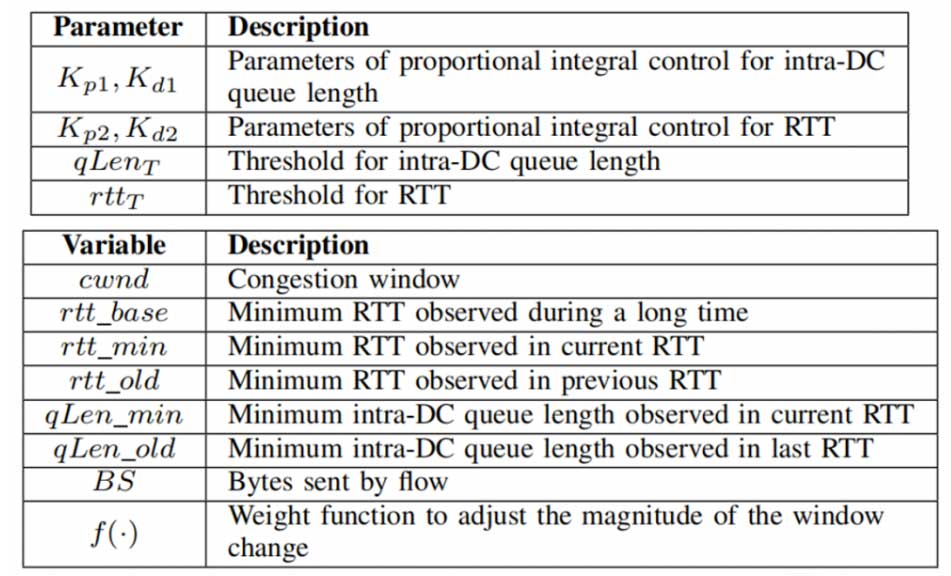
为了保证算法的稳定性,即能够保证队列长度稳定在一定的范围,我们分别为INT携带的队列长度信号以及ACK携带的RTT信号设计了两个PID控制器,PID控制如图3的算法的第6和7行。由于拥塞位置可能发生在DC内部或者WAN中,因此我们选择两者拥塞程度最严重的位置进行调整,即算法中的第8到第12行。
评估
我们在仿真平台 ns-3上构建了混合流量场景,并进行了大规模仿真,以评估 IDCC 的性能。
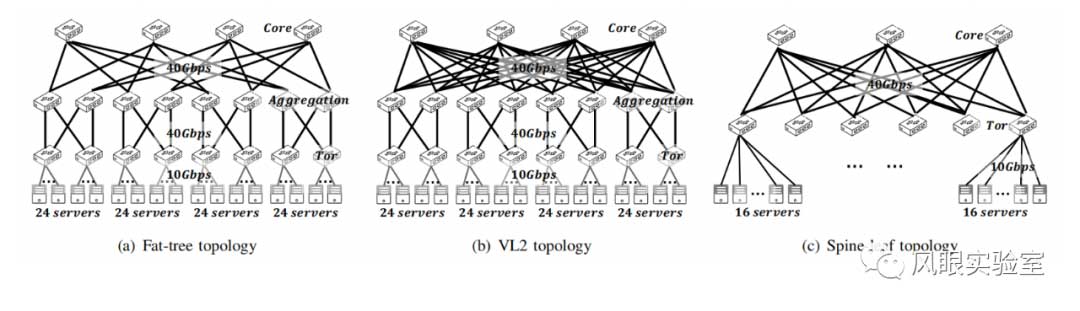
网络拓扑结构:我们分别在 Fat-tree、VL2和 spineleaf拓扑的数据中心进行了模拟。拓扑结构如图5所示。所有服务器到Tor 交换机的链路带宽为 10 Gbps。核心交换机到汇聚交换机以及汇聚交换机到 Tor 交换机的链路容量均为 40 Gbps。所有链路的延迟均为 1us,因此 DC 内的最大 RTT 为 12us。所有交换机的每个端口缓冲区均为 1MB。同时,为了模拟 DC 之间的流量,们设置了两个通过广域网链路连接的相同结构的 DCN。我们设置 DCN 之间的广域网链路延迟为 50ms,链路容量为500Mbps。
工作负载:我们根据网络搜索工作负载和 facebook hadoop集群的工作负载中的实际流量分布生成流量。以 6:1 的比例生成DC内和DC间的流量。
基准和衡量标准:我们将IDCC 与 Annulus、Gemini、DCBR和 L2BR 进行了比较。我们的评估指标包括DC内部流量的平均 FCT和DC之间流量的平均速率。
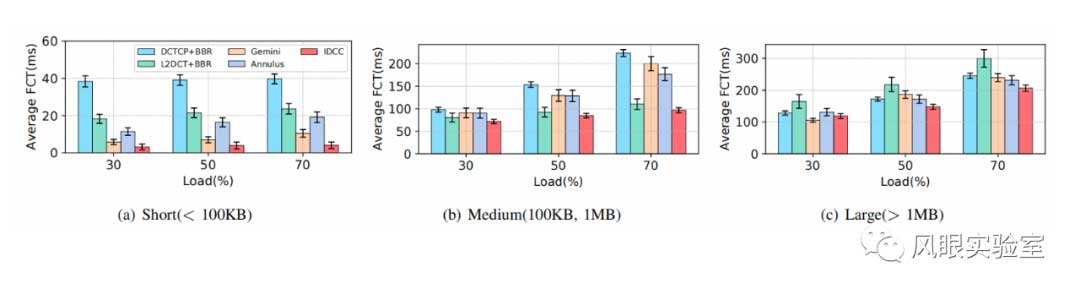
大规模模拟:我们在三种拓扑结构中进行了模拟,并合并了最终结果。图6显示了负载从 30%到 70%的网络携索工作负载在不同方案下DC内部流量的平均 FCT,我们将结果分为短流[0-100KB]、中流[100KB-1MB]和长流[>1MB]。
与 DCBR、L2BR、Gemini和 Annulus 相比,IDCC 对短流的 FCT 改进最为明显,网络搜索工作负载的FCT 分别降低了12、6、1.9和3.6 倍。 这是因为 IDCC 对短流量的性能进行了优化。当 DC 内发生拥塞时,长流量会向短流量让出带宽,从而加速短流量的完成。
小结
数据中心内流量和数据中心间流量的需求和特点有很大不同。这两类流量共享数据中心基础设施,它们之间的相互作用会导致性能下降。我们注意到,现有的拥塞控制组合方案过于激进,无法保证DC内流量的低延迟。混合方案无法平衡DC内和WAN的拥塞程度,导致WAN带宽利用率不足。为了提高短流的性能和系统的稳定性,我们提出了基于延迟的拥塞控制机制IDCC。IDCC 从 INT 中获得队列深度,以调整DC间流量的行为,从而降低DC内流量的延迟。此外,我们还使用 RTT 信号来保证广域网链路的带宽利用率。实验结果表明IDCC能极大改善DC内的短流性能和WAN的带宽利用率。
参考文献
[1] A. Saeed, V. Gupta, P. Goyal, M. Sharif, R. Pan, M. Ammar, E. Zegura,K. Jang, M. Alizadeh, A. Kabbani et al., “Annulus: A dual congestion control loop for datacenter and wan traffic aggregates,” in Proceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the applications, technologies, architectures, and protocols for computer communication, 2020, pp. 735–749.
[2] G. Zeng, W. Bai, G. Chen, K. Chen, D. Han, Y. Zhu, and L. Cui, “Congestion control for cross-datacenter networks,” IEEE/ACM Transactions on Networking, 2022.
[3] M. Alizadeh, A. Greenberg, D. A. Maltz, J. Padhye, P. Patel, B. Prabhakar, S. Sengupta, and M. Sridharan, “Data center tcp (dctcp),” in Proceedings of the ACM SIGCOMM 2010 Conference, 2010, pp. 63–74.
[4] A. Roy, H. Zeng, J. Bagga, G. Porter, and A. C. Snoeren, “Inside the social network’s (datacenter) network,” in Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, 2015, pp. 123–137.
[5] N. Cardwell, Y. Cheng, C. S. Gunn, S. H. Yeganeh, and V. Jacobson, “Bbr: Congestion-based congestion control: Measuring bottleneck bandwidth and round-trip propagation time,” Queue, vol. 14, no. 5, pp. 20–53, 2016.
[6] S. Ha, I. Rhee, and L. Xu, “Cubic: a new tcp-friendly high-speed tcp variant,” ACM SIGOPS operating systems review, vol. 42, no. 5, pp. 64–74, 2008.
[7] S. Zou, J. Huang, J. Liu, T. Zhang, N. Jiang, and J. Wang, “GTCP: Hybrid Congestion Control for Cross-Datacenter Networks,” in 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), Jul. 2021, pp. 932–942.
作者:风眼实验室
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
