
Labs 导读:在开发图形渲染应用时,渲染性能优化是一个绕不开的主题,开发者往往遵循一些优化准则来构建自己的应用程序,包括数据合并、模型减面、减少采样次数、减少不必要渲染等。本文结合现代GPU架构及逻辑管线执行,简单阐述这些性能优化背后的原理。
作者:周明洋
单位:中国移动智慧家庭运营中心成都业务支持中心
原文:https://mp.weixin.qq.com/s/ZrTm5qTr1jqApB5dkgTeug
Part 01 现代GPU架构
早期GPU设计遵循硬件渲染管线理念,管线的每个功能阶段都有对应的硬件单元实现,这种设计导致整个渲染管线是固定功能的,开发人员无法做更多地更改,只能通过图形API实现相应的功能,例如早期OpenGL提供图形接口实现光照的设置。为服务更广泛的科技业务需求,现代GPU设计则更加灵活,遵循逻辑渲染管线的理念,引入可编程部分,硬件单元得以复用以实现管线的每个功能阶段。本文以抽象的Fermi架构来阐述现代GPU结构,如下图所示。
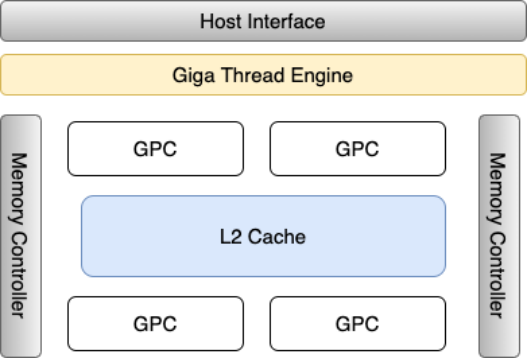
主机接口(Host Interface)是GPU与CPU沟通的桥梁,用于进行数据和指令的交换。大规模线程引擎(Giga Thread Engin)扮演大管家的角色,管理GPU中执行的所有工作,包括线程块与线程束调用,并行度调整等。核心工作部分则是图形处理集群(Graphics Processing Cluster),即GPC,负载执行图形渲染任务,一个GPU的内部可以有多个GPC,单个GPC内部抽象结构如下图所示。
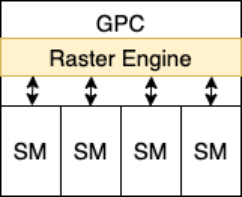
GPC中主要包含一个光栅化引擎(Raster Engine)和多个流式多处理器(Streaming Multiprocess, 即SM)。Raster Engine主要负责将图元数据转换为屏幕上的像素,SM主要用于执行开发人员编写的着色器代码,内部包含多个数学运算核心。SM的抽象结构如下图所示。
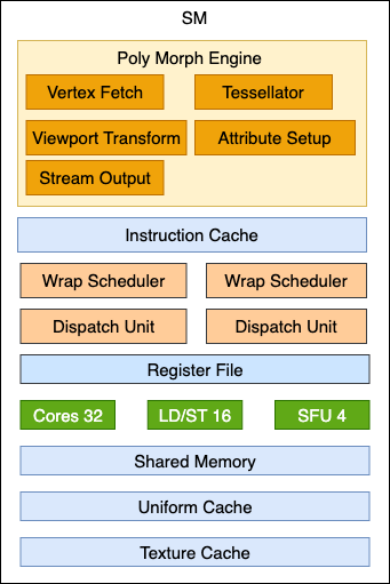
几何处理引擎(Poly Morph Engine)主要进行几何处理和数据准备工作,在下述逻辑管线执行部分将介绍其部分功能。SM中缓存主要包括:
- 指令缓存(Instruction Cache),用于存储指令及指令所需的数据。
- 共享内存(Shared Memory),用于管线不同功能阶段数据的存储与传递。
- Uniform变量缓存(Unifrom Cache),用于存储共享的Uniform变量数据,以便多个执行线程高效访问这些数据。
- 纹理缓存(Texture Cache),用于缓存纹理数据,提高访问纹理数据的速度。
SM中的计算执行部分主要包含线程束调度(Wrap Scheduler),分发单元(Dispatch Unit)以及32个计算核心(Core)。Wrap Scheduler负责线程束(wrap)的调度,一个wrap包含32个线程,这些线程的指令被提交给分发单元(Dispatch Unit),由Dispatch Unit分发给各个Core执行,指令以锁步(lock-step)方式执行,即一个wrap中所有线程按照相同的控制流路径同时执行一个指令(单指令多线程)。
Part 02 逻辑管线执行
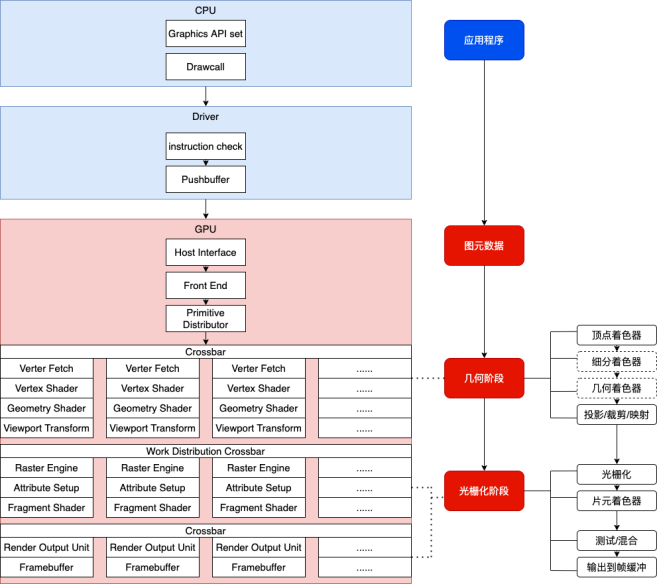
上图是简化的逻辑管线执行过程,可分为CPU和GPU阶段。在CPU部分,开发者利用图形API构建应用程序,通过drawcall发出指令,这些指令会被推送给驱动,驱动程序首先会进行指令合法性检测,然后将其存储到Push Buffer中。
在GPU部分,接受到绘制请求后,GPU中的Host Interface会接受到这些指令数据,并交由Front End进行分析处理,处理后的数据会发送给图元分发器(Primitive Distributor),Primitive Distributor会把顶点数据组织成图元数据形式,并将这些数据按批次发送给各个GPC。
数据和指令的转送则是通过交叉栅(Cross Bar)进行的。首先进行几何阶段任务,上述SM中的Poly Morph Engine会执行Vertex Fetch功能,即获取顶点数据,然后依次执行顶点着色器代码(Vertex Shader)和几何着色器代码(Geometry Shader),这一过程则是上述提到线程指令在计算核心中以lock-step方式进行,最后Poly Morph Engine会进行视口变化(View Transform),为光栅化做准备,丢弃不在视口范围内的顶点。
光栅化阶段主要进行光栅化、片段着色器(Fragment Shader)执行以及逐片元处理。Raster Engine完成对视口内顶点数据的光栅化,Poly Morph Engine会负责属性设置(Attribute Setup),以方便光栅化时属性数据的插值采用片段着色器友好格式。Fragment Shader执行与上述Vertex Shader执行一样,唯一不同是Vertex Shader是按顶点并行进行的,而Fragment Shader是按像素并行进行的。Fragment Shader产生的结果通过Cross Bar传给渲染输出单元(Render Output Unit),Render Output Unit会以原子方式进行逐片元处理,包括模版测试、深度测试、像素混合等。最终生成的结果被存储在帧缓冲(Framebuffer)中。
Part 03 性能优化
在开发图形应用时,开发者往往需要遵从一些渲染性能优化原则编写自己的程序。结合上述GPU架构与逻辑管线执行流程,依次阐述其中的原理。
- 减少drawcall
从上述的流程执行可以看出,渲染的过程是复杂的,渲一个三角行与渲染多个三角行执行的过程是一致的,为了发挥GPU强大的并行能力,需要开发者在每次绘制时,向GPU发送足够的渲染数据,以便最大限度的利用GPU。其次,drawcall并不是直接绘制,而是将指令与数据发送给GPU,过多的drawcall会增加CPU与GPU的通信开销。上述PushBuffer可以减少CPU与GPU的通信开销,CPU写入指令,当PushBuffer中填充完成,CPU将整个PushBuffer一次性发送给GPU,减少CPU与GPU间的通信次数。实践中,可以采用网格数据合并、实例绘制等方式减少drawcall调用。
- 减少纹理采样次数
采样是指从纹理中获取像素颜色的过程。纹理采样需要从GPU内存中读取纹理数据,这是一个相对较慢的过程,读取跟不上运算速度从而导致延迟。在GPU中,为了处理由于数据没准备好而引起的线程执行延迟,Wrap调度器会挂起当前延迟的Wrap,选择可立即执行的Wrap执行。在SM中存在Texture Cache,以缓存纹理数据,提高采样效率。在实践中,可通过多重采样(multisample)实现反走样,但由于采样次数的增加,渲染性能也会下降。
- 减少模型顶点数
顶点数据的处理主要在几何阶段,Vertex Shader的执行是按照顶点并行的,计算核心的个数是固定,顶点越少,所需执行线程的越少,完成所有线程执行花费的时间也就越少。在实践中,可以采用低精度模型结合法向贴图的模型替代高精度模型,也可使用LOD技术动态切换不同精度的模型。
- 避免着色器中的分支语句
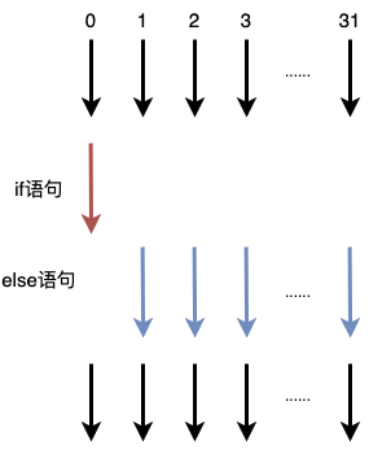
着色器代码指令是按照lock-step方式执行的,假设着色器代码中存在if-else语句,在一个Wrap中有32个线程,其中只有1个线程条件为真执行if语句,剩下31个线程均执行else语句,在执行if语句时,剩下31个线程会等待,当31个线程执行else语句时,执行if的线程会等待,即相当于每个线程if与else语句均执行了一次,整体执行流程如下图所示。在实践中,可以利用着色器提供的step函数来规避分支语句的编写。
- 减少不必要渲染
实践中运用较多的技术是遮挡剔除与Early z。遮挡剔除一般是在CPU端判断物体是否在场景的虚拟视线范围内,以剔除不在视线范围内的物体,减少不必要的渲染。Early z则是现代GPU硬件所支持的优化技术,当光栅化结束,Raster Engine会进行Early z,比较片元深度值,剔除那些在深度方向被遮挡的片元,以减少后续片元着色器的工作量,Early z类似于提前进行了ROP阶段的深度测试。
Part 04 结束语
本文结合架构与管线执行简单阐述了一些性能优化准则的原理,了解现代GPU架构与逻辑管线执行有利于开发者构建高性能应用。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
